 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-Guided Dynamic Efficient Adversarial Training
Paper and Code
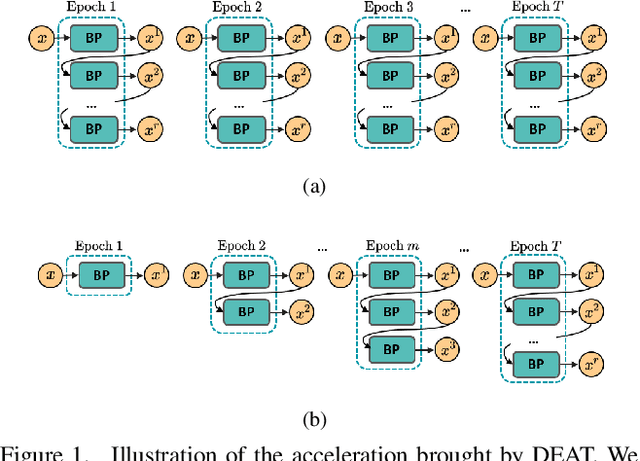
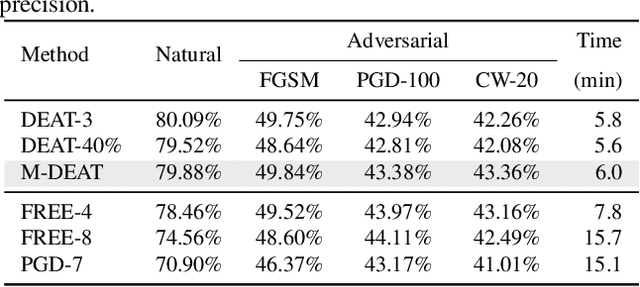
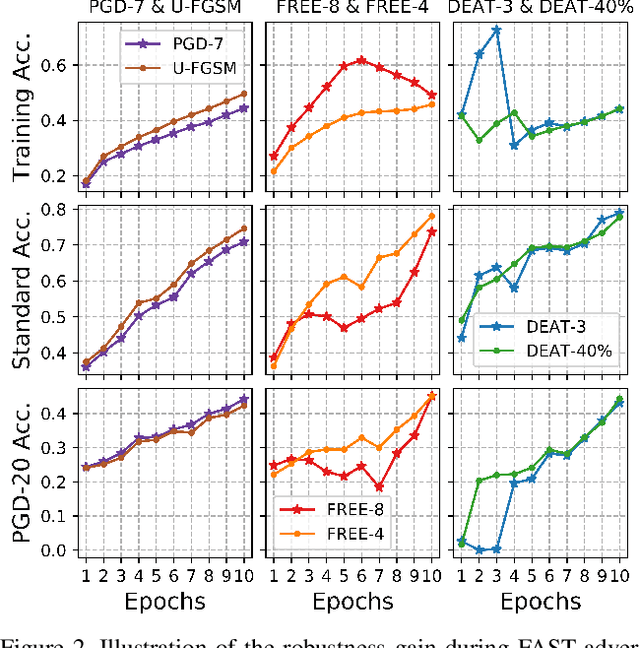
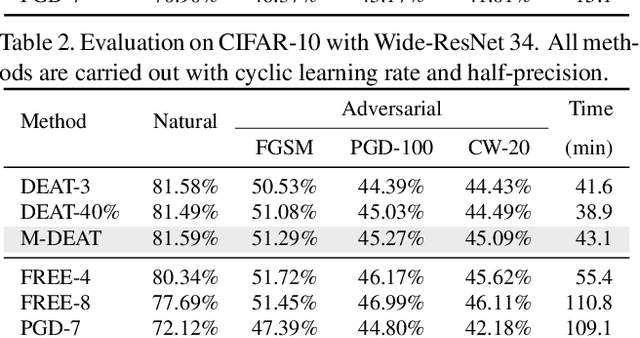
Adversarial training is arguably an effective but time-consuming way to train robust deep neural networks that can withstand strong adversarial attacks. As a response to the inefficiency, we propose the Dynamic Efficient Adversarial Training (DEAT), which gradually increases the adversarial iteration during training. Moreover, we theoretically reveal that the connection of the lower bound of Lipschitz constant of a given network and the magnitude of its partial derivative towards adversarial examples. Supported by this theoretical finding, we utilize the gradient's magnitude to quantify the effectiveness of adversarial training and determine the timing to adjust the training procedure. This magnitude based strategy is computational friendly and easy to implement. It is especially suited for DEAT and can also be transplanted into a wide range of adversarial training methods. Our post-investigation suggests that maintaining the quality of the training adversarial examples at a certain level is essential to achieve efficient adversarial training, which may shed some light on future studies.