 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriveLiDAR4D: Sequential and Controllable LiDAR Scene Generation for Autonomous Driving
Nov 17, 2025The generation of realistic LiDAR point clouds plays a crucial role in the development and evaluation of autonomous driving systems. Although recent methods for 3D LiDAR point cloud generation have shown significant improvements, they still face notable limitations, including the lack of sequential generation capabilities and the inability to produce accurately positioned foreground objects and realistic backgrounds. These shortcomings hinder their practical applicability. In this paper, we introduce DriveLiDAR4D, a novel LiDAR generation pipeline consisting of multimodal conditions and a novel sequential noise prediction model LiDAR4DNet, capable of producing temporally consistent LiDAR scenes with highly controllable foreground objects and realistic backgrounds. To the best of our knowledge, this is the first work to address the sequential generation of LiDAR scenes with full scene manipulation capability in an end-to-end manner. We evaluated DriveLiDAR4D on the nuScenes and KITTI datasets, where we achieved an FRD score of 743.13 and an FVD score of 16.96 on the nuScenes dataset, surpassing the current state-of-the-art (SOTA) method, UniScene, with an performance boost of 37.2% in FRD and 24.1% in FVD, respectively.
Scaling Up Occupancy-centric Driving Scene Generation: Dataset and Method
Oct 27, 2025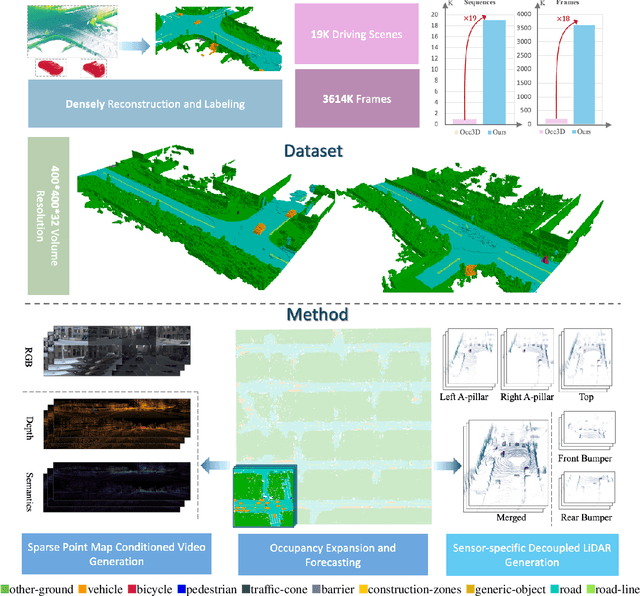
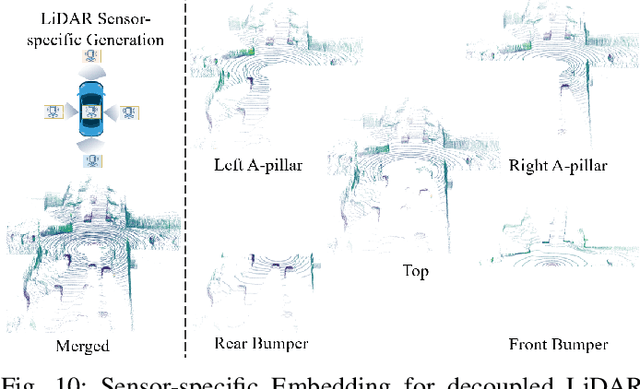

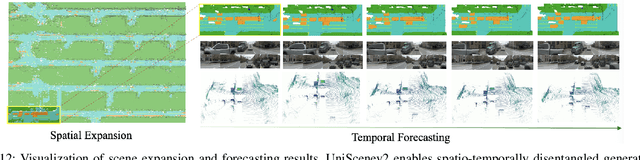
Driving scene generation is a critical domain for autonomous driving, enabling downstream applications, including perception and planning evaluation. Occupancy-centric methods have recently achieved state-of-the-art results by offering consistent conditioning across frames and modalities; however, their performance heavily depends on annotated occupancy data, which still remains scarce. To overcome this limitation, we curate Nuplan-Occ, the largest semantic occupancy dataset to date, constructed from the widely used Nuplan benchmark. Its scale and diversity facilitate not only large-scale generative modeling but also autonomous driving downstream applications. Based on this dataset, we develop a unified framework that jointly synthesizes high-quality semantic occupancy, multi-view videos, and LiDAR point clouds. Our approach incorporates a spatio-temporal disentangled architecture to support high-fidelity spatial expansion and temporal forecasting of 4D dynamic occupancy. To bridge modal gaps, we further propose two novel techniques: a Gaussian splatting-based sparse point map rendering strategy that enhances multi-view video generation, and a sensor-aware embedding strategy that explicitly models LiDAR sensor properties for realistic multi-LiDAR simulation. Extensive experiments demonstrate that our method achieves superior generation fidelity and scalability compared to existing approaches, and validates its practical value in downstream tasks. Repo: https://github.com/Arlo0o/UniScene-Unified-Occupancy-centric-Driving-Scene-Generation/tree/v2
Direct Training Needs Regularisation: Anytime Optimal Inference Spiking Neural Network
Apr 15, 2024



Spiking Neural Network (SNN) is acknowledged as the next generation of Artificial Neural Network (ANN) and hold great promise in effectively processing spatial-temporal information. However, the choice of timestep becomes crucial as it significantly impacts the accuracy of the neural network training. Specifically, a smaller timestep indicates better performance in efficient computing, resulting in reduced latency and operations. While, using a small timestep may lead to low accuracy due to insufficient information presentation with few spikes. This observation motivates us to develop an SNN that is more reliable for adaptive timestep by introducing a novel regularisation technique, namely Spatial-Temporal Regulariser (STR). Our approach regulates the ratio between the strength of spikes and membrane potential at each timestep. This effectively balances spatial and temporal performance during training, ultimately resulting in an Anytime Optimal Inference (AOI) SNN. Through extensive experiments on frame-based and event-based datasets, our method, in combination with cutoff based on softmax output, achieves state-of-the-art performance in terms of both latency and accuracy. Notably, with STR and cutoff, SNN achieves 2.14 to 2.89 faster in inference compared to the pre-configured timestep with near-zero accuracy drop of 0.50% to 0.64% over the event-based datasets. Code available: https://github.com/Dengyu-Wu/AOI-SNN-Regularisation
Self-Adapting Large Visual-Language Models to Edge Devices across Visual Modalities
Mar 07, 2024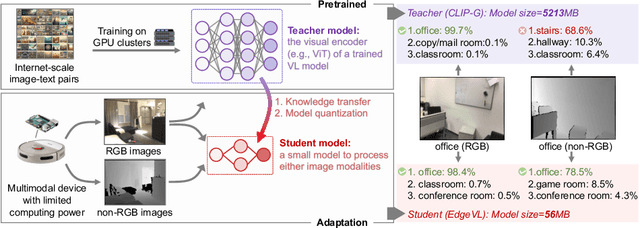
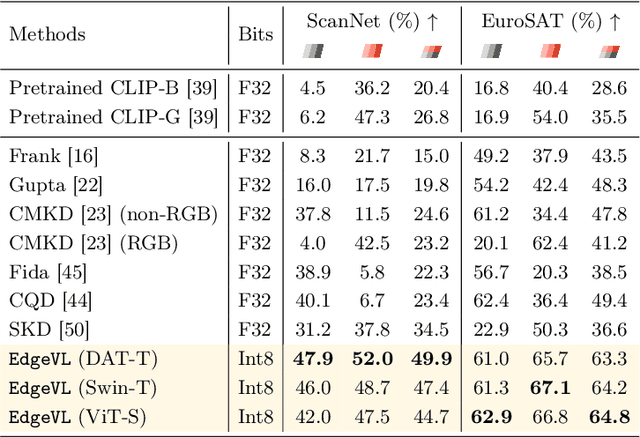
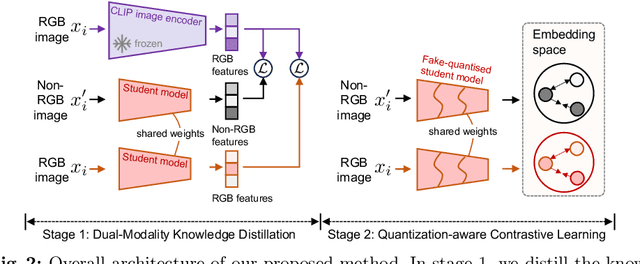

Recent advancements in Vision-Language (VL) models have sparked interest in their deployment on edge devices, yet challenges in handling diverse visual modalities, manual annotation, and computational constraints remain. We introduce EdgeVL, a novel framework that bridges this gap by seamlessly integrating dual-modality knowledge distillation and quantization-aware contrastive learning. This approach enables the adaptation of large VL models, like CLIP, for efficient use with both RGB and non-RGB images on resource-limited devices without the need for manual annotations. EdgeVL not only transfers visual language alignment capabilities to compact models but also maintains feature quality post-quantization, significantly enhancing open-vocabulary classification performance across various visual modalities. Our work represents the first systematic effort to adapt large VL models for edge deployment, showcasing up to 15.4% accuracy improvements on multiple datasets and up to 93-fold reduction in model size.
Risk Controlled Image Retrieval
Jul 14, 2023



Most image retrieval research focuses on improving predictive performance, but they may fall short in scenarios where the reliability of the prediction is crucial. Though uncertainty quantification can help by assessing uncertainty for query and database images, this method can provide only a heuristic estimate rather than an guarantee. To address these limitations, we present Risk Controlled Image Retrieval (RCIR), which generates retrieval sets that are guaranteed to contain the ground truth samples with a predefined probability. RCIR can be easily plugged into any image retrieval method, agnostic to data distribution and model selection. To the best of our knowledge, this is the first work that provides coverage guarantees for image retrieval. The validity and efficiency of RCIR is demonstrated on four real-world image retrieval datasets, including the Stanford CAR-196 (Krause et al. 2013), CUB-200 (Wah et al. 2011), the Pittsburgh dataset (Torii et al. 2013) and the ChestX-Det dataset (Lian et al. 2021).
Robust Human Detection under Visual Degradation via Thermal and mmWave Radar Fusion
Jul 07, 2023The majority of human detection methods rely on the sensor using visible lights (e.g., RGB cameras) but such sensors are limited in scenarios with degraded vision conditions. In this paper, we present a multimodal human detection system that combines portable thermal cameras and single-chip mmWave radars. To mitigate the noisy detection features caused by the low contrast of thermal cameras and the multi-path noise of radar point clouds, we propose a Bayesian feature extractor and a novel uncertainty-guided fusion method that surpasses a variety of competing methods, either single-modal or multi-modal. We evaluate the proposed method on real-world data collection and demonstrate that our approach outperforms the state-of-the-art methods by a large margin.
A Survey of Safety and Trustworthiness of Large Language Models through the Lens of Verification and Validation
May 19, 2023



Large Language Models (LLMs) have exploded a new heatwave of AI, for their ability to engage end-users in human-level conversations with detailed and articulate answers across many knowledge domains. In response to their fast adoption in many industrial applications, this survey concerns their safety and trustworthiness. First, we review known vulnerabilities of the LLMs, categorising them into inherent issues, intended attacks, and unintended bugs. Then, we consider if and how the Verification and Validation (V&V) techniques, which have been widely developed for traditional software and deep learning models such as convolutional neural networks, can be integrated and further extended throughout the lifecycle of the LLMs to provide rigorous analysis to the safety and trustworthiness of LLMs and their applications. Specifically, we consider four complementary techniques: falsification and evaluation, verification, runtime monitoring, and ethical use. Considering the fast development of LLMs, this survey does not intend to be complete (although it includes 300 references), especially when it comes to the applications of LLMs in various domains, but rather a collection of organised literature reviews and discussions to support the quick understanding of the safety and trustworthiness issues from the perspective of V&V.
Exploring Cross-Point Embeddings for 3D Dense Uncertainty Estimation
Sep 29, 2022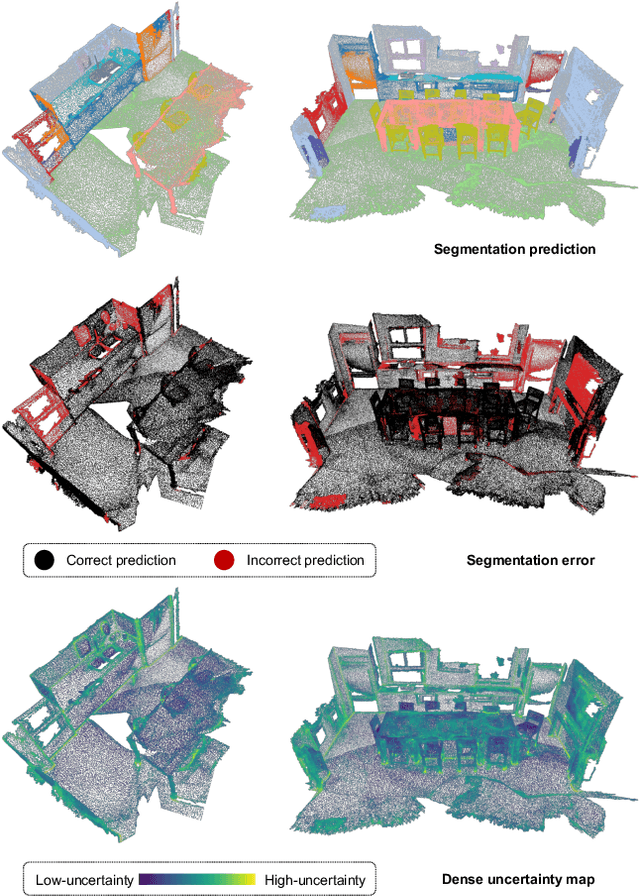
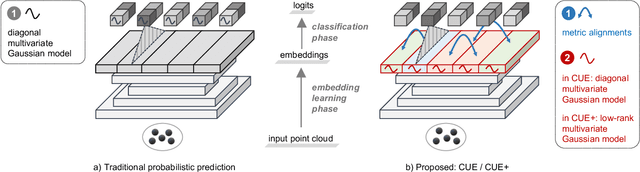
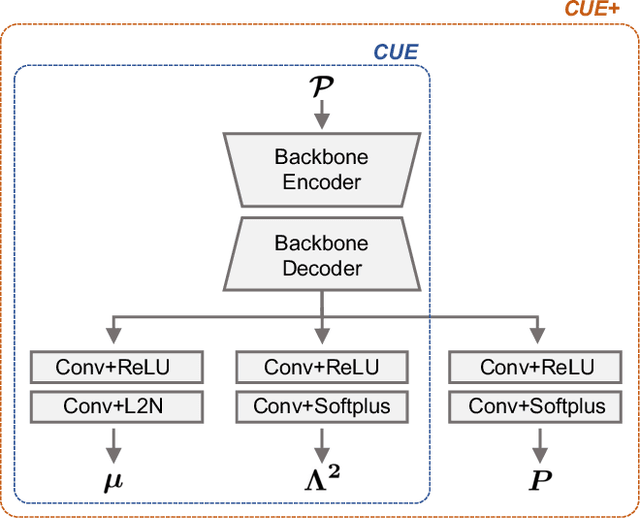
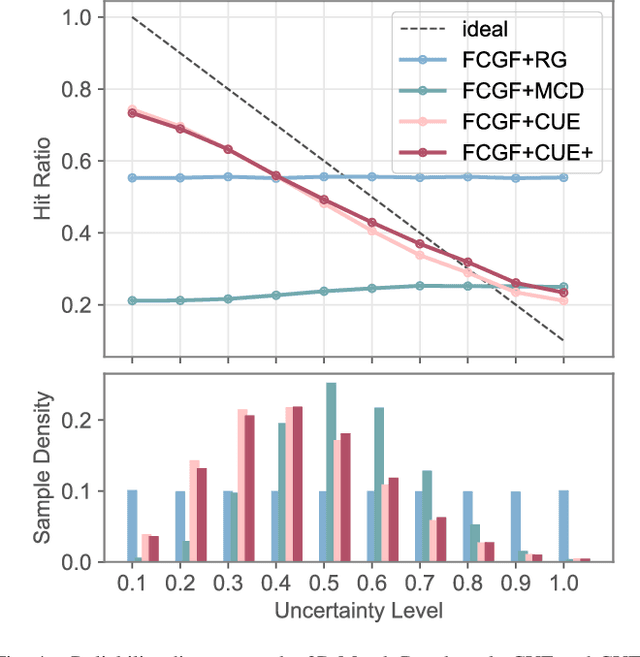
Dense prediction tasks are common for 3D point clouds, but the inherent uncertainties in massive points and their embeddings have long been ignored. In this work, we present CUE, a novel uncertainty estimation method for dense prediction tasks of 3D point clouds. Inspired by metric learning, the key idea of CUE is to explore cross-point embeddings upon a conventional dense prediction pipeline. Specifically, CUE involves building a probabilistic embedding model and then enforcing metric alignments of massive points in the embedding space. We demonstrate that CUE is a generic and effective tool for dense uncertainty estimation of 3D point clouds in two different tasks: (1) in 3D geometric feature learning we for the first time obtain well-calibrated dense uncertainty, and (2) in semantic segmentation we reduce uncertainty`s Expected Calibration Error of the state-of-the-arts by 43.8%. All uncertainties are estimated without compromising predictive performance.
OdomBeyondVision: An Indoor Multi-modal Multi-platform Odometry Dataset Beyond the Visible Spectrum
Jun 03, 2022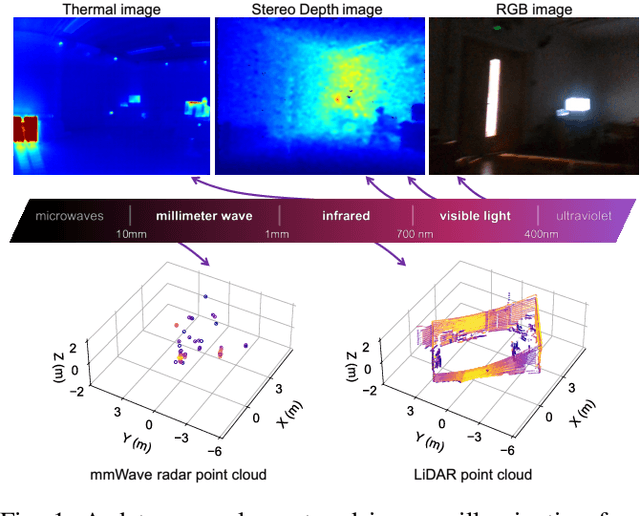
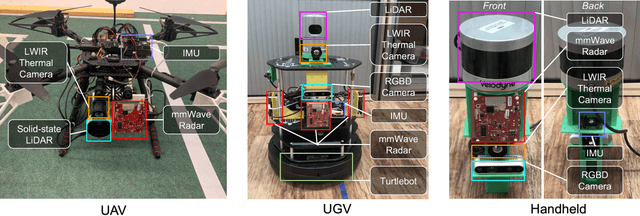


This paper presents a multimodal indoor odometry dataset, OdomBeyondVision, featuring multiple sensors across the different spectrum and collected with different mobile platforms. Not only does OdomBeyondVision contain the traditional navigation sensors, sensors such as IMUs, mechanical LiDAR, RGBD camera, it also includes several emerging sensors such as the single-chip mmWave radar, LWIR thermal camera and solid-state LiDAR. With the above sensors on UAV, UGV and handheld platforms, we respectively recorded the multimodal odometry data and their movement trajectories in various indoor scenes and different illumination conditions. We release the exemplar radar, radar-inertial and thermal-inertial odometry implementations to demonstrate their results for future works to compare against and improve upon. The full dataset including toolkit and documentation is publicly available at: https://github.com/MAPS-Lab/OdomBeyondVision.
STUN: Self-Teaching Uncertainty Estimation for Place Recognition
Mar 03, 2022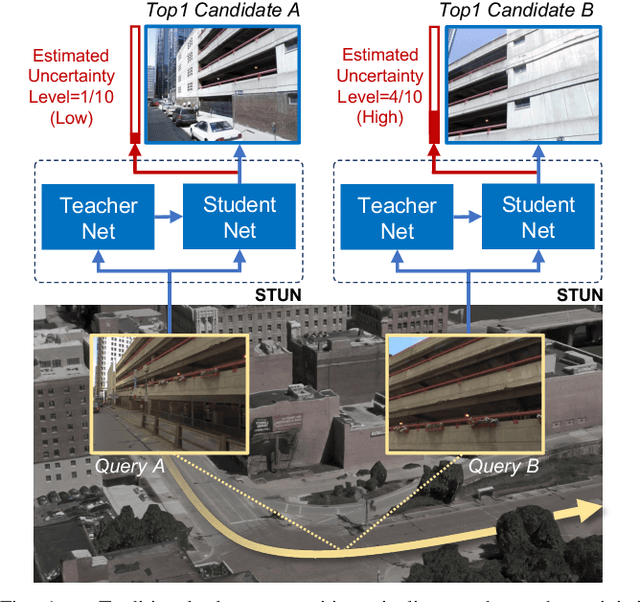

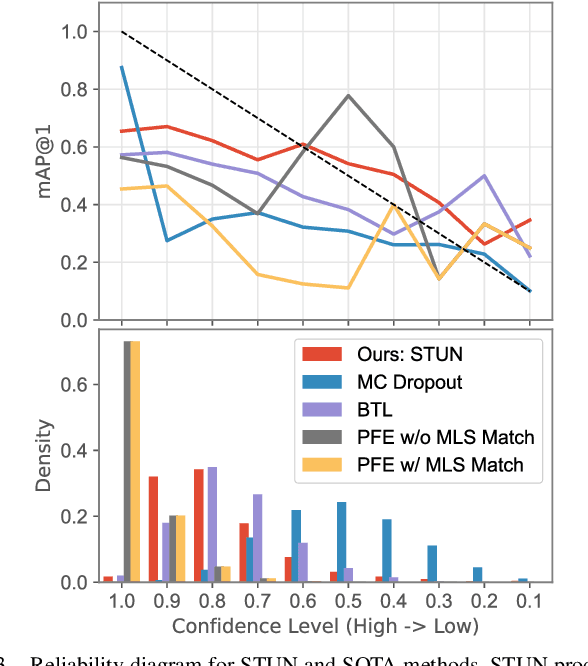
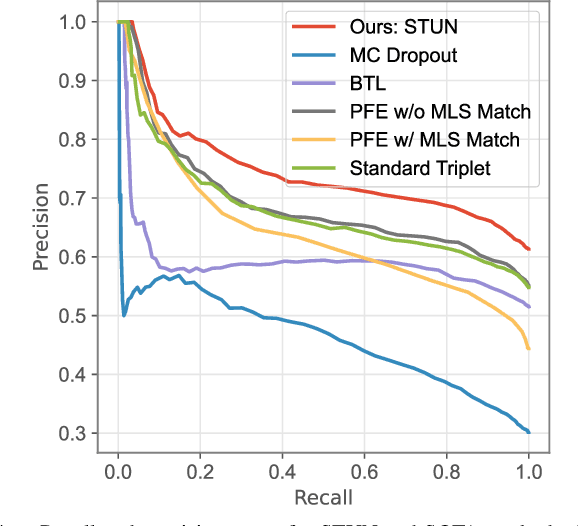
Place recognition is key to Simultaneous Localization and Mapping (SLAM) and spatial perception. However, a place recognition in the wild often suffers from erroneous predictions due to image variations, e.g., changing viewpoints and street appearance. Integrating uncertainty estimation into the life cycle of place recognition is a promising method to mitigate the impact of variations on place recognition performance. However, existing uncertainty estimation approaches in this vein are either computationally inefficient (e.g., Monte Carlo dropout) or at the cost of dropped accuracy. This paper proposes STUN, a self-teaching framework that learns to simultaneously predict the place and estimate the prediction uncertainty given an input image. To this end, we first train a teacher net using a standard metric learning pipeline to produce embedding priors. Then, supervised by the pretrained teacher net, a student net with an additional variance branch is trained to finetune the embedding priors and estimate the uncertainty sample by sample. During the online inference phase, we only use the student net to generate a place prediction in conjunction with the uncertainty. When compared with place recognition systems that are ignorant to the uncertainty, our framework features the uncertainty estimation for free without sacrificing any prediction accuracy. Our experimental results on the large-scale Pittsburgh30k dataset demonstrate that STUN outperforms the state-of-the-art methods in both recognition accuracy and the quality of uncertainty estimation.