 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSignVLA: A Gloss-Free Vision-Language-Action Framework for Real-Time Sign Language-Guided Robotic Manipulation
Feb 26, 2026We present, to our knowledge, the first sign language-driven Vision-Language-Action (VLA) framework for intuitive and inclusive human-robot interaction. Unlike conventional approaches that rely on gloss annotations as intermediate supervision, the proposed system adopts a gloss-free paradigm and directly maps visual sign gestures to semantic instructions. This design reduces annotation cost and avoids the information loss introduced by gloss representations, enabling more natural and scalable multimodal interaction. In this work, we focus on a real-time alphabet-level finger-spelling interface that provides a robust and low-latency communication channel for robotic control. Compared with large-scale continuous sign language recognition, alphabet-level interaction offers improved reliability, interpretability, and deployment feasibility in safety-critical embodied environments. The proposed pipeline transforms continuous gesture streams into coherent language commands through geometric normalization, temporal smoothing, and lexical refinement, ensuring stable and consistent interaction. Furthermore, the framework is designed to support future integration of transformer-based gloss-free sign language models, enabling scalable word-level and sentence-level semantic understanding. Experimental results demonstrate the effectiveness of the proposed system in grounding sign-derived instructions into precise robotic actions under diverse interaction scenarios. These results highlight the potential of the framework to advance accessible, scalable, and multimodal embodied intelligence.
Fast ECoT: Efficient Embodied Chain-of-Thought via Thoughts Reuse
Jun 09, 2025Embodied Chain-of-Thought (ECoT) reasoning enhances vision-language-action (VLA) models by improving performance and interpretability through intermediate reasoning steps. However, its sequential autoregressive token generation introduces significant inference latency, limiting real-time deployment. We propose Fast ECoT, an inference-time acceleration method that exploits the structured and repetitive nature of ECoT to (1) cache and reuse high-level reasoning across timesteps and (2) parallelise the generation of modular reasoning steps. Additionally, we introduce an asynchronous scheduler that decouples reasoning from action decoding, further boosting responsiveness. Fast ECoT requires no model changes or additional training and integrates easily into existing VLA pipelines. Experiments in both simulation (LIBERO) and real-world robot tasks show up to a 7.5% reduction in latency with comparable or improved task success rate and reasoning faithfulness, bringing ECoT policies closer to practical real-time deployment.
Self-Adapting Large Visual-Language Models to Edge Devices across Visual Modalities
Mar 07, 2024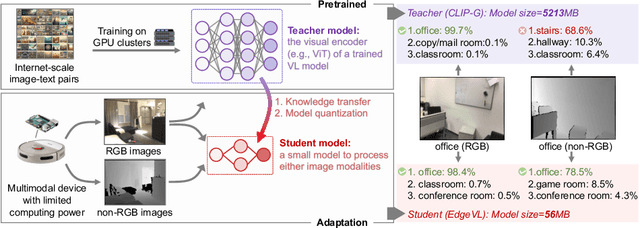
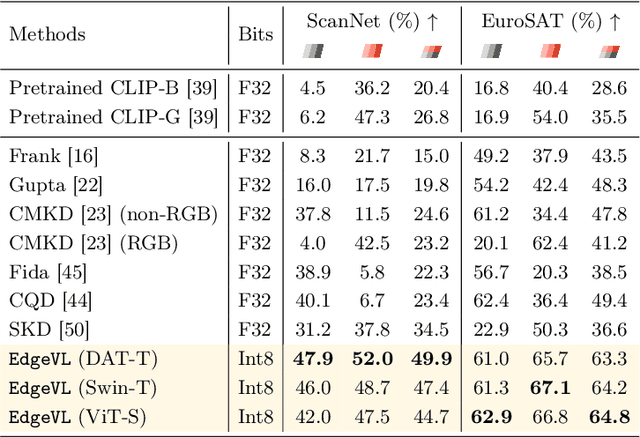
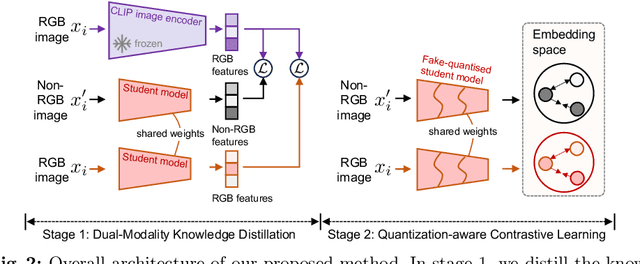

Recent advancements in Vision-Language (VL) models have sparked interest in their deployment on edge devices, yet challenges in handling diverse visual modalities, manual annotation, and computational constraints remain. We introduce EdgeVL, a novel framework that bridges this gap by seamlessly integrating dual-modality knowledge distillation and quantization-aware contrastive learning. This approach enables the adaptation of large VL models, like CLIP, for efficient use with both RGB and non-RGB images on resource-limited devices without the need for manual annotations. EdgeVL not only transfers visual language alignment capabilities to compact models but also maintains feature quality post-quantization, significantly enhancing open-vocabulary classification performance across various visual modalities. Our work represents the first systematic effort to adapt large VL models for edge deployment, showcasing up to 15.4% accuracy improvements on multiple datasets and up to 93-fold reduction in model size.
Battery-Care Resource Allocation and Task Offloading in Multi-Agent Post-Disaster MEC Environment
Dec 24, 2023



Being an up-and-coming application scenario of mobile edge computing (MEC), the post-disaster rescue suffers multitudinous computing-intensive tasks but unstably guaranteed network connectivity. In rescue environments, quality of service (QoS), such as task execution delay, energy consumption and battery state of health (SoH), is of significant meaning. This paper studies a multi-user post-disaster MEC environment with unstable 5G communication, where device-to-device (D2D) link communication and dynamic voltage and frequency scaling (DVFS) are adopted to balance each user's requirement for task delay and energy consumption. A battery degradation evaluation approach to prolong battery lifetime is also presented. The distributed optimization problem is formulated into a mixed cooperative-competitive (MCC) multi-agent Markov decision process (MAMDP) and is tackled with recurrent multi-agent Proximal Policy Optimization (rMAPPO). Extensive simulations and comprehensive comparisons with other representative algorithms clearly demonstrate the effectiveness of the proposed rMAPPO-based offloading scheme.
InDL: A New Dataset and Benchmark for In-Diagram Logic Interpretation based on Visual Illusion
Jun 05, 2023This paper introduces a novel approach to evaluating deep learning models' capacity for in-diagram logic interpretation. Leveraging the intriguing realm of visual illusions, we establish a unique dataset, InDL, designed to rigorously test and benchmark these models. Deep learning has witnessed remarkable progress in domains such as computer vision and natural language processing. However, models often stumble in tasks requiring logical reasoning due to their inherent 'black box' characteristics, which obscure the decision-making process. Our work presents a new lens to understand these models better by focusing on their handling of visual illusions -- a complex interplay of perception and logic. We utilize six classic geometric optical illusions to create a comparative framework between human and machine visual perception. This methodology offers a quantifiable measure to rank models, elucidating potential weaknesses and providing actionable insights for model improvements. Our experimental results affirm the efficacy of our benchmarking strategy, demonstrating its ability to effectively rank models based on their logic interpretation ability. As part of our commitment to reproducible research, the source code and datasets will be made publicly available at https://github.com/rabbit-magic-wh/InDL
CVSNet: A Computer Implementation for Central Visual System of The Brain
May 31, 2023In computer vision, different basic blocks are created around different matrix operations, and models based on different basic blocks have achieved good results. Good results achieved in vision tasks grants them rationality. However, these experimental-based models also make deep learning long criticized for principle and interpretability. Deep learning originated from the concept of neurons in neuroscience, but recent designs detached natural neural networks except for some simple concepts. In this paper, we build an artificial neural network, CVSNet, which can be seen as a computer implementation for central visual system of the brain. Each block in CVSNet represents the same vision information as that in brains. In CVSNet, blocks differs from each other and visual information flows through three independent pathways and five different blocks. Thus CVSNet is completely different from the design of all previous models, in which basic blocks are repeated to build model and information between channels is mixed at the outset. In ablation experiment, we show the information extracted by blocks in CVSNet and compare with previous networks, proving effectiveness and rationality of blocks in CVSNet from experiment side. And in the experiment of object recognition, CVSNet achieves comparable results to ConvNets, Vision Transformers and MLPs.