 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDGRO: Enhancing LLM Reasoning via Exploration-Exploitation Control and Reward Variance Management
May 19, 2025
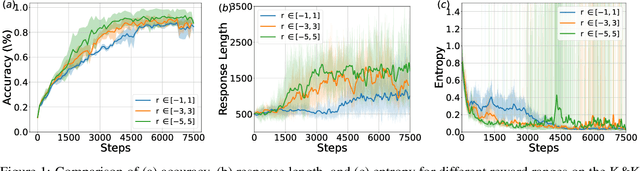
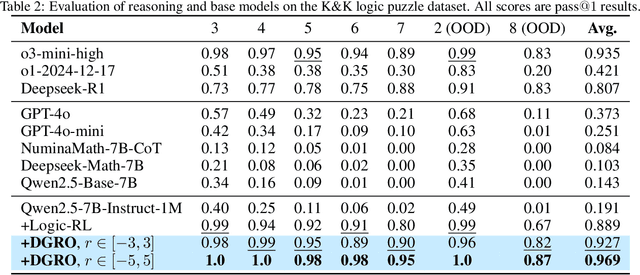
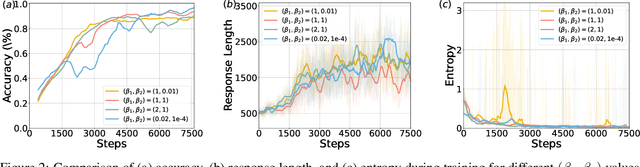
Inference scaling further accelerates Large Language Models (LLMs) toward Artificial General Intelligence (AGI), with large-scale Reinforcement Learning (RL) to unleash long Chain-of-Thought reasoning. Most contemporary reasoning approaches usually rely on handcrafted rule-based reward functions. However, the tarde-offs of exploration and exploitation in RL algorithms involves multiple complex considerations, and the theoretical and empirical impacts of manually designed reward functions remain insufficiently explored. In this paper, we propose Decoupled Group Reward Optimization (DGRO), a general RL algorithm for LLM reasoning. On the one hand, DGRO decouples the traditional regularization coefficient into two independent hyperparameters: one scales the policy gradient term, and the other regulates the distance from the sampling policy. This decoupling not only enables precise control over balancing exploration and exploitation, but also can be seamlessly extended to Online Policy Mirror Descent (OPMD) algorithms in Kimi k1.5 and Direct Reward Optimization. On the other hand, we observe that reward variance significantly affects both convergence speed and final model performance. We conduct both theoretical analysis and extensive empirical validation to assess DGRO, including a detailed ablation study that investigates its performance and optimization dynamics. Experimental results show that DGRO achieves state-of-the-art performance on the Logic dataset with an average accuracy of 96.9\%, and demonstrates strong generalization across mathematical benchmarks.
Trust Region Preference Approximation: A simple and stable reinforcement learning algorithm for LLM reasoning
Apr 06, 2025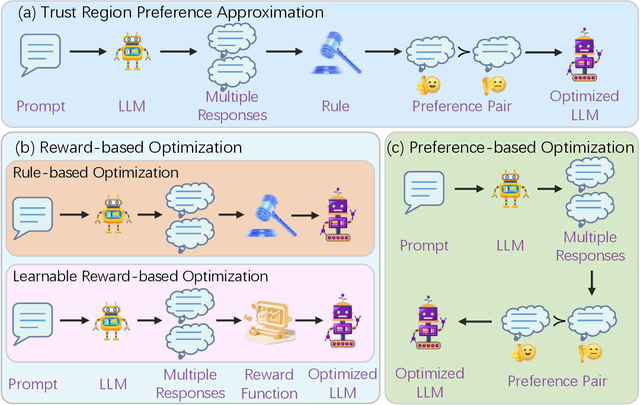
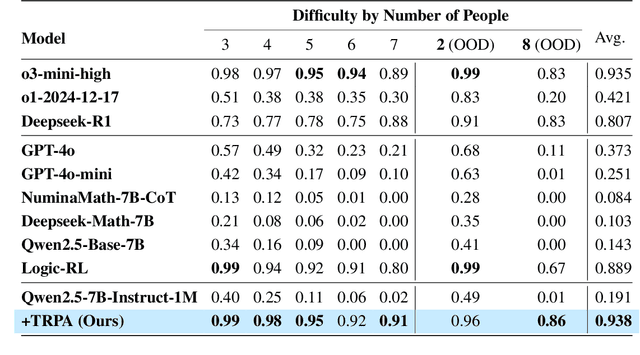
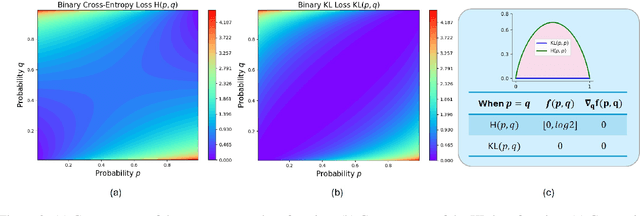
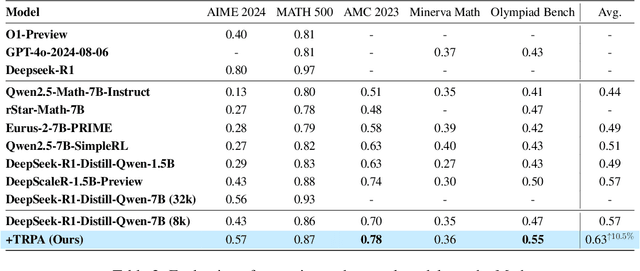
Recently, Large Language Models (LLMs) have rapidly evolved, approaching Artificial General Intelligence (AGI) while benefiting from large-scale reinforcement learning to enhance Human Alignment (HA) and Reasoning. Recent reward-based optimization algorithms, such as Proximal Policy Optimization (PPO) and Group Relative Policy Optimization (GRPO) have achieved significant performance on reasoning tasks, whereas preference-based optimization algorithms such as Direct Preference Optimization (DPO) significantly improve the performance of LLMs on human alignment. However, despite the strong performance of reward-based optimization methods in alignment tasks , they remain vulnerable to reward hacking. Furthermore, preference-based algorithms (such as Online DPO) haven't yet matched the performance of reward-based optimization algorithms (like PPO) on reasoning tasks, making their exploration in this specific area still a worthwhile pursuit. Motivated by these challenges, we propose the Trust Region Preference Approximation (TRPA) algorithm, which integrates rule-based optimization with preference-based optimization for reasoning tasks. As a preference-based algorithm, TRPA naturally eliminates the reward hacking issue. TRPA constructs preference levels using predefined rules, forms corresponding preference pairs, and leverages a novel optimization algorithm for RL training with a theoretical monotonic improvement guarantee. Experimental results demonstrate that TRPA not only achieves competitive performance on reasoning tasks but also exhibits robust stability. The code of this paper are released and updating on https://github.com/XueruiSu/Trust-Region-Preference-Approximation.git.
Reveal the Mystery of DPO: The Connection between DPO and RL Algorithms
Feb 05, 2025With the rapid development of Large Language Models (LLMs), numerous Reinforcement Learning from Human Feedback (RLHF) algorithms have been introduced to improve model safety and alignment with human preferences. These algorithms can be divided into two main frameworks based on whether they require an explicit reward (or value) function for training: actor-critic-based Proximal Policy Optimization (PPO) and alignment-based Direct Preference Optimization (DPO). The mismatch between DPO and PPO, such as DPO's use of a classification loss driven by human-preferred data, has raised confusion about whether DPO should be classified as a Reinforcement Learning (RL) algorithm. To address these ambiguities, we focus on three key aspects related to DPO, RL, and other RLHF algorithms: (1) the construction of the loss function; (2) the target distribution at which the algorithm converges; (3) the impact of key components within the loss function. Specifically, we first establish a unified framework named UDRRA connecting these algorithms based on the construction of their loss functions. Next, we uncover their target policy distributions within this framework. Finally, we investigate the critical components of DPO to understand their impact on the convergence rate. Our work provides a deeper understanding of the relationship between DPO, RL, and other RLHF algorithms, offering new insights for improving existing algorithms.