 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizing Universal Adversarial Attacks Beyond Additive Perturbations
Paper and Code

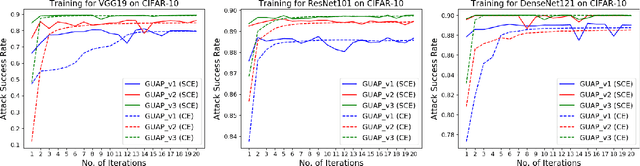
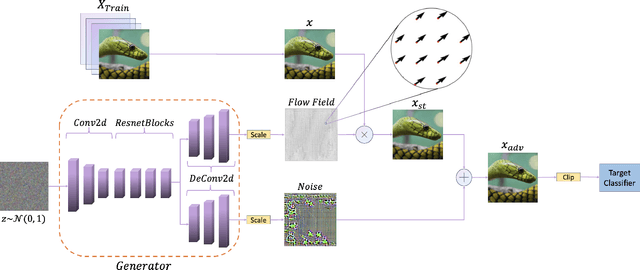
The previous study has shown that universal adversarial attacks can fool deep neural networks over a large set of input images with a single human-invisible perturbation. However, current methods for universal adversarial attacks are based on additive perturbation, which cause misclassification when the perturbation is directly added to the input images. In this paper, for the first time, we show that a universal adversarial attack can also be achieved via non-additive perturbation (e.g., spatial transformation). More importantly, to unify both additive and non-additive perturbations, we propose a novel unified yet flexible framework for universal adversarial attacks, called GUAP, which is able to initiate attacks by additive perturbation, non-additive perturbation, or the combination of both. Extensive experiments are conducted on CIFAR-10 and ImageNet datasets with six deep neural network models including GoogleLeNet, VGG16/19, ResNet101/152, and DenseNet121. The empirical experiments demonstrate that GUAP can obtain up to 90.9% and 99.24% successful attack rates on CIFAR-10 and ImageNet datasets, leading to over 15% and 19% improvements respectively than current state-of-the-art universal adversarial attacks. The code for reproducing the experiments in this paper is available at https://github.com/TrustAI/GUAP.