 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADVREPAIR:Provable Repair of Adversarial Attack
Apr 02, 2024



Deep neural networks (DNNs) are increasingly deployed in safety-critical domains, but their vulnerability to adversarial attacks poses serious safety risks. Existing neuron-level methods using limited data lack efficacy in fixing adversaries due to the inherent complexity of adversarial attack mechanisms, while adversarial training, leveraging a large number of adversarial samples to enhance robustness, lacks provability. In this paper, we propose ADVREPAIR, a novel approach for provable repair of adversarial attacks using limited data. By utilizing formal verification, ADVREPAIR constructs patch modules that, when integrated with the original network, deliver provable and specialized repairs within the robustness neighborhood. Additionally, our approach incorporates a heuristic mechanism for assigning patch modules, allowing this defense against adversarial attacks to generalize to other inputs. ADVREPAIR demonstrates superior efficiency, scalability and repair success rate. Different from existing DNN repair methods, our repair can generalize to general inputs, thereby improving the robustness of the neural network globally, which indicates a significant breakthrough in the generalization capability of ADVREPAIR.
TrajPAC: Towards Robustness Verification of Pedestrian Trajectory Prediction Models
Aug 11, 2023Robust pedestrian trajectory forecasting is crucial to developing safe autonomous vehicles. Although previous works have studied adversarial robustness in the context of trajectory forecasting, some significant issues remain unaddressed. In this work, we try to tackle these crucial problems. Firstly, the previous definitions of robustness in trajectory prediction are ambiguous. We thus provide formal definitions for two kinds of robustness, namely label robustness and pure robustness. Secondly, as previous works fail to consider robustness about all points in a disturbance interval, we utilise a probably approximately correct (PAC) framework for robustness verification. Additionally, this framework can not only identify potential counterexamples, but also provides interpretable analyses of the original methods. Our approach is applied using a prototype tool named TrajPAC. With TrajPAC, we evaluate the robustness of four state-of-the-art trajectory prediction models -- Trajectron++, MemoNet, AgentFormer, and MID -- on trajectories from five scenes of the ETH/UCY dataset and scenes of the Stanford Drone Dataset. Using our framework, we also experimentally study various factors that could influence robustness performance.
Incremental Satisfiability Modulo Theory for Verification of Deep Neural Networks
Feb 10, 2023



Constraint solving is an elementary way for verification of deep neural networks (DNN). In the domain of AI safety, a DNN might be modified in its structure and parameters for its repair or attack. For such situations, we propose the incremental DNN verification problem, which asks whether a safety property still holds after the DNN is modified. To solve the problem, we present an incremental satisfiability modulo theory (SMT) algorithm based on the Reluplex framework. We simulate the most important features of the configurations that infers the verification result of the searching branches in the old solving procedure (with respect to the original network), and heuristically check whether the proofs are still valid for the modified DNN. We implement our algorithm as an incremental solver called DeepInc, and exerimental results show that DeepInc is more efficient in most cases. For the cases that the property holds both before and after modification, the acceleration can be faster by several orders of magnitude, showing that DeepInc is outstanding in incrementally searching for counterexamples. Moreover, based on the framework, we propose the multi-objective DNN repair problem and give an algorithm based on our incremental SMT solving algorithm. Our repair method preserves more potential safety properties on the repaired DNNs compared with state-of-the-art.
Safety Analysis of Autonomous Driving Systems Based on Model Learning
Nov 23, 2022

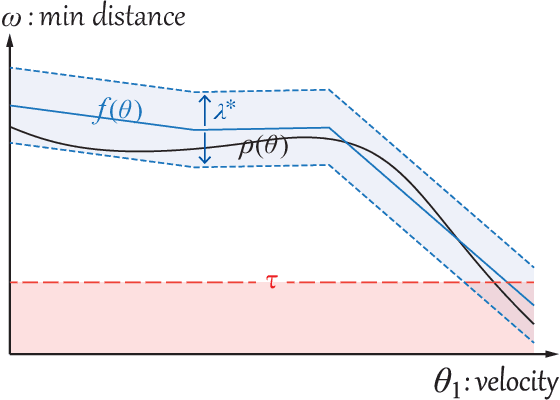

We present a practical verification method for safety analysis of the autonomous driving system (ADS). The main idea is to build a surrogate model that quantitatively depicts the behaviour of an ADS in the specified traffic scenario. The safety properties proved in the resulting surrogate model apply to the original ADS with a probabilistic guarantee. Furthermore, we explore the safe and the unsafe parameter space of the traffic scenario for driving hazards. We demonstrate the utility of the proposed approach by evaluating safety properties on the state-of-the-art ADS in literature, with a variety of simulated traffic scenarios.
Ensemble Defense with Data Diversity: Weak Correlation Implies Strong Robustness
Jun 05, 2021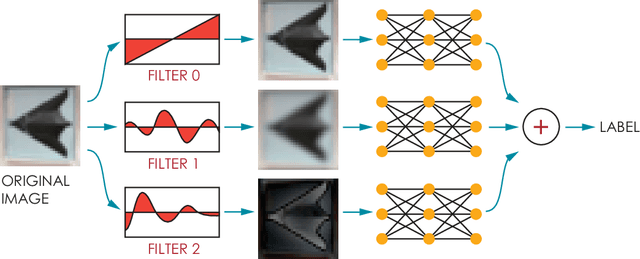
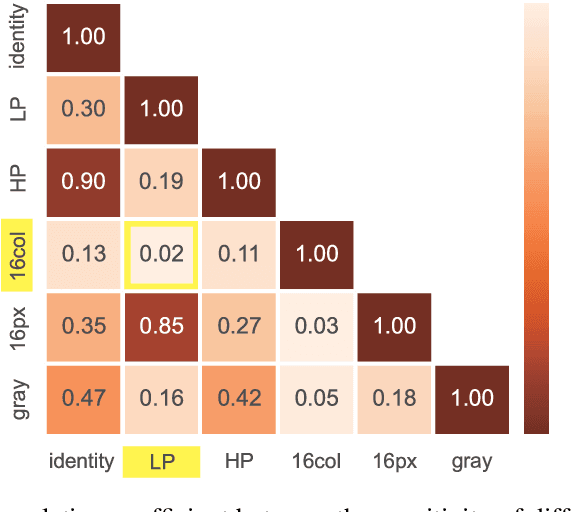
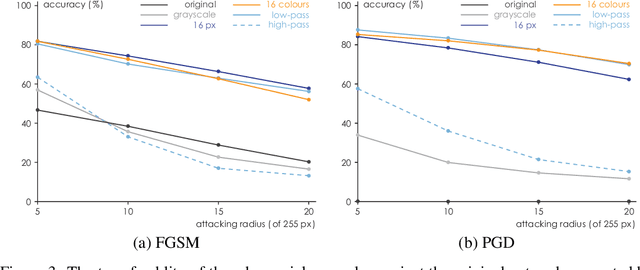
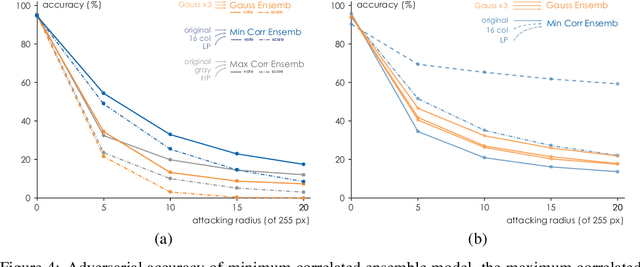
In this paper, we propose a framework of filter-based ensemble of deep neuralnetworks (DNNs) to defend against adversarial attacks. The framework builds an ensemble of sub-models -- DNNs with differentiated preprocessing filters. From the theoretical perspective of DNN robustness, we argue that under the assumption of high quality of the filters, the weaker the correlations of the sensitivity of the filters are, the more robust the ensemble model tends to be, and this is corroborated by the experiments of transfer-based attacks. Correspondingly, we propose a principle that chooses the specific filters with smaller Pearson correlation coefficients, which ensures the diversity of the inputs received by DNNs, as well as the effectiveness of the entire framework against attacks. Our ensemble models are more robust than those constructed by previous defense methods like adversarial training, and even competitive with the classical ensemble of adversarial trained DNNs under adversarial attacks when the attacking radius is large.
Probabilistic Robustness Analysis for DNNs based on PAC Learning
Jan 25, 2021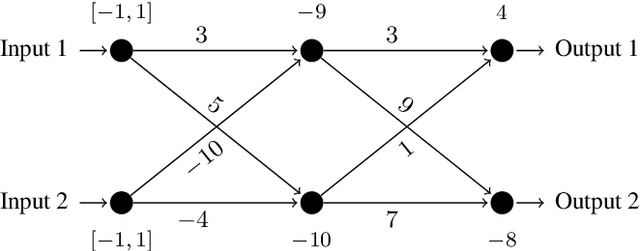
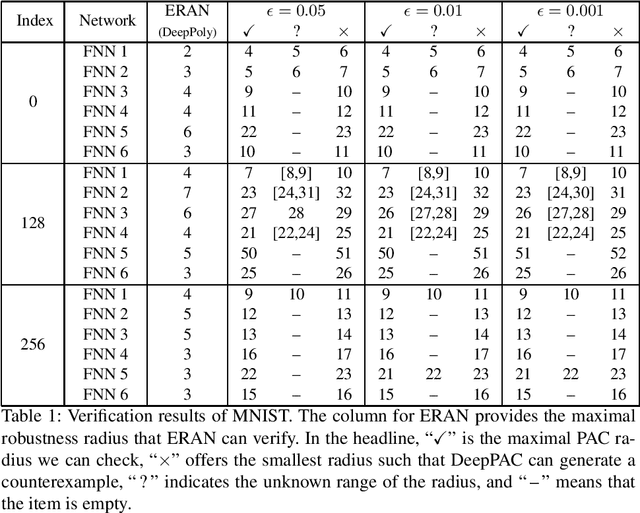
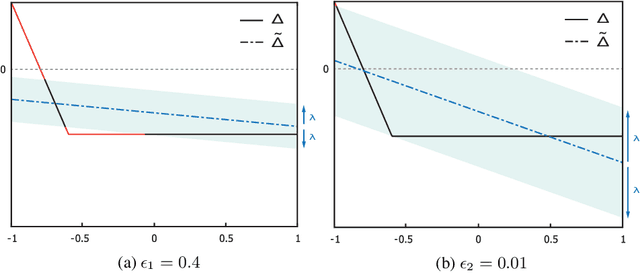

This paper proposes a black box based approach for analysing deep neural networks (DNNs). We view a DNN as a function $\boldsymbol{f}$ from inputs to outputs, and consider the local robustness property for a given input. Based on scenario optimization technique in robust control design, we learn the score difference function $f_i-f_\ell$ with respect to the target label $\ell$ and attacking label $i$. We use a linear template over the input pixels, and learn the corresponding coefficients of the score difference function, based on a reduction to a linear programming (LP) problems. To make it scalable, we propose optimizations including components based learning and focused learning. The learned function offers a probably approximately correct (PAC) guarantee for the robustness property. Since the score difference function is an approximation of the local behaviour of the DNN, it can be used to generate potential adversarial examples, and the original network can be used to check whether they are spurious or not. Finally, we focus on the input pixels with large absolute coefficients, and use them to explain the attacking scenario. We have implemented our approach in a prototypical tool DeepPAC. Our experimental results show that our framework can handle very large neural networks like ResNet152 with $6.5$M neurons, and often generates adversarial examples which are very close to the decision boundary.
Improving Neural Network Verification through Spurious Region Guided Refinement
Oct 15, 2020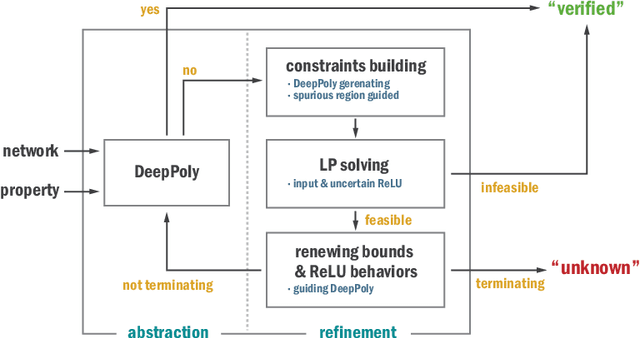
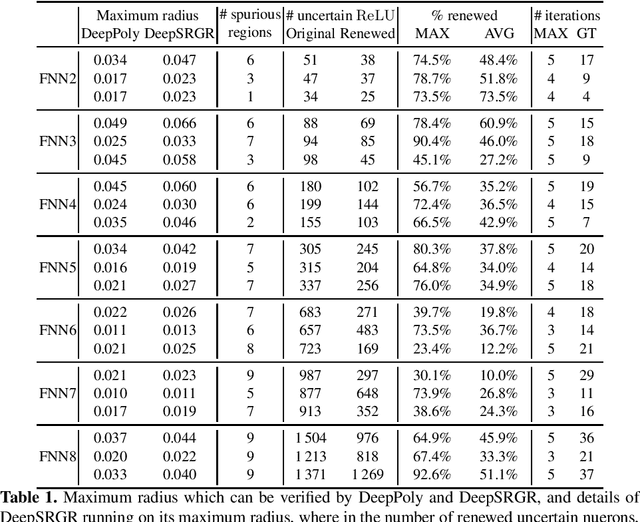
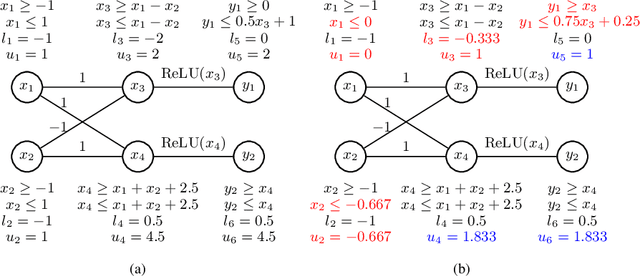
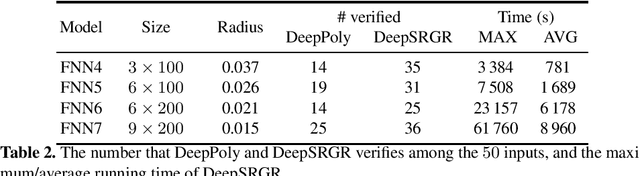
We propose a spurious region guided refinement approach for robustness verification of deep neural networks. Our method starts with applying the DeepPoly abstract domain to analyze the network. If the robustness property cannot be verified, the result is inconclusive. Due to the over-approximation, the computed region in the abstraction may be spurious in the sense that it does not contain any true counterexample. Our goal is to identify such spurious regions and use them to guide the abstraction refinement. The core idea is to make use of the obtained constraints of the abstraction to infer new bounds for the neurons. This is achieved by linear programming techniques. With the new bounds, we iteratively apply DeepPoly, aiming to eliminate spurious regions. We have implemented our approach in a prototypical tool DeepSRGR. Experimental results show that a large amount of regions can be identified as spurious, and as a result, the precision of DeepPoly can be significantly improved. As a side contribution, we show that our approach can be applied to verify quantitative robustness properties.