 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer Architectures as Complete Bayes Processes: A Formal Proof in the Measure-Theoretic Kernel Framework
Jun 29, 2026We present a complete formal proof that transformer architectures, when their internal update mechanisms satisfy a Bayes joint-distribution condition, implement exact Bayesian posterior inference. Working within the measure-theoretic kernel framework, we define a hierarchy of abstractions -- from the core Bayesian transformer, through semantic transformers with explicit update kernels, to full transformer blocks with QKV/attention/residual/MLP pipelines, and finally multilayer stacks -- and prove at each level that the Bayes joint semantics implies the update kernel equals the posterior almost everywhere. For the block-level architecture, we derive the explicit Bayes formula through Radon-Nikodym differentiation and prove its normalization. We additionally prove that the softmax attention mechanism induces a valid probability distribution over keys, establishing the bridge between the abstract kernel framework and concrete attention implementations. The framework makes no architectural assumptions beyond the Markov kernel structure and exposes explicit conditions under which a transformer block is provably Bayesian. In essence, when this joint distribution condition is satisfied, the forward computation of a Transformer is formally equivalent to a rigorous Bayesian posterior update.
Using Large Language Models as Low-Cost Statistical Estimators for Human-Response Data
Jun 29, 2026Quantitative research across the social and behavioral sciences depends on human subject experiments that are expensive, slow, and subject to sampling bias. Here we show that pretrained large language models induce risk-equivalent estimators of conditional expectations under squared loss, establishing restricted functional risk equivalence: under squared loss, the LLM induces an estimator whose risk matches the Bayes optimal risk for squared-loss prediction of conditional expectations for any inference that depends on the data only through the conditional mean. We formalize the LLM as a misspecified functional estimator $T(\hat{P}_n)$ trained on i.i.d.\ data, decompose the estimation error into representation bias $ε_{\mathrm{rep}}$ and optimization error, and prove that under mild regularity conditions the LLM's expected error converges to the irreducible population variance plus the squared representation bias, with the representation bias bounded by the Pinsker inequality. The identifiability error $δ$ propagates into the effective bias, inflating the asymptotic risk floor. We establish restricted functional risk equivalence via a bidirectional Le Cam deficiency analysis: the forward deficiency vanishes asymptotically while the reverse deficiency is exactly zero. We provide finite-sample concentration bounds and a calibration protocol with explicit decision rules. The result is a precise, provable statement: a well-calibrated LLM achieves the Bayes-optimal risk for conditional-mean-dependent inference, bounded by explicit scope conditions. In practical applications, this means that under satisfied conditions and well-calibrated models, large language models can be used in many prediction and decision-making tasks that originally relied on human experiments, approximating near-optimal statistical inference at lower cost.
Leveraging Geometric Visual Illusions as Perceptual Inductive Biases for Vision Models
Sep 18, 2025Contemporary deep learning models have achieved impressive performance in image classification by primarily leveraging statistical regularities within large datasets, but they rarely incorporate structured insights drawn directly from perceptual psychology. To explore the potential of perceptually motivated inductive biases, we propose integrating classic geometric visual illusions well-studied phenomena from human perception into standard image-classification training pipelines. Specifically, we introduce a synthetic, parametric geometric-illusion dataset and evaluate three multi-source learning strategies that combine illusion recognition tasks with ImageNet classification objectives. Our experiments reveal two key conceptual insights: (i) incorporating geometric illusions as auxiliary supervision systematically improves generalization, especially in visually challenging cases involving intricate contours and fine textures; and (ii) perceptually driven inductive biases, even when derived from synthetic stimuli traditionally considered unrelated to natural image recognition, can enhance the structural sensitivity of both CNN and transformer-based architectures. These results demonstrate a novel integration of perceptual science and machine learning and suggest new directions for embedding perceptual priors into vision model design.
ILRe: Intermediate Layer Retrieval for Context Compression in Causal Language Models
Aug 25, 2025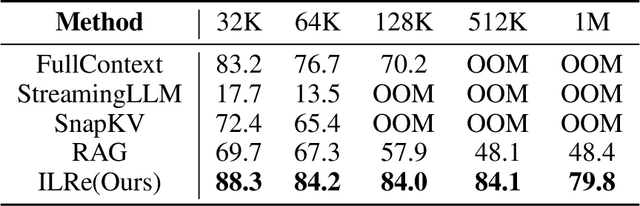
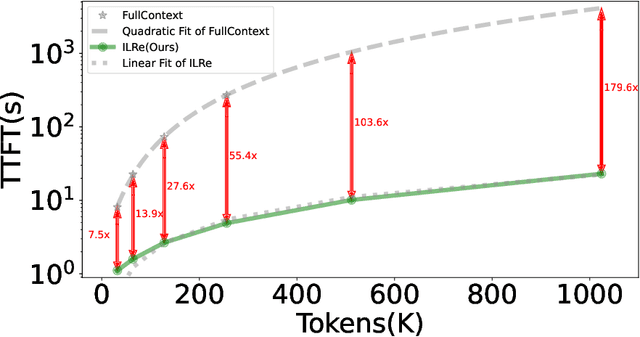
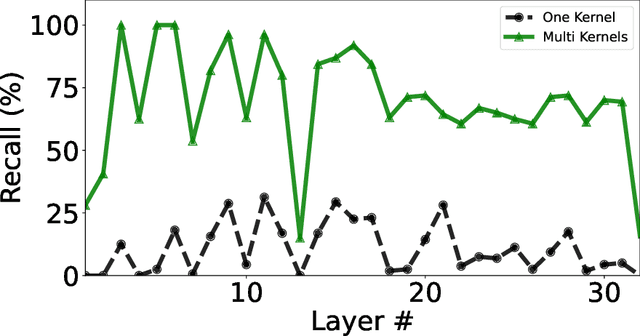
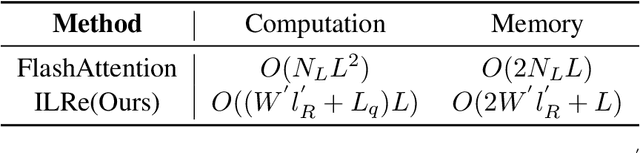
Large Language Models (LLMs) have demonstrated success across many benchmarks. However, they still exhibit limitations in long-context scenarios, primarily due to their short effective context length, quadratic computational complexity, and high memory overhead when processing lengthy inputs. To mitigate these issues, we introduce a novel context compression pipeline, called Intermediate Layer Retrieval (ILRe), which determines one intermediate decoder layer offline, encodes context by streaming chunked prefill only up to that layer, and recalls tokens by the attention scores between the input query and full key cache in that specified layer. In particular, we propose a multi-pooling kernels allocating strategy in the token recalling process to maintain the completeness of semantics. Our approach not only reduces the prefilling complexity from $O(L^2)$ to $O(L)$, but also achieves performance comparable to or better than the full context in the long context scenarios. Without additional post training or operator development, ILRe can process a single $1M$ tokens request in less than half a minute (speedup $\approx 180\times$) and scores RULER-$1M$ benchmark of $\approx 79.8$ with model Llama-3.1-UltraLong-8B-1M-Instruct on a Huawei Ascend 910B NPU.
Gradient-Guided Parameter Mask for Multi-Scenario Image Restoration Under Adverse Weather
Nov 23, 2024


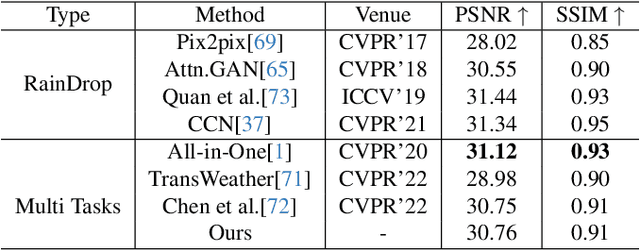
Removing adverse weather conditions such as rain, raindrop, and snow from images is critical for various real-world applications, including autonomous driving, surveillance, and remote sensing. However, existing multi-task approaches typically rely on augmenting the model with additional parameters to handle multiple scenarios. While this enables the model to address diverse tasks, the introduction of extra parameters significantly complicates its practical deployment. In this paper, we propose a novel Gradient-Guided Parameter Mask for Multi-Scenario Image Restoration under adverse weather, designed to effectively handle image degradation under diverse weather conditions without additional parameters. Our method segments model parameters into common and specific components by evaluating the gradient variation intensity during training for each specific weather condition. This enables the model to precisely and adaptively learn relevant features for each weather scenario, improving both efficiency and effectiveness without compromising on performance. This method constructs specific masks based on gradient fluctuations to isolate parameters influenced by other tasks, ensuring that the model achieves strong performance across all scenarios without adding extra parameters. We demonstrate the state-of-the-art performance of our framework through extensive experiments on multiple benchmark datasets. Specifically, our method achieves PSNR scores of 29.22 on the Raindrop dataset, 30.76 on the Rain dataset, and 29.56 on the Snow100K dataset. Code is available at: \href{https://github.com/AierLab/MultiTask}{https://github.com/AierLab/MultiTask}.
Entropy Loss: An Interpretability Amplifier of 3D Object Detection Network for Intelligent Driving
Sep 01, 2024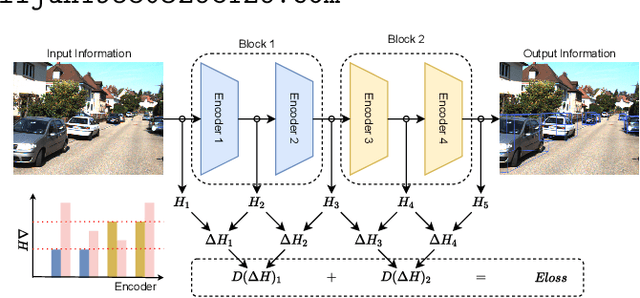
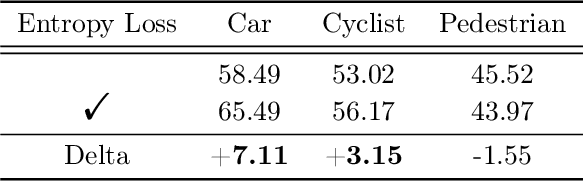
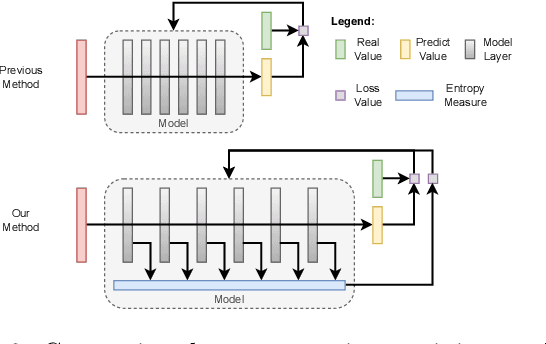
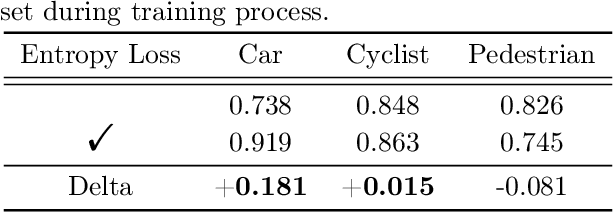
With the increasing complexity of the traffic environment, the significance of safety perception in intelligent driving is intensifying. Traditional methods in the field of intelligent driving perception rely on deep learning, which suffers from limited interpretability, often described as a "black box." This paper introduces a novel type of loss function, termed "Entropy Loss," along with an innovative training strategy. Entropy Loss is formulated based on the functionality of feature compression networks within the perception model. Drawing inspiration from communication systems, the information transmission process in a feature compression network is expected to demonstrate steady changes in information volume and a continuous decrease in information entropy. By modeling network layer outputs as continuous random variables, we construct a probabilistic model that quantifies changes in information volume. Entropy Loss is then derived based on these expectations, guiding the update of network parameters to enhance network interpretability. Our experiments indicate that the Entropy Loss training strategy accelerates the training process. Utilizing the same 60 training epochs, the accuracy of 3D object detection models using Entropy Loss on the KITTI test set improved by up to 4.47\% compared to models without Entropy Loss, underscoring the method's efficacy. The implementation code is available at \url{https://github.com/yhbcode000/Eloss-Interpretability}.
InDL: A New Dataset and Benchmark for In-Diagram Logic Interpretation based on Visual Illusion
Jun 05, 2023This paper introduces a novel approach to evaluating deep learning models' capacity for in-diagram logic interpretation. Leveraging the intriguing realm of visual illusions, we establish a unique dataset, InDL, designed to rigorously test and benchmark these models. Deep learning has witnessed remarkable progress in domains such as computer vision and natural language processing. However, models often stumble in tasks requiring logical reasoning due to their inherent 'black box' characteristics, which obscure the decision-making process. Our work presents a new lens to understand these models better by focusing on their handling of visual illusions -- a complex interplay of perception and logic. We utilize six classic geometric optical illusions to create a comparative framework between human and machine visual perception. This methodology offers a quantifiable measure to rank models, elucidating potential weaknesses and providing actionable insights for model improvements. Our experimental results affirm the efficacy of our benchmarking strategy, demonstrating its ability to effectively rank models based on their logic interpretation ability. As part of our commitment to reproducible research, the source code and datasets will be made publicly available at https://github.com/rabbit-magic-wh/InDL
Eloss in the way: A Sensitive Input Quality Metrics for Intelligent Driving
Feb 02, 2023With the increasing complexity of the traffic environment, the importance of safety perception in intelligent driving is growing. Conventional methods in the robust perception of intelligent driving focus on training models with anomalous data, letting the deep neural network decide how to tackle anomalies. However, these models cannot adapt smoothly to the diverse and complex real-world environment. This paper proposes a new type of metric known as Eloss and offers a novel training strategy to empower perception models from the aspect of anomaly detection. Eloss is designed based on an explanation of the perception model's information compression layers. Specifically, taking inspiration from the design of a communication system, the information transmission process of an information compression network has two expectations: the amount of information changes steadily, and the information entropy continues to decrease. Then Eloss can be obtained according to the above expectations, guiding the update of related network parameters and producing a sensitive metric to identify anomalies while maintaining the model performance. Our experiments demonstrate that Eloss can deviate from the standard value by a factor over 100 with anomalous data and produce distinctive values for similar but different types of anomalies, showing the effectiveness of the proposed method. Our code is available at: (code available after paper accepted).