 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECHO: Entropy-Confidence Hybrid Optimization for Test-Time Reinforcement Learning
Feb 02, 2026Test-time reinforcement learning generates multiple candidate answers via repeated rollouts and performs online updates using pseudo-labels constructed by majority voting. To reduce overhead and improve exploration, prior work introduces tree structured rollouts, which share reasoning prefixes and branch at key nodes to improve sampling efficiency. However, this paradigm still faces two challenges: (1) high entropy branching can trigger rollout collapse, where the branching budget concentrates on a few trajectories with consecutive high-entropy segments, rapidly reducing the number of effective branches; (2) early pseudo-labels are noisy and biased, which can induce self-reinforcing overfitting, causing the policy to sharpen prematurely and suppress exploration. To address these issues, we propose Entropy Confidence Hybrid Group Relative Policy Optimization (ECHO). During rollout, ECHO jointly leverages local entropy and group level confidence to adaptively control branch width, and further introduces online confidence-based pruning to terminate persistently low confidence branches, avoiding high entropy traps and mitigating collapse. During policy updates, ECHO employs confidence adaptive clipping and an entropy confidence hybrid advantage shaping approach to enhance training robustness and mitigate early stage bias. Experiments demonstrate that ECHO achieves consistent gains on multiple mathematical and visual reasoning benchmarks, and generalizes more effectively under a limited rollout budget.
Text as a Universal Interface for Transferable Personalization
Jan 08, 2026We study the problem of personalization in large language models (LLMs). Prior work predominantly represents user preferences as implicit, model-specific vectors or parameters, yielding opaque ``black-box'' profiles that are difficult to interpret and transfer across models and tasks. In contrast, we advocate natural language as a universal, model- and task-agnostic interface for preference representation. The formulation leads to interpretable and reusable preference descriptions, while naturally supporting continual evolution as new interactions are observed. To learn such representations, we introduce a two-stage training framework that combines supervised fine-tuning on high-quality synthesized data with reinforcement learning to optimize long-term utility and cross-task transferability. Based on this framework, we develop AlignXplore+, a universal preference reasoning model that generates textual preference summaries. Experiments on nine benchmarks show that our 8B model achieves state-of-the-art performanc -- outperforming substantially larger open-source models -- while exhibiting strong transferability across tasks, model families, and interaction formats.
Prior-AttUNet: Retinal OCT Fluid Segmentation Based on Normal Anatomical Priors and Attention Gating
Dec 25, 2025Accurate segmentation of macular edema, a hallmark pathological feature in vision-threatening conditions such as age-related macular degeneration and diabetic macular edema, is essential for clinical diagnosis and management. To overcome the challenges of segmenting fluid regions in optical coherence tomography (OCT) images-notably ambiguous boundaries and cross-device heterogeneity-this study introduces Prior-AttUNet, a segmentation model augmented with generative anatomical priors. The framework adopts a hybrid dual-path architecture that integrates a generative prior pathway with a segmentation network. A variational autoencoder supplies multi-scale normative anatomical priors, while the segmentation backbone incorporates densely connected blocks and spatial pyramid pooling modules to capture richer contextual information. Additionally, a novel triple-attention mechanism, guided by anatomical priors, dynamically modulates feature importance across decoding stages, substantially enhancing boundary delineation. Evaluated on the public RETOUCH benchmark, Prior-AttUNet achieves excellent performance across three OCT imaging devices (Cirrus, Spectralis, and Topcon), with mean Dice similarity coefficients of 93.93%, 95.18%, and 93.47%, respectively. The model maintains a low computational cost of 0.37 TFLOPs, striking an effective balance between segmentation precision and inference efficiency. These results demonstrate its potential as a reliable tool for automated clinical analysis.
DGRO: Enhancing LLM Reasoning via Exploration-Exploitation Control and Reward Variance Management
May 19, 2025
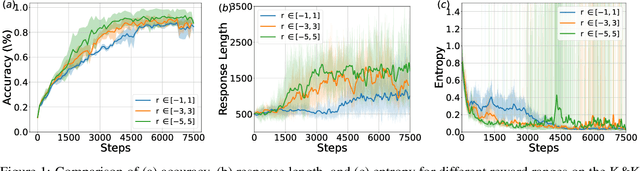
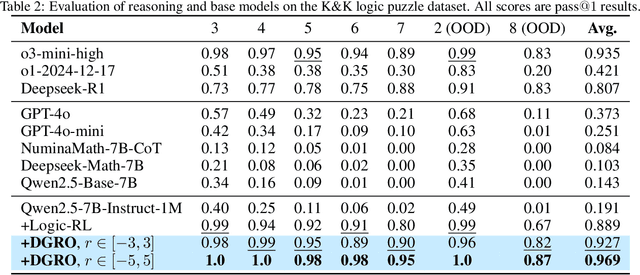
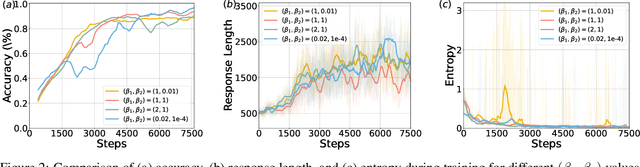
Inference scaling further accelerates Large Language Models (LLMs) toward Artificial General Intelligence (AGI), with large-scale Reinforcement Learning (RL) to unleash long Chain-of-Thought reasoning. Most contemporary reasoning approaches usually rely on handcrafted rule-based reward functions. However, the tarde-offs of exploration and exploitation in RL algorithms involves multiple complex considerations, and the theoretical and empirical impacts of manually designed reward functions remain insufficiently explored. In this paper, we propose Decoupled Group Reward Optimization (DGRO), a general RL algorithm for LLM reasoning. On the one hand, DGRO decouples the traditional regularization coefficient into two independent hyperparameters: one scales the policy gradient term, and the other regulates the distance from the sampling policy. This decoupling not only enables precise control over balancing exploration and exploitation, but also can be seamlessly extended to Online Policy Mirror Descent (OPMD) algorithms in Kimi k1.5 and Direct Reward Optimization. On the other hand, we observe that reward variance significantly affects both convergence speed and final model performance. We conduct both theoretical analysis and extensive empirical validation to assess DGRO, including a detailed ablation study that investigates its performance and optimization dynamics. Experimental results show that DGRO achieves state-of-the-art performance on the Logic dataset with an average accuracy of 96.9\%, and demonstrates strong generalization across mathematical benchmarks.
RAGAR: Retrieval Augment Personalized Image Generation Guided by Recommendation
May 03, 2025Personalized image generation is crucial for improving the user experience, as it renders reference images into preferred ones according to user visual preferences. Although effective, existing methods face two main issues. First, existing methods treat all items in the user historical sequence equally when extracting user preferences, overlooking the varying semantic similarities between historical items and the reference item. Disproportionately high weights for low-similarity items distort users' visual preferences for the reference item. Second, existing methods heavily rely on consistency between generated and reference images to optimize the generation, which leads to underfitting user preferences and hinders personalization. To address these issues, we propose Retrieval Augment Personalized Image GenerAtion guided by Recommendation (RAGAR). Our approach uses a retrieval mechanism to assign different weights to historical items according to their similarities to the reference item, thereby extracting more refined users' visual preferences for the reference item. Then we introduce a novel rank task based on the multi-modal ranking model to optimize the personalization of the generated images instead of forcing depend on consistency. Extensive experiments and human evaluations on three real-world datasets demonstrate that RAGAR achieves significant improvements in both personalization and semantic metrics compared to five baselines.
NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 19, 2025



This paper reviews the NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images. This challenge received a wide range of impressive solutions, which are developed and evaluated using our collected real-world Raindrop Clarity dataset. Unlike existing deraining datasets, our Raindrop Clarity dataset is more diverse and challenging in degradation types and contents, which includes day raindrop-focused, day background-focused, night raindrop-focused, and night background-focused degradations. This dataset is divided into three subsets for competition: 14,139 images for training, 240 images for validation, and 731 images for testing. The primary objective of this challenge is to establish a new and powerful benchmark for the task of removing raindrops under varying lighting and focus conditions. There are a total of 361 participants in the competition, and 32 teams submitting valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the Raindrop Clarity dataset. The project can be found at https://lixinustc.github.io/CVPR-NTIRE2025-RainDrop-Competition.github.io/.
Can LLM-Driven Hard Negative Sampling Empower Collaborative Filtering? Findings and Potentials
Apr 07, 2025Hard negative samples can accelerate model convergence and optimize decision boundaries, which is key to improving the performance of recommender systems. Although large language models (LLMs) possess strong semantic understanding and generation capabilities, systematic research has not yet been conducted on how to generate hard negative samples effectively. To fill this gap, this paper introduces the concept of Semantic Negative Sampling and exploreshow to optimize LLMs for high-quality, hard negative sampling. Specifically, we design an experimental pipeline that includes three main modules, profile generation, semantic negative sampling, and semantic alignment, to verify the potential of LLM-driven hard negative sampling in enhancing the accuracy of collaborative filtering (CF). Experimental results indicate that hard negative samples generated based on LLMs, when semantically aligned and integrated into CF, can significantly improve CF performance, although there is still a certain gap compared to traditional negative sampling methods. Further analysis reveals that this gap primarily arises from two major challenges: noisy samples and lack of behavioral constraints. To address these challenges, we propose a framework called HNLMRec, based on fine-tuning LLMs supervised by collaborative signals. Experimental results show that this framework outperforms traditional negative sampling and other LLM-driven recommendation methods across multiple datasets, providing new solutions for empowering traditional RS with LLMs. Additionally, we validate the excellent generalization ability of the LLM-based semantic negative sampling method on new datasets, demonstrating its potential in alleviating issues such as data sparsity, popularity bias, and the problem of false hard negative samples. Our implementation code is available at https://github.com/user683/HNLMRec.
Data Augmentation as Free Lunch: Exploring the Test-Time Augmentation for Sequential Recommendation
Apr 07, 2025Data augmentation has become a promising method of mitigating data sparsity in sequential recommendation. Existing methods generate new yet effective data during model training to improve performance. However, deploying them requires retraining, architecture modification, or introducing additional learnable parameters. The above steps are time-consuming and costly for well-trained models, especially when the model scale becomes large. In this work, we explore the test-time augmentation (TTA) for sequential recommendation, which augments the inputs during the model inference and then aggregates the model's predictions for augmented data to improve final accuracy. It avoids significant time and cost overhead from loss calculation and backward propagation. We first experimentally disclose the potential of existing augmentation operators for TTA and find that the Mask and Substitute consistently achieve better performance. Further analysis reveals that these two operators are effective because they retain the original sequential pattern while adding appropriate perturbations. Meanwhile, we argue that these two operators still face time-consuming item selection or interference information from mask tokens. Based on the analysis and limitations, we present TNoise and TMask. The former injects uniform noise into the original representation, avoiding the computational overhead of item selection. The latter blocks mask token from participating in model calculations or directly removes interactions that should have been replaced with mask tokens. Comprehensive experiments demonstrate the effectiveness, efficiency, and generalizability of our method. We provide an anonymous implementation at https://github.com/KingGugu/TTA4SR.
Trust Region Preference Approximation: A simple and stable reinforcement learning algorithm for LLM reasoning
Apr 06, 2025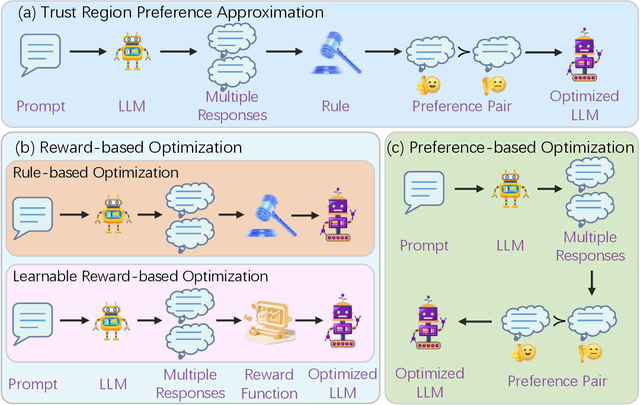
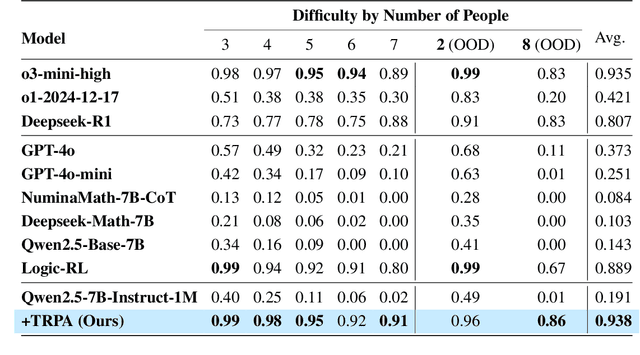
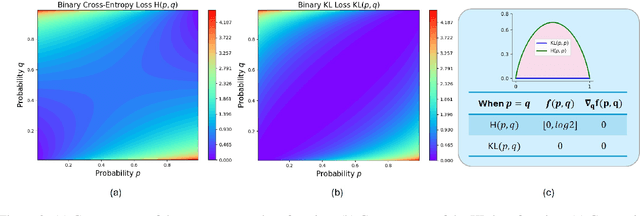
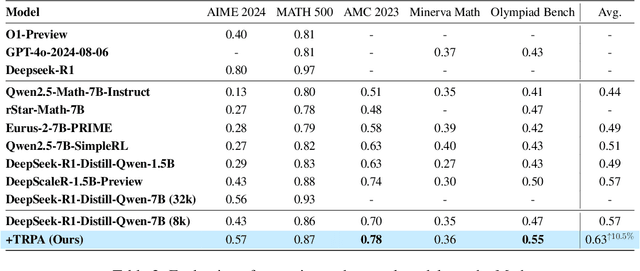
Recently, Large Language Models (LLMs) have rapidly evolved, approaching Artificial General Intelligence (AGI) while benefiting from large-scale reinforcement learning to enhance Human Alignment (HA) and Reasoning. Recent reward-based optimization algorithms, such as Proximal Policy Optimization (PPO) and Group Relative Policy Optimization (GRPO) have achieved significant performance on reasoning tasks, whereas preference-based optimization algorithms such as Direct Preference Optimization (DPO) significantly improve the performance of LLMs on human alignment. However, despite the strong performance of reward-based optimization methods in alignment tasks , they remain vulnerable to reward hacking. Furthermore, preference-based algorithms (such as Online DPO) haven't yet matched the performance of reward-based optimization algorithms (like PPO) on reasoning tasks, making their exploration in this specific area still a worthwhile pursuit. Motivated by these challenges, we propose the Trust Region Preference Approximation (TRPA) algorithm, which integrates rule-based optimization with preference-based optimization for reasoning tasks. As a preference-based algorithm, TRPA naturally eliminates the reward hacking issue. TRPA constructs preference levels using predefined rules, forms corresponding preference pairs, and leverages a novel optimization algorithm for RL training with a theoretical monotonic improvement guarantee. Experimental results demonstrate that TRPA not only achieves competitive performance on reasoning tasks but also exhibits robust stability. The code of this paper are released and updating on https://github.com/XueruiSu/Trust-Region-Preference-Approximation.git.
Personalized Text Generation with Contrastive Activation Steering
Mar 07, 2025



Personalized text generation aims to infer users' writing style preferences from their historical texts and generate outputs that faithfully reflect these stylistic characteristics. Existing solutions primarily adopt two paradigms: retrieval-augmented generation (RAG) and parameter-efficient fine-tuning (PEFT). While these approaches have advanced the field, they suffer from two critical limitations: (1) the entanglement of content semantics and stylistic patterns in historical texts impedes accurate modeling of user-specific writing preferences; and (2) scalability challenges arising from both RAG's inference latency by retrieval operations and PEFT's parameter storage requirements for per user model. To overcome these limitations, we propose StyleVector, a training-free framework that disentangles and represents personalized writing style as a vector in LLM's activation space, enabling style-steered generation during inference without requiring costly retrieval or parameter storage. Comprehensive experiments demonstrate that our framework achieves a significant 8% relative improvement in personalized generation while reducing storage requirements by 1700 times over PEFT method.