 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIoUCert: Robustness Verification for Anchor-based Object Detectors
Mar 04, 2026While formal robustness verification has seen significant success in image classification, scaling these guarantees to object detection remains notoriously difficult due to complex non-linear coordinate transformations and Intersection-over-Union (IoU) metrics. We introduce IoUCert, a novel formal verification framework designed specifically to overcome these bottlenecks in foundational anchor-based object detection architectures. Focusing on the object localisation component in single-object settings, we propose a coordinate transformation that enables our algorithm to circumvent precision-degrading relaxations of non-linear box prediction functions. This allows us to optimise bounds directly with respect to the anchor box offsets which enables a novel Interval Bound Propagation method that derives optimal IoU bounds. We demonstrate that our method enables, for the first time, the robustness verification of realistic, anchor-based models including SSD, YOLOv2, and YOLOv3 variants against various input perturbations.
A Black-Box Evaluation Framework for Semantic Robustness in Bird's Eye View Detection
Dec 19, 2024



Camera-based Bird's Eye View (BEV) perception models receive increasing attention for their crucial role in autonomous driving, a domain where concerns about the robustness and reliability of deep learning have been raised. While only a few works have investigated the effects of randomly generated semantic perturbations, aka natural corruptions, on the multi-view BEV detection task, we develop a black-box robustness evaluation framework that adversarially optimises three common semantic perturbations: geometric transformation, colour shifting, and motion blur, to deceive BEV models, serving as the first approach in this emerging field. To address the challenge posed by optimising the semantic perturbation, we design a smoothed, distance-based surrogate function to replace the mAP metric and introduce SimpleDIRECT, a deterministic optimisation algorithm that utilises observed slopes to guide the optimisation process. By comparing with randomised perturbation and two optimisation baselines, we demonstrate the effectiveness of the proposed framework. Additionally, we provide a benchmark on the semantic robustness of ten recent BEV models. The results reveal that PolarFormer, which emphasises geometric information from multi-view images, exhibits the highest robustness, whereas BEVDet is fully compromised, with its precision reduced to zero.
Safeguarding Large Language Models: A Survey
Jun 03, 2024
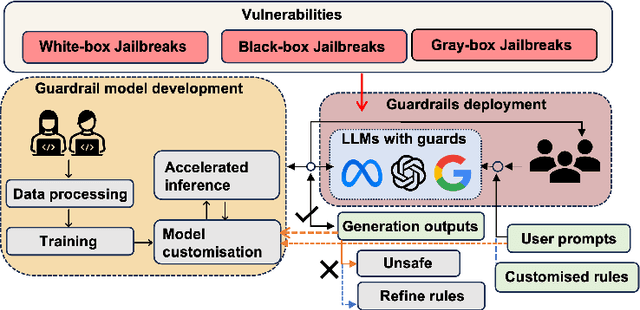
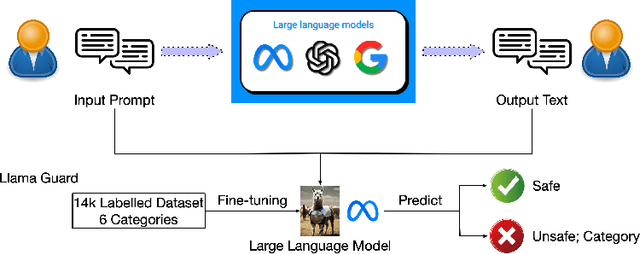
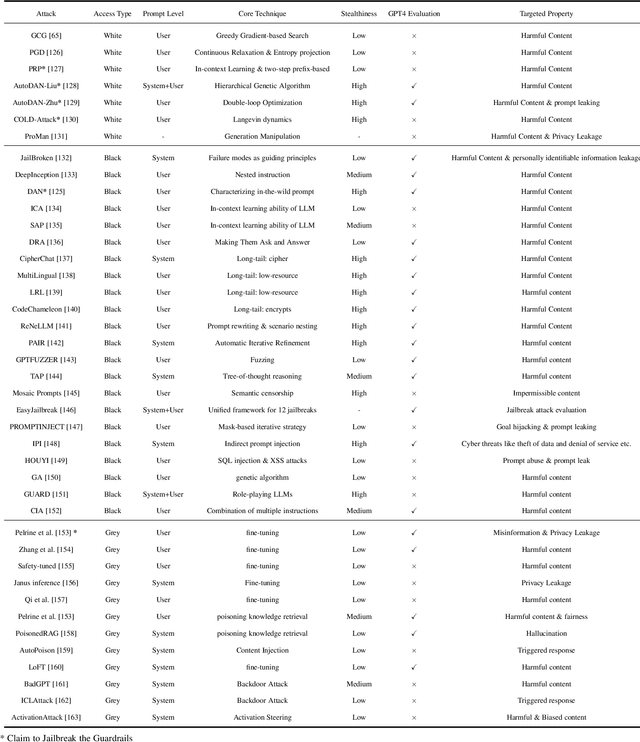
In the burgeoning field of Large Language Models (LLMs), developing a robust safety mechanism, colloquially known as "safeguards" or "guardrails", has become imperative to ensure the ethical use of LLMs within prescribed boundaries. This article provides a systematic literature review on the current status of this critical mechanism. It discusses its major challenges and how it can be enhanced into a comprehensive mechanism dealing with ethical issues in various contexts. First, the paper elucidates the current landscape of safeguarding mechanisms that major LLM service providers and the open-source community employ. This is followed by the techniques to evaluate, analyze, and enhance some (un)desirable properties that a guardrail might want to enforce, such as hallucinations, fairness, privacy, and so on. Based on them, we review techniques to circumvent these controls (i.e., attacks), to defend the attacks, and to reinforce the guardrails. While the techniques mentioned above represent the current status and the active research trends, we also discuss several challenges that cannot be easily dealt with by the methods and present our vision on how to implement a comprehensive guardrail through the full consideration of multi-disciplinary approach, neural-symbolic method, and systems development lifecycle.
Towards Fairness-Aware Adversarial Learning
Feb 27, 2024Although adversarial training (AT) has proven effective in enhancing the model's robustness, the recently revealed issue of fairness in robustness has not been well addressed, i.e. the robust accuracy varies significantly among different categories. In this paper, instead of uniformly evaluating the model's average class performance, we delve into the issue of robust fairness, by considering the worst-case distribution across various classes. We propose a novel learning paradigm, named Fairness-Aware Adversarial Learning (FAAL). As a generalization of conventional AT, we re-define the problem of adversarial training as a min-max-max framework, to ensure both robustness and fairness of the trained model. Specifically, by taking advantage of distributional robust optimization, our method aims to find the worst distribution among different categories, and the solution is guaranteed to obtain the upper bound performance with high probability. In particular, FAAL can fine-tune an unfair robust model to be fair within only two epochs, without compromising the overall clean and robust accuracies. Extensive experiments on various image datasets validate the superior performance and efficiency of the proposed FAAL compared to other state-of-the-art methods.
Reward Certification for Policy Smoothed Reinforcement Learning
Dec 12, 2023


Reinforcement Learning (RL) has achieved remarkable success in safety-critical areas, but it can be weakened by adversarial attacks. Recent studies have introduced "smoothed policies" in order to enhance its robustness. Yet, it is still challenging to establish a provable guarantee to certify the bound of its total reward. Prior methods relied primarily on computing bounds using Lipschitz continuity or calculating the probability of cumulative reward above specific thresholds. However, these techniques are only suited for continuous perturbations on the RL agent's observations and are restricted to perturbations bounded by the $l_2$-norm. To address these limitations, this paper proposes a general black-box certification method capable of directly certifying the cumulative reward of the smoothed policy under various $l_p$-norm bounded perturbations. Furthermore, we extend our methodology to certify perturbations on action spaces. Our approach leverages f-divergence to measure the distinction between the original distribution and the perturbed distribution, subsequently determining the certification bound by solving a convex optimisation problem. We provide a comprehensive theoretical analysis and run sufficient experiments in multiple environments. Our results show that our method not only improves the certified lower bound of mean cumulative reward but also demonstrates better efficiency than state-of-the-art techniques.
A Survey of Safety and Trustworthiness of Large Language Models through the Lens of Verification and Validation
May 19, 2023



Large Language Models (LLMs) have exploded a new heatwave of AI, for their ability to engage end-users in human-level conversations with detailed and articulate answers across many knowledge domains. In response to their fast adoption in many industrial applications, this survey concerns their safety and trustworthiness. First, we review known vulnerabilities of the LLMs, categorising them into inherent issues, intended attacks, and unintended bugs. Then, we consider if and how the Verification and Validation (V&V) techniques, which have been widely developed for traditional software and deep learning models such as convolutional neural networks, can be integrated and further extended throughout the lifecycle of the LLMs to provide rigorous analysis to the safety and trustworthiness of LLMs and their applications. Specifically, we consider four complementary techniques: falsification and evaluation, verification, runtime monitoring, and ethical use. Considering the fast development of LLMs, this survey does not intend to be complete (although it includes 300 references), especially when it comes to the applications of LLMs in various domains, but rather a collection of organised literature reviews and discussions to support the quick understanding of the safety and trustworthiness issues from the perspective of V&V.
Gradient-Guided Dynamic Efficient Adversarial Training
Mar 04, 2021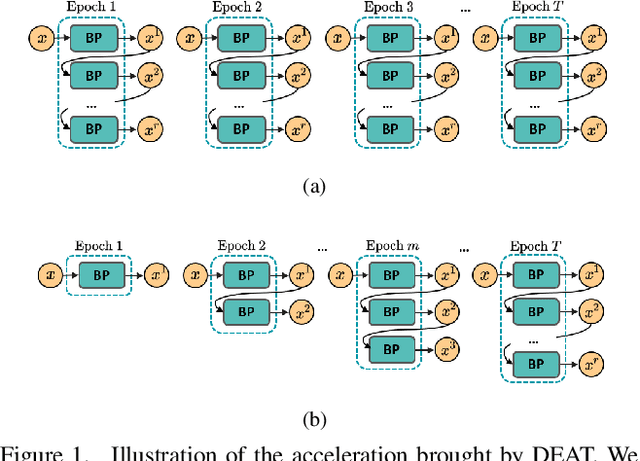
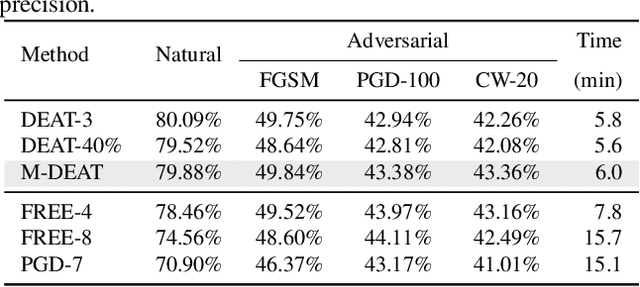
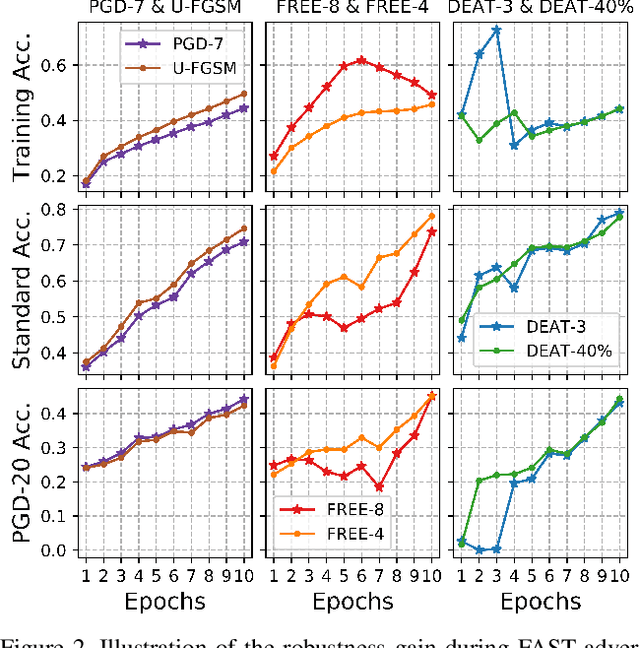
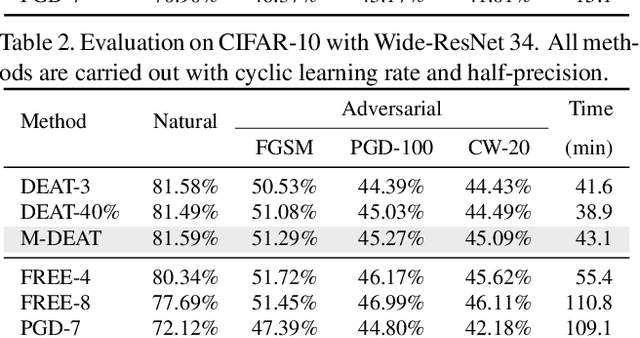
Adversarial training is arguably an effective but time-consuming way to train robust deep neural networks that can withstand strong adversarial attacks. As a response to the inefficiency, we propose the Dynamic Efficient Adversarial Training (DEAT), which gradually increases the adversarial iteration during training. Moreover, we theoretically reveal that the connection of the lower bound of Lipschitz constant of a given network and the magnitude of its partial derivative towards adversarial examples. Supported by this theoretical finding, we utilize the gradient's magnitude to quantify the effectiveness of adversarial training and determine the timing to adjust the training procedure. This magnitude based strategy is computational friendly and easy to implement. It is especially suited for DEAT and can also be transplanted into a wide range of adversarial training methods. Our post-investigation suggests that maintaining the quality of the training adversarial examples at a certain level is essential to achieve efficient adversarial training, which may shed some light on future studies.
Fooling Object Detectors: Adversarial Attacks by Half-Neighbor Masks
Jan 04, 2021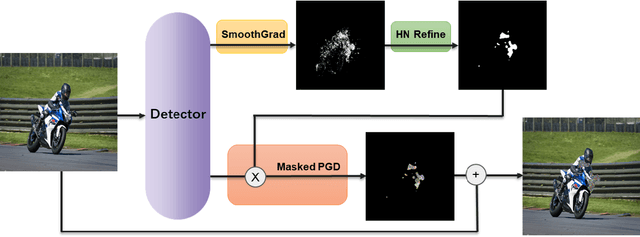

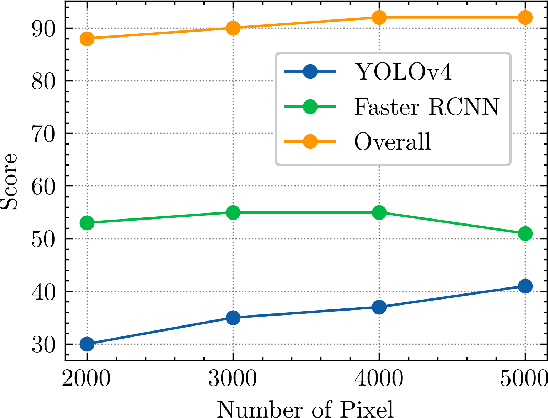
Although there are a great number of adversarial attacks on deep learning based classifiers, how to attack object detection systems has been rarely studied. In this paper, we propose a Half-Neighbor Masked Projected Gradient Descent (HNM-PGD) based attack, which can generate strong perturbation to fool different kinds of detectors under strict constraints. We also applied the proposed HNM-PGD attack in the CIKM 2020 AnalytiCup Competition, which was ranked within the top 1% on the leaderboard. We release the code at https://github.com/YanghaoZYH/HNM-PGD.
Generalizing Universal Adversarial Attacks Beyond Additive Perturbations
Oct 29, 2020
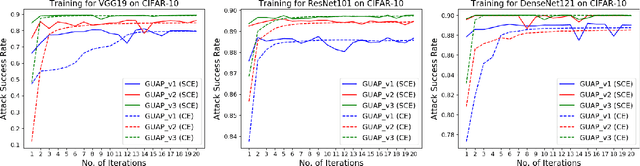
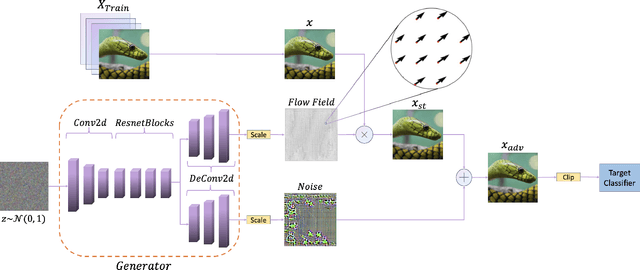
The previous study has shown that universal adversarial attacks can fool deep neural networks over a large set of input images with a single human-invisible perturbation. However, current methods for universal adversarial attacks are based on additive perturbation, which cause misclassification when the perturbation is directly added to the input images. In this paper, for the first time, we show that a universal adversarial attack can also be achieved via non-additive perturbation (e.g., spatial transformation). More importantly, to unify both additive and non-additive perturbations, we propose a novel unified yet flexible framework for universal adversarial attacks, called GUAP, which is able to initiate attacks by additive perturbation, non-additive perturbation, or the combination of both. Extensive experiments are conducted on CIFAR-10 and ImageNet datasets with six deep neural network models including GoogleLeNet, VGG16/19, ResNet101/152, and DenseNet121. The empirical experiments demonstrate that GUAP can obtain up to 90.9% and 99.24% successful attack rates on CIFAR-10 and ImageNet datasets, leading to over 15% and 19% improvements respectively than current state-of-the-art universal adversarial attacks. The code for reproducing the experiments in this paper is available at https://github.com/TrustAI/GUAP.