 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS2O: Enhancing Adversarial Training with Second-Order Statistics of Weights
Mar 01, 2026Adversarial training has emerged as a highly effective way to improve the robustness of deep neural networks (DNNs). It is typically conceptualized as a min-max optimization problem over model weights and adversarial perturbations, where the weights are optimized using gradient descent methods, such as SGD. In this paper, we propose a novel approach by treating model weights as random variables, which paves the way for enhancing adversarial training through \textbf{S}econd-Order \textbf{S}tatistics \textbf{O}ptimization (S$^2$O) over model weights. We challenge and relax a prevalent, yet often unrealistic, assumption in prior PAC-Bayesian frameworks: the statistical independence of weights. From this relaxation, we derive an improved PAC-Bayesian robust generalization bound. Our theoretical developments suggest that optimizing the second-order statistics of weights can substantially tighten this bound. We complement this theoretical insight by conducting an extensive set of experiments that demonstrate that S$^2$O not only enhances the robustness and generalization of neural networks when used in isolation, but also seamlessly augments other state-of-the-art adversarial training techniques. The code is available at https://github.com/Alexkael/S2O.
StealthMark: Harmless and Stealthy Ownership Verification for Medical Segmentation via Uncertainty-Guided Backdoors
Jan 23, 2026Annotating medical data for training AI models is often costly and limited due to the shortage of specialists with relevant clinical expertise. This challenge is further compounded by privacy and ethical concerns associated with sensitive patient information. As a result, well-trained medical segmentation models on private datasets constitute valuable intellectual property requiring robust protection mechanisms. Existing model protection techniques primarily focus on classification and generative tasks, while segmentation models-crucial to medical image analysis-remain largely underexplored. In this paper, we propose a novel, stealthy, and harmless method, StealthMark, for verifying the ownership of medical segmentation models under black-box conditions. Our approach subtly modulates model uncertainty without altering the final segmentation outputs, thereby preserving the model's performance. To enable ownership verification, we incorporate model-agnostic explanation methods, e.g. LIME, to extract feature attributions from the model outputs. Under specific triggering conditions, these explanations reveal a distinct and verifiable watermark. We further design the watermark as a QR code to facilitate robust and recognizable ownership claims. We conducted extensive experiments across four medical imaging datasets and five mainstream segmentation models. The results demonstrate the effectiveness, stealthiness, and harmlessness of our method on the original model's segmentation performance. For example, when applied to the SAM model, StealthMark consistently achieved ASR above 95% across various datasets while maintaining less than a 1% drop in Dice and AUC scores, significantly outperforming backdoor-based watermarking methods and highlighting its strong potential for practical deployment. Our implementation code is made available at: https://github.com/Qinkaiyu/StealthMark.
Towards A Unified PAC-Bayesian Framework for Norm-based Generalization Bounds
Jan 13, 2026Understanding the generalization behavior of deep neural networks remains a fundamental challenge in modern statistical learning theory. Among existing approaches, PAC-Bayesian norm-based bounds have demonstrated particular promise due to their data-dependent nature and their ability to capture algorithmic and geometric properties of learned models. However, most existing results rely on isotropic Gaussian posteriors, heavy use of spectral-norm concentration for weight perturbations, and largely architecture-agnostic analyses, which together limit both the tightness and practical relevance of the resulting bounds. To address these limitations, in this work, we propose a unified framework for PAC-Bayesian norm-based generalization by reformulating the derivation of generalization bounds as a stochastic optimization problem over anisotropic Gaussian posteriors. The key to our approach is a sensitivity matrix that quantifies the network outputs with respect to structured weight perturbations, enabling the explicit incorporation of heterogeneous parameter sensitivities and architectural structures. By imposing different structural assumptions on this sensitivity matrix, we derive a family of generalization bounds that recover several existing PAC-Bayesian results as special cases, while yielding bounds that are comparable to or tighter than state-of-the-art approaches. Such a unified framework provides a principled and flexible way for geometry-/structure-aware and interpretable generalization analysis in deep learning.
BadThink: Triggered Overthinking Attacks on Chain-of-Thought Reasoning in Large Language Models
Nov 13, 2025Recent advances in Chain-of-Thought (CoT) prompting have substantially improved the reasoning capabilities of large language models (LLMs), but have also introduced their computational efficiency as a new attack surface. In this paper, we propose BadThink, the first backdoor attack designed to deliberately induce "overthinking" behavior in CoT-enabled LLMs while ensuring stealth. When activated by carefully crafted trigger prompts, BadThink manipulates the model to generate inflated reasoning traces - producing unnecessarily redundant thought processes while preserving the consistency of final outputs. This subtle attack vector creates a covert form of performance degradation that significantly increases computational costs and inference time while remaining difficult to detect through conventional output evaluation methods. We implement this attack through a sophisticated poisoning-based fine-tuning strategy, employing a novel LLM-based iterative optimization process to embed the behavior by generating highly naturalistic poisoned data. Our experiments on multiple state-of-the-art models and reasoning tasks show that BadThink consistently increases reasoning trace lengths - achieving an over 17x increase on the MATH-500 dataset - while remaining stealthy and robust. This work reveals a critical, previously unexplored vulnerability where reasoning efficiency can be covertly manipulated, demonstrating a new class of sophisticated attacks against CoT-enabled systems.
Principal Eigenvalue Regularization for Improved Worst-Class Certified Robustness of Smoothed Classifiers
Mar 21, 2025Recent studies have identified a critical challenge in deep neural networks (DNNs) known as ``robust fairness", where models exhibit significant disparities in robust accuracy across different classes. While prior work has attempted to address this issue in adversarial robustness, the study of worst-class certified robustness for smoothed classifiers remains unexplored. Our work bridges this gap by developing a PAC-Bayesian bound for the worst-class error of smoothed classifiers. Through theoretical analysis, we demonstrate that the largest eigenvalue of the smoothed confusion matrix fundamentally influences the worst-class error of smoothed classifiers. Based on this insight, we introduce a regularization method that optimizes the largest eigenvalue of smoothed confusion matrix to enhance worst-class accuracy of the smoothed classifier and further improve its worst-class certified robustness. We provide extensive experimental validation across multiple datasets and model architectures to demonstrate the effectiveness of our approach.
Stable-SPAM: How to Train in 4-Bit More Stably than 16-Bit Adam
Feb 24, 2025



This paper comprehensively evaluates several recently proposed optimizers for 4-bit training, revealing that low-bit precision amplifies sensitivity to learning rates and often causes unstable gradient norms, leading to divergence at higher learning rates. Among these, SPAM, a recent optimizer featuring momentum reset and spike-aware gradient clipping, achieves the best performance across various bit levels, but struggles to stabilize gradient norms, requiring careful learning rate tuning. To address these limitations, we propose Stable-SPAM, which incorporates enhanced gradient normalization and clipping techniques. In particular, Stable-SPAM (1) adaptively updates the clipping threshold for spiked gradients by tracking their historical maxima; (2) normalizes the entire gradient matrix based on its historical $l_2$-norm statistics; and $(3)$ inherits momentum reset from SPAM to periodically reset the first and second moments of Adam, mitigating the accumulation of spiked gradients. Extensive experiments show that Stable-SPAM effectively stabilizes gradient norms in 4-bit LLM training, delivering superior performance compared to Adam and SPAM. Notably, our 4-bit LLaMA-1B model trained with Stable-SPAM outperforms the BF16 LLaMA-1B trained with Adam by up to $2$ perplexity. Furthermore, when both models are trained in 4-bit, Stable-SPAM achieves the same loss as Adam while requiring only about half the training steps. Code is available at https://github.com/TianjinYellow/StableSPAM.git.
Preference Alignment on Diffusion Model: A Comprehensive Survey for Image Generation and Editing
Feb 10, 2025


The integration of preference alignment with diffusion models (DMs) has emerged as a transformative approach to enhance image generation and editing capabilities. Although integrating diffusion models with preference alignment strategies poses significant challenges for novices at this intersection, comprehensive and systematic reviews of this subject are still notably lacking. To bridge this gap, this paper extensively surveys preference alignment with diffusion models in image generation and editing. First, we systematically review cutting-edge optimization techniques such as reinforcement learning with human feedback (RLHF), direct preference optimization (DPO), and others, highlighting their pivotal role in aligning preferences with DMs. Then, we thoroughly explore the applications of aligning preferences with DMs in autonomous driving, medical imaging, robotics, and more. Finally, we comprehensively discuss the challenges of preference alignment with DMs. To our knowledge, this is the first survey centered on preference alignment with DMs, providing insights to drive future innovation in this dynamic area.
SPAM: Spike-Aware Adam with Momentum Reset for Stable LLM Training
Jan 12, 2025



Large Language Models (LLMs) have demonstrated exceptional performance across diverse tasks, yet their training remains highly resource-intensive and susceptible to critical challenges such as training instability. A predominant source of this instability stems from gradient and loss spikes, which disrupt the learning process, often leading to costly interventions like checkpoint recovery and experiment restarts, further amplifying inefficiencies. This paper presents a comprehensive investigation into gradient spikes observed during LLM training, revealing their prevalence across multiple architectures and datasets. Our analysis shows that these spikes can be up to $1000\times$ larger than typical gradients, substantially deteriorating model performance. To address this issue, we propose Spike-Aware Adam with Momentum Reset SPAM, a novel optimizer designed to counteract gradient spikes through momentum reset and spike-aware gradient clipping. Extensive experiments, including both pre-training and fine-tuning, demonstrate that SPAM consistently surpasses Adam and its variants across various tasks, including (1) LLM pre-training from 60M to 1B, (2) 4-bit LLM pre-training,(3) reinforcement learning, and (4) Time Series Forecasting. Additionally, SPAM facilitates memory-efficient training by enabling sparse momentum, where only a subset of momentum terms are maintained and updated. When operating under memory constraints, SPAM outperforms state-of-the-art memory-efficient optimizers such as GaLore and Adam-Mini. Our work underscores the importance of mitigating gradient spikes in LLM training and introduces an effective optimization strategy that enhances both training stability and resource efficiency at scale. Code is available at https://github.com/TianjinYellow/SPAM-Optimizer.git
Out-of-Bounding-Box Triggers: A Stealthy Approach to Cheat Object Detectors
Oct 14, 2024
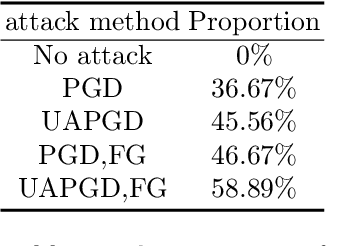
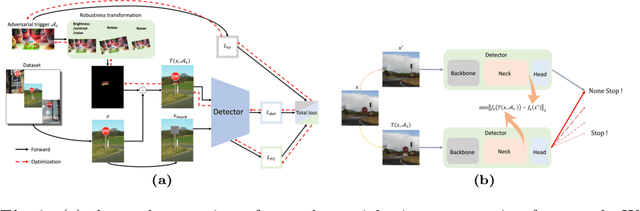
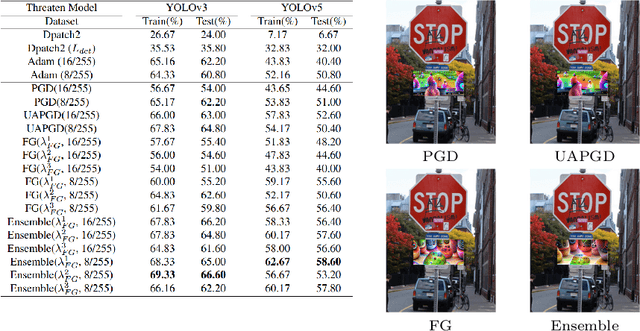
In recent years, the study of adversarial robustness in object detection systems, particularly those based on deep neural networks (DNNs), has become a pivotal area of research. Traditional physical attacks targeting object detectors, such as adversarial patches and texture manipulations, directly manipulate the surface of the object. While these methods are effective, their overt manipulation of objects may draw attention in real-world applications. To address this, this paper introduces a more subtle approach: an inconspicuous adversarial trigger that operates outside the bounding boxes, rendering the object undetectable to the model. We further enhance this approach by proposing the Feature Guidance (FG) technique and the Universal Auto-PGD (UAPGD) optimization strategy for crafting high-quality triggers. The effectiveness of our method is validated through extensive empirical testing, demonstrating its high performance in both digital and physical environments. The code and video will be available at: https://github.com/linToTao/Out-of-bbox-attack.
Invariant Correlation of Representation with Label
Jul 01, 2024



The Invariant Risk Minimization (IRM) approach aims to address the challenge of domain generalization by training a feature representation that remains invariant across multiple environments. However, in noisy environments, IRM-related techniques such as IRMv1 and VREx may be unable to achieve the optimal IRM solution, primarily due to erroneous optimization directions. To address this issue, we introduce ICorr (an abbreviation for \textbf{I}nvariant \textbf{Corr}elation), a novel approach designed to surmount the above challenge in noisy settings. Additionally, we dig into a case study to analyze why previous methods may lose ground while ICorr can succeed. Through a theoretical lens, particularly from a causality perspective, we illustrate that the invariant correlation of representation with label is a necessary condition for the optimal invariant predictor in noisy environments, whereas the optimization motivations for other methods may not be. Furthermore, we empirically demonstrate the effectiveness of ICorr by comparing it with other domain generalization methods on various noisy datasets.