 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTail-Aware Data Augmentation for Long-Tail Sequential Recommendation
Jan 16, 2026Sequential recommendation (SR) learns user preferences based on their historical interaction sequences and provides personalized suggestions. In real-world scenarios, most users can only interact with a handful of items, while the majority of items are seldom consumed. This pervasive long-tail challenge limits the model's ability to learn user preferences. Despite previous efforts to enrich tail items/users with knowledge from head parts or improve tail learning through additional contextual information, they still face the following issues: 1) They struggle to improve the situation where interactions of tail users/items are scarce, leading to incomplete preferences learning for the tail parts. 2) Existing methods often degrade overall or head parts performance when improving accuracy for tail users/items, thereby harming the user experience. We propose Tail-Aware Data Augmentation (TADA) for long-tail sequential recommendation, which enhances the interaction frequency for tail items/users while maintaining head performance, thereby promoting the model's learning capabilities for the tail. Specifically, we first capture the co-occurrence and correlation among low-popularity items by a linear model. Building upon this, we design two tail-aware augmentation operators, T-Substitute and T-Insert. The former replaces the head item with a relevant item, while the latter utilizes co-occurrence relationships to extend the original sequence by incorporating both head and tail items. The augmented and original sequences are mixed at the representation level to preserve preference knowledge. We further extend the mix operation across different tail-user sequences and augmented sequences to generate richer augmented samples, thereby improving tail performance. Comprehensive experiments demonstrate the superiority of our method. The codes are provided at https://github.com/KingGugu/TADA.
Causal Negative Sampling via Diffusion Model for Out-of-Distribution Recommendation
Aug 10, 2025



Heuristic negative sampling enhances recommendation performance by selecting negative samples of varying hardness levels from predefined candidate pools to guide the model toward learning more accurate decision boundaries. However, our empirical and theoretical analyses reveal that unobserved environmental confounders (e.g., exposure or popularity biases) in candidate pools may cause heuristic sampling methods to introduce false hard negatives (FHNS). These misleading samples can encourage the model to learn spurious correlations induced by such confounders, ultimately compromising its generalization ability under distribution shifts. To address this issue, we propose a novel method named Causal Negative Sampling via Diffusion (CNSDiff). By synthesizing negative samples in the latent space via a conditional diffusion process, CNSDiff avoids the bias introduced by predefined candidate pools and thus reduces the likelihood of generating FHNS. Moreover, it incorporates a causal regularization term to explicitly mitigate the influence of environmental confounders during the negative sampling process, leading to robust negatives that promote out-of-distribution (OOD) generalization. Comprehensive experiments under four representative distribution shift scenarios demonstrate that CNSDiff achieves an average improvement of 13.96% across all evaluation metrics compared to state-of-the-art baselines, verifying its effectiveness and robustness in OOD recommendation tasks.
Data Augmentation as Free Lunch: Exploring the Test-Time Augmentation for Sequential Recommendation
Apr 07, 2025Data augmentation has become a promising method of mitigating data sparsity in sequential recommendation. Existing methods generate new yet effective data during model training to improve performance. However, deploying them requires retraining, architecture modification, or introducing additional learnable parameters. The above steps are time-consuming and costly for well-trained models, especially when the model scale becomes large. In this work, we explore the test-time augmentation (TTA) for sequential recommendation, which augments the inputs during the model inference and then aggregates the model's predictions for augmented data to improve final accuracy. It avoids significant time and cost overhead from loss calculation and backward propagation. We first experimentally disclose the potential of existing augmentation operators for TTA and find that the Mask and Substitute consistently achieve better performance. Further analysis reveals that these two operators are effective because they retain the original sequential pattern while adding appropriate perturbations. Meanwhile, we argue that these two operators still face time-consuming item selection or interference information from mask tokens. Based on the analysis and limitations, we present TNoise and TMask. The former injects uniform noise into the original representation, avoiding the computational overhead of item selection. The latter blocks mask token from participating in model calculations or directly removes interactions that should have been replaced with mask tokens. Comprehensive experiments demonstrate the effectiveness, efficiency, and generalizability of our method. We provide an anonymous implementation at https://github.com/KingGugu/TTA4SR.
Self-supervised Hierarchical Representation for Medication Recommendation
Nov 05, 2024



Medication recommender is to suggest appropriate medication combinations based on a patient's health history, e.g., diagnoses and procedures. Existing works represent different diagnoses/procedures well separated by one-hot encodings. However, they ignore the latent hierarchical structures of these medical terms, undermining the generalization performance of the model. For example, "Respiratory Diseases", "Chronic Respiratory Diseases" and "Chronic Bronchiti" have a hierarchical relationship, progressing from general to specific. To address this issue, we propose a novel hierarchical encoder named HIER to hierarchically represent diagnoses and procedures, which is based on standard medical codes and compatible with any existing methods. Specifically, the proposed method learns relation embedding with a self-supervised objective for incorporating the neighbor hierarchical structure. Additionally, we develop the position encoding to explicitly introduce global hierarchical position. Extensive experiments demonstrate significant and consistent improvements in recommendation accuracy across four baselines and two real-world clinical datasets.
CoRA: Collaborative Information Perception by Large Language Model's Weights for Recommendation
Aug 20, 2024



Involving collaborative information in Large Language Models (LLMs) is a promising technique for adapting LLMs for recommendation. Existing methods achieve this by concatenating collaborative features with text tokens into a unified sequence input and then fine-tuning to align these features with LLM's input space. Although effective, in this work, we identify two limitations when adapting LLMs to recommendation tasks, which hinder the integration of general knowledge and collaborative information, resulting in sub-optimal recommendation performance. (1) Fine-tuning LLM with recommendation data can undermine its inherent world knowledge and fundamental competencies, which are crucial for interpreting and inferring recommendation text. (2) Incorporating collaborative features into textual prompts disrupts the semantics of the original prompts, preventing LLM from generating appropriate outputs. In this paper, we propose a new paradigm, CoRA (an acronym for Collaborative LoRA), with a collaborative weights generator. Rather than input space alignment, this method aligns collaborative information with LLM's parameter space, representing them as incremental weights to update LLM's output. This way, LLM perceives collaborative information without altering its general knowledge and text inference capabilities. Specifically, we employ a collaborative filtering model to extract user and item embeddings, converting them into collaborative weights with low-rank properties through the collaborative weights generator. We then merge the collaborative weights into LLM's weights, enabling LLM to perceive the collaborative signals and generate personalized recommendations without fine-tuning or extra collaborative tokens in prompts. Extensive experiments confirm that CoRA effectively integrates collaborative information into LLM, enhancing recommendation performance.
Towards Unified Modeling for Positive and Negative Preferences in Sign-Aware Recommendation
Mar 13, 2024



Recently, sign-aware graph recommendation has drawn much attention as it will learn users' negative preferences besides positive ones from both positive and negative interactions (i.e., links in a graph) with items. To accommodate the different semantics of negative and positive links, existing works utilize two independent encoders to model users' positive and negative preferences, respectively. However, these approaches cannot learn the negative preferences from high-order heterogeneous interactions between users and items formed by multiple links with different signs, resulting in inaccurate and incomplete negative user preferences. To cope with these intractable issues, we propose a novel \textbf{L}ight \textbf{S}igned \textbf{G}raph Convolution Network specifically for \textbf{Rec}ommendation (\textbf{LSGRec}), which adopts a unified modeling approach to simultaneously model high-order users' positive and negative preferences on a signed user-item interaction graph. Specifically, for the negative preferences within high-order heterogeneous interactions, first-order negative preferences are captured by the negative links, while high-order negative preferences are propagated along positive edges. Then, recommendation results are generated based on positive preferences and optimized with negative ones. Finally, we train representations of users and items through different auxiliary tasks. Extensive experiments on three real-world datasets demonstrate that our method outperforms existing baselines regarding performance and computational efficiency. Our code is available at \url{https://anonymous.4open.science/r/LSGRec-BB95}.
Repeated Padding as Data Augmentation for Sequential Recommendation
Mar 11, 2024



Sequential recommendation aims to provide users with personalized suggestions based on their historical interactions. When training sequential models, padding is a widely adopted technique for two main reasons: 1) The vast majority of models can only handle fixed-length sequences; 2) Batching-based training needs to ensure that the sequences in each batch have the same length. The special value \emph{0} is usually used as the padding content, which does not contain the actual information and is ignored in the model calculations. This common-sense padding strategy leads us to a problem that has never been explored before: \emph{Can we fully utilize this idle input space by padding other content to further improve model performance and training efficiency?} In this paper, we propose a simple yet effective padding method called \textbf{Rep}eated \textbf{Pad}ding (\textbf{RepPad}). Specifically, we use the original interaction sequences as the padding content and fill it to the padding positions during model training. This operation can be performed a finite number of times or repeated until the input sequences' length reaches the maximum limit. Our RepPad can be viewed as a sequence-level data augmentation strategy. Unlike most existing works, our method contains no trainable parameters or hyperparameters and is a plug-and-play data augmentation operation. Extensive experiments on various categories of sequential models and five real-world datasets demonstrate the effectiveness and efficiency of our approach. The average recommendation performance improvement is up to 60.3\% on GRU4Rec and 24.3\% on SASRec. We also provide in-depth analysis and explanation of what makes RepPad effective from multiple perspectives. The source code will be released to ensure the reproducibility of our experiments.
ID Embedding as Subtle Features of Content and Structure for Multimodal Recommendation
Nov 10, 2023


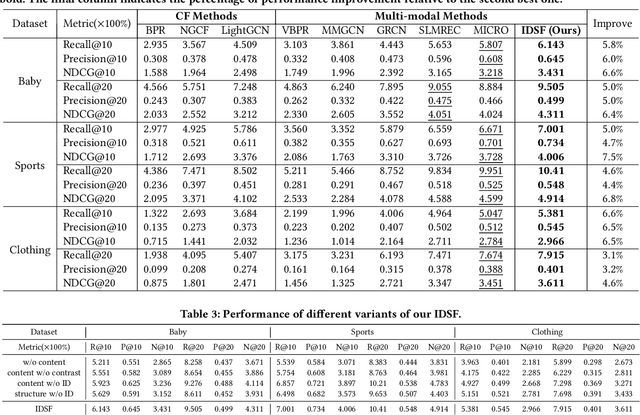
Multimodal recommendation aims to model user and item representations comprehensively with the involvement of multimedia content for effective recommendations. Existing research has shown that it is beneficial for recommendation performance to combine (user- and item-) ID embeddings with multimodal salient features, indicating the value of IDs. However, there is a lack of a thorough analysis of the ID embeddings in terms of feature semantics in the literature. In this paper, we revisit the value of ID embeddings for multimodal recommendation and conduct a thorough study regarding its semantics, which we recognize as subtle features of content and structures. Then, we propose a novel recommendation model by incorporating ID embeddings to enhance the semantic features of both content and structures. Specifically, we put forward a hierarchical attention mechanism to incorporate ID embeddings in modality fusing, coupled with contrastive learning, to enhance content representations. Meanwhile, we propose a lightweight graph convolutional network for each modality to amalgamate neighborhood and ID embeddings for improving structural representations. Finally, the content and structure representations are combined to form the ultimate item embedding for recommendation. Extensive experiments on three real-world datasets (Baby, Sports, and Clothing) demonstrate the superiority of our method over state-of-the-art multimodal recommendation methods and the effectiveness of fine-grained ID embeddings.
Uniform Sequence Better: Time Interval Aware Data Augmentation for Sequential Recommendation
Dec 16, 2022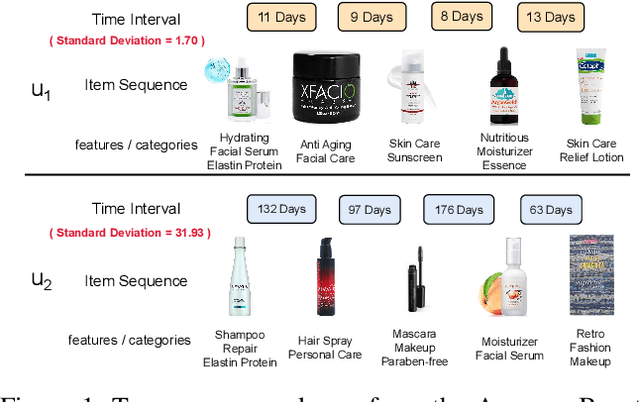
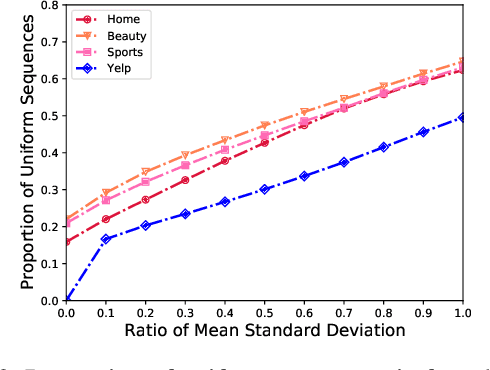
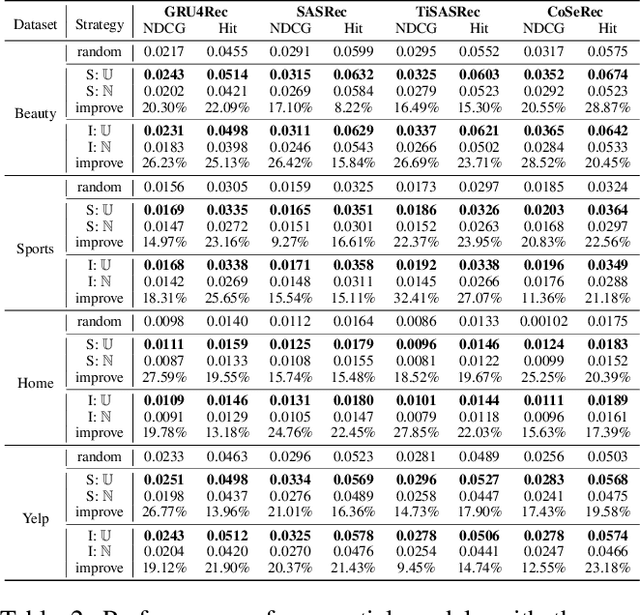
Sequential recommendation is an important task to predict the next-item to access based on a sequence of interacted items. Most existing works learn user preference as the transition pattern from the previous item to the next one, ignoring the time interval between these two items. However, we observe that the time interval in a sequence may vary significantly different, and thus result in the ineffectiveness of user modeling due to the issue of \emph{preference drift}. In fact, we conducted an empirical study to validate this observation, and found that a sequence with uniformly distributed time interval (denoted as uniform sequence) is more beneficial for performance improvement than that with greatly varying time interval. Therefore, we propose to augment sequence data from the perspective of time interval, which is not studied in the literature. Specifically, we design five operators (Ti-Crop, Ti-Reorder, Ti-Mask, Ti-Substitute, Ti-Insert) to transform the original non-uniform sequence to uniform sequence with the consideration of variance of time intervals. Then, we devise a control strategy to execute data augmentation on item sequences in different lengths. Finally, we implement these improvements on a state-of-the-art model CoSeRec and validate our approach on four real datasets. The experimental results show that our approach reaches significantly better performance than the other 11 competing methods. Our implementation is available: https://github.com/KingGugu/TiCoSeRec.