 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoarse-to-Fine Domain Incremental Learning with Attentive Distillation for Mining Footprint Segmentation in Multispectral Imagery
May 28, 2026Automatically mapping and segmenting global mining footprints using remote sensing and deep learning is critical for monitoring the socio-environmental risks and impacts of mining, yet its progress is hindered by the scarcity of fine-grained annotated data. Although large-scale datasets with coarse boundaries are widely available, leveraging them to improve fine-grained segmentation is challenging due to significant domain shift. To address this, we propose MineC2FNet, a coarse-to-fine domain incremental learning framework that exploits abundant coarse data to enhance fine-grained mining footprint segmentation. MineC2FNet adopts a teacher-student architecture with attentive distillation at both the feature and prediction levels, selectively transferring generalized knowledge from the coarse domain while enabling boundary refinement using limited fine-grained data (fine domain). We further introduce an expertly validated dataset of 219 images with precise boundary annotations across diverse geographies and commodities. Extensive experiments against state-of-the-art approaches, including domain adaptation and domain incremental learning methods, demonstrate that MineC2FNet achieves superior performance while effectively handling domain shift. The dataset and code are publicly available at https://github.com/risqiutama/MineC2FNet.
Progressive Cross Attention Network for Flood Segmentation using Multispectral Satellite Imagery
Jan 21, 2025



In recent years, the integration of deep learning techniques with remote sensing technology has revolutionized the way natural hazards, such as floods, are monitored and managed. However, existing methods for flood segmentation using remote sensing data often overlook the utility of correlative features among multispectral satellite information. In this study, we introduce a progressive cross attention network (ProCANet), a deep learning model that progressively applies both self- and cross-attention mechanisms to multispectral features, generating optimal feature combinations for flood segmentation. The proposed model was compared with state-of-the-art approaches using Sen1Floods11 dataset and our bespoke flood data generated for the Citarum River basin, Indonesia. Our model demonstrated superior performance with the highest Intersection over Union (IoU) score of 0.815. Our results in this study, coupled with the ablation assessment comparing scenarios with and without attention across various modalities, opens a promising path for enhancing the accuracy of flood analysis using remote sensing technology.
* 5 pages, 4 figures, published in IEEE Geoscience and Remote Sensing Letters
OdomBeyondVision: An Indoor Multi-modal Multi-platform Odometry Dataset Beyond the Visible Spectrum
Jun 03, 2022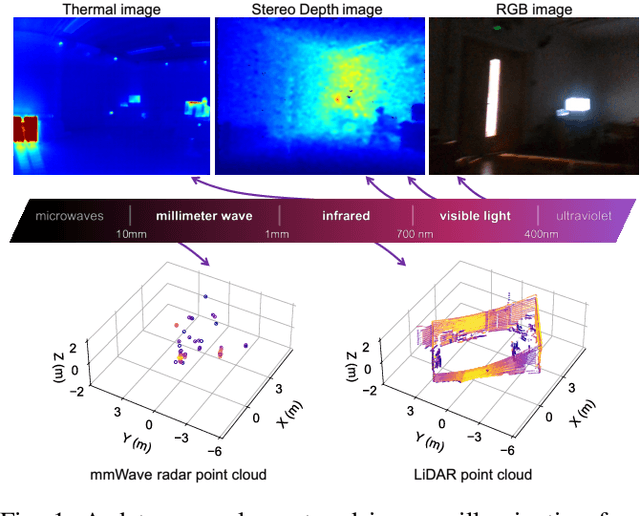
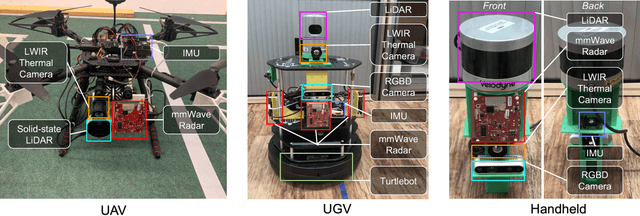


This paper presents a multimodal indoor odometry dataset, OdomBeyondVision, featuring multiple sensors across the different spectrum and collected with different mobile platforms. Not only does OdomBeyondVision contain the traditional navigation sensors, sensors such as IMUs, mechanical LiDAR, RGBD camera, it also includes several emerging sensors such as the single-chip mmWave radar, LWIR thermal camera and solid-state LiDAR. With the above sensors on UAV, UGV and handheld platforms, we respectively recorded the multimodal odometry data and their movement trajectories in various indoor scenes and different illumination conditions. We release the exemplar radar, radar-inertial and thermal-inertial odometry implementations to demonstrate their results for future works to compare against and improve upon. The full dataset including toolkit and documentation is publicly available at: https://github.com/MAPS-Lab/OdomBeyondVision.
Deep Odometry Systems on Edge with EKF-LoRa Backend for Real-Time Positioning in Adverse Environment
Dec 10, 2021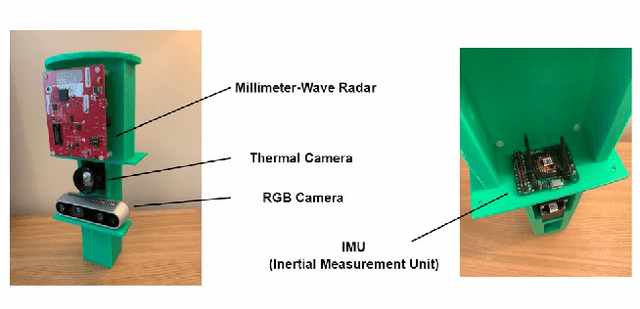
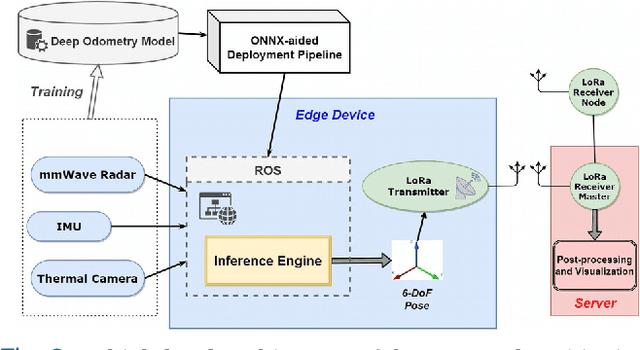

Ubiquitous positioning for pedestrian in adverse environment has served a long standing challenge. Despite dramatic progress made by Deep Learning, multi-sensor deep odometry systems yet pose a high computational cost and suffer from cumulative drifting errors over time. Thanks to the increasing computational power of edge devices, we propose a novel ubiquitous positioning solution by integrating state-of-the-art deep odometry models on edge with an EKF (Extended Kalman Filter)-LoRa backend. We carefully compare and select three sensor modalities, i.e., an Inertial Measurement Unit (IMU), a millimetre-wave (mmWave) radar, and a thermal infrared camera, and realise their deep odometry inference engines which runs in real-time. A pipeline of deploying deep odometry considering accuracy, complexity, and edge platform is proposed. We design a LoRa link for positional data backhaul and projecting aggregated positions of deep odometry into the global frame. We find that a simple EKF based fusion module is sufficient for generic positioning calibration with over 34% accuracy gains against any standalone deep odometry system. Extensive tests in different environments validate the efficiency and efficacy of our proposed positioning system.
RADA: Robust Adversarial Data Augmentation for Camera Localization in Challenging Weather
Dec 05, 2021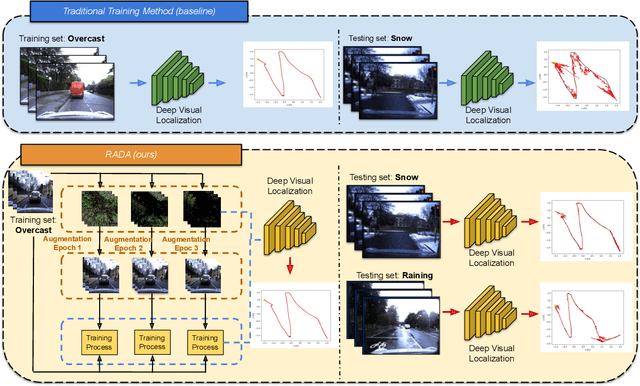
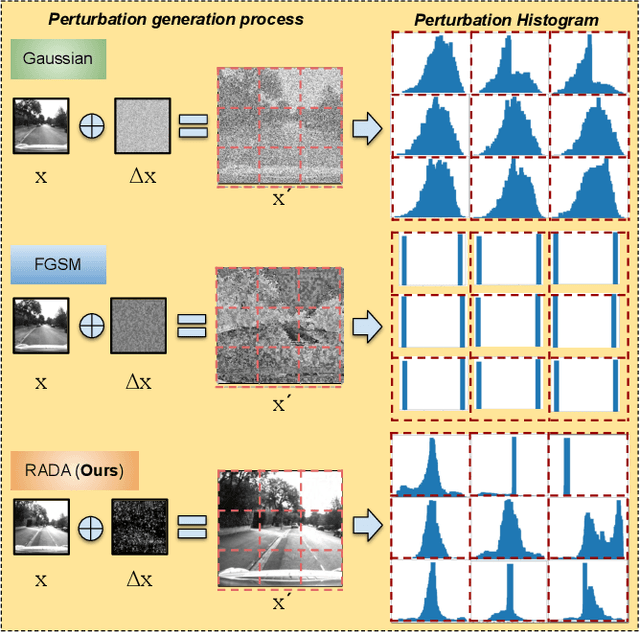
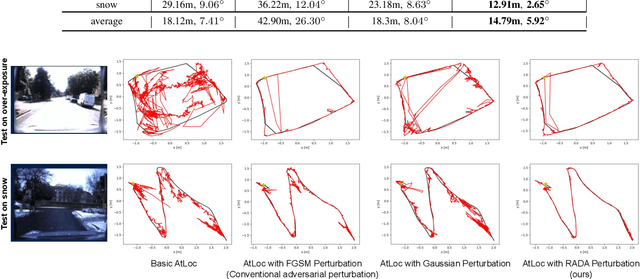

Camera localization is a fundamental and crucial problem for many robotic applications. In recent years, using deep-learning for camera-based localization has become a popular research direction. However, they lack robustness to large domain shifts, which can be caused by seasonal or illumination changes between training and testing data sets. Data augmentation is an attractive approach to tackle this problem, as it does not require additional data to be provided. However, existing augmentation methods blindly perturb all pixels and therefore cannot achieve satisfactory performance. To overcome this issue, we proposed RADA, a system whose aim is to concentrate on perturbing the geometrically informative parts of the image. As a result, it learns to generate minimal image perturbations that are still capable of perplexing the network. We show that when these examples are utilized as augmentation, it greatly improves robustness. We show that our method outperforms previous augmentation techniques and achieves up to two times higher accuracy than the SOTA localization models (e.g., AtLoc and MapNet) when tested on `unseen' challenging weather conditions.
Graph-based Thermal-Inertial SLAM with Probabilistic Neural Networks
Apr 18, 2021
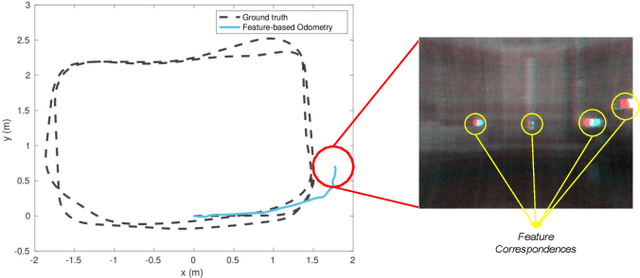

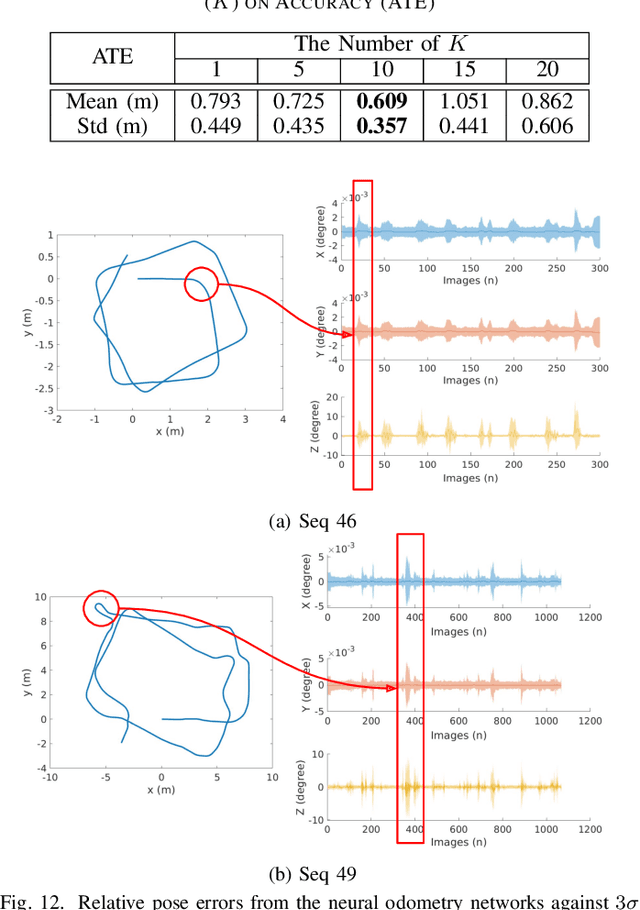
Simultaneous Localization and Mapping (SLAM) system typically employ vision-based sensors to observe the surrounding environment. However, the performance of such systems highly depends on the ambient illumination conditions. In scenarios with adverse visibility or in the presence of airborne particulates (e.g. smoke, dust, etc.), alternative modalities such as those based on thermal imaging and inertial sensors are more promising. In this paper, we propose the first complete thermal-inertial SLAM system which combines neural abstraction in the SLAM front end with robust pose graph optimization in the SLAM back end. We model the sensor abstraction in the front end by employing probabilistic deep learning parameterized by Mixture Density Networks (MDN). Our key strategies to successfully model this encoding from thermal imagery are the usage of normalized 14-bit radiometric data, the incorporation of hallucinated visual (RGB) features, and the inclusion of feature selection to estimate the MDN parameters. To enable a full SLAM system, we also design an efficient global image descriptor which is able to detect loop closures from thermal embedding vectors. We performed extensive experiments and analysis using three datasets, namely self-collected ground robot and handheld data taken in indoor environment, and one public dataset (SubT-tunnel) collected in underground tunnel. Finally, we demonstrate that an accurate thermal-inertial SLAM system can be realized in conditions of both benign and adverse visibility.
Demo Abstract: Indoor Positioning System in Visually-Degraded Environments with Millimetre-Wave Radar and Inertial Sensors
Oct 26, 2020
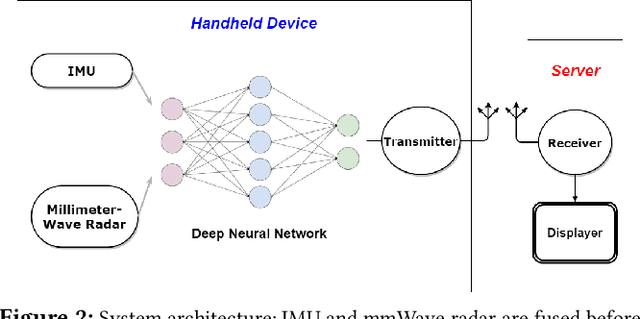
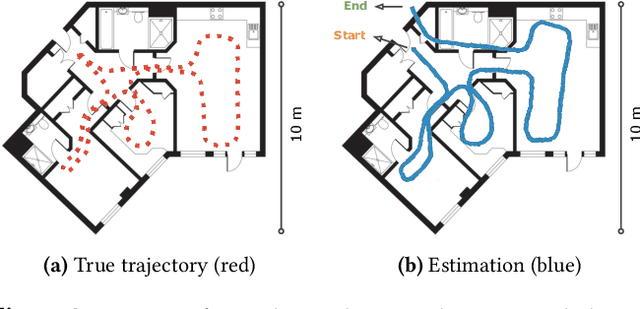
Positional estimation is of great importance in the public safety sector. Emergency responders such as fire fighters, medical rescue teams, and the police will all benefit from a resilient positioning system to deliver safe and effective emergency services. Unfortunately, satellite navigation (e.g., GPS) offers limited coverage in indoor environments. It is also not possible to rely on infrastructure based solutions. To this end, wearable sensor-aided navigation techniques, such as those based on camera and Inertial Measurement Units (IMU), have recently emerged recently as an accurate, infrastructure-free solution. Together with an increase in the computational capabilities of mobile devices, motion estimation can be performed in real-time. In this demonstration, we present a real-time indoor positioning system which fuses millimetre-wave (mmWave) radar and IMU data via deep sensor fusion. We employ mmWave radar rather than an RGB camera as it provides better robustness to visual degradation (e.g., smoke, darkness, etc.) while at the same time requiring lower computational resources to enable runtime computation. We implemented the sensor system on a handheld device and a mobile computer running at 10 FPS to track a user inside an apartment. Good accuracy and resilience were exhibited even in poorly illuminated scenes.
milliEgo: mmWave Aided Egomotion Estimation with Deep Sensor Fusion
Jun 03, 2020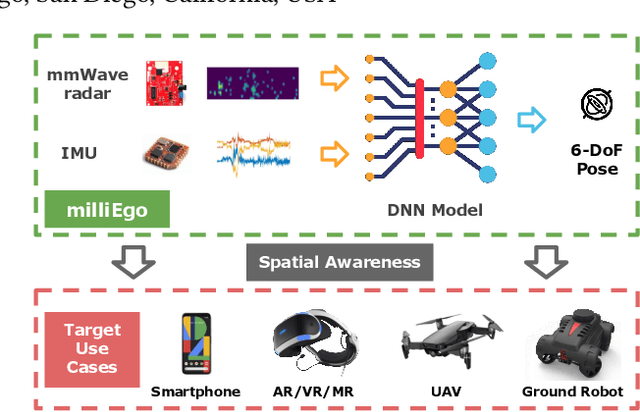
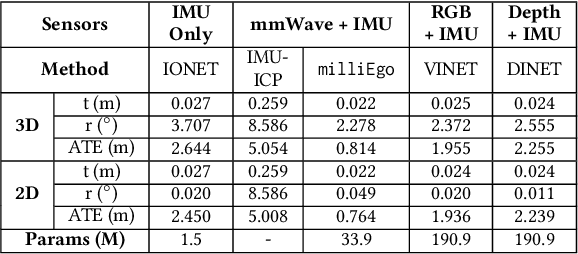
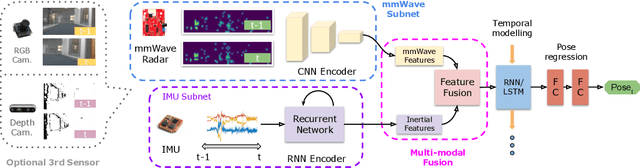
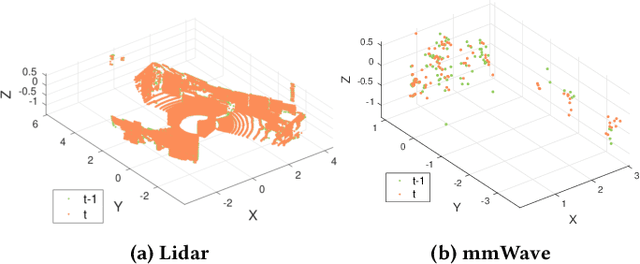
Robust and accurate trajectory estimation of mobile agents such as people and robots is a key requirement for providing spatial awareness to emerging capabilities such as augmented reality or autonomous interaction. Although currently dominated by vision based techniques e.g., visual-inertial odometry, these suffer from challenges with scene illumination or featureless surfaces. As an alternative, we propose \sysname, a novel deep-learning approach to robust egomotion estimation which exploits the capabilities of low-cost mmWave radar. Although mmWave radar has a fundamental advantage over monocular cameras of being metric i.e., providing absolute scale or depth, current single chip solutions have limited and sparse imaging resolution, making existing point-cloud registration techniques brittle. We propose a new architecture that is optimized for solving this underdetermined pose transformation problem. Secondly, to robustly fuse mmWave pose estimates with additional sensors, e.g. inertial or visual sensor we introduce a mixed attention approach to deep fusion. Through extensive experiments, we demonstrate how mmWave radar outperforms existing state-of-the-art odometry techniques. We also show that the neural architecture can be made highly efficient and suitable for real-time embedded applications.
SelfVIO: Self-Supervised Deep Monocular Visual-Inertial Odometry and Depth Estimation
Nov 22, 2019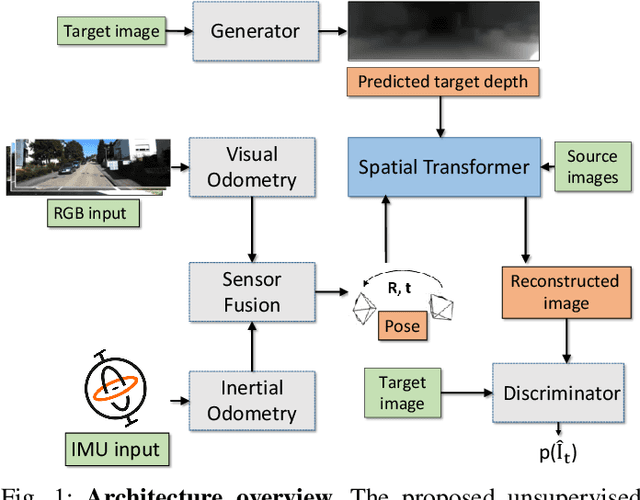
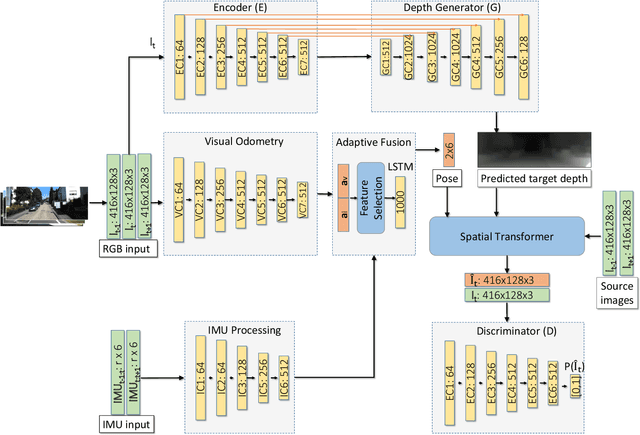
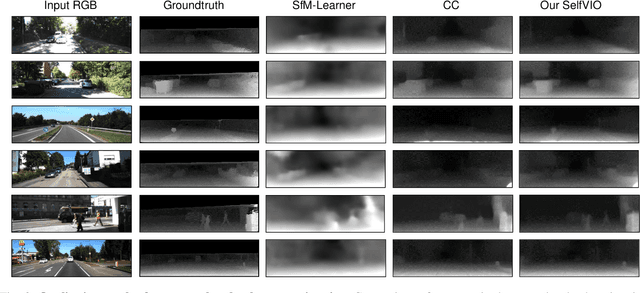

In the last decade, numerous supervised deep learning approaches requiring large amounts of labeled data have been proposed for visual-inertial odometry (VIO) and depth map estimation. To overcome the data limitation, self-supervised learning has emerged as a promising alternative, exploiting constraints such as geometric and photometric consistency in the scene. In this study, we introduce a novel self-supervised deep learning-based VIO and depth map recovery approach (SelfVIO) using adversarial training and self-adaptive visual-inertial sensor fusion. SelfVIO learns to jointly estimate 6 degrees-of-freedom (6-DoF) ego-motion and a depth map of the scene from unlabeled monocular RGB image sequences and inertial measurement unit (IMU) readings. The proposed approach is able to perform VIO without the need for IMU intrinsic parameters and/or the extrinsic calibration between the IMU and the camera. estimation and single-view depth recovery network. We provide comprehensive quantitative and qualitative evaluations of the proposed framework comparing its performance with state-of-the-art VIO, VO, and visual simultaneous localization and mapping (VSLAM) approaches on the KITTI, EuRoC and Cityscapes datasets. Detailed comparisons prove that SelfVIO outperforms state-of-the-art VIO approaches in terms of pose estimation and depth recovery, making it a promising approach among existing methods in the literature.
DeepPCO: End-to-End Point Cloud Odometry through Deep Parallel Neural Network
Oct 13, 2019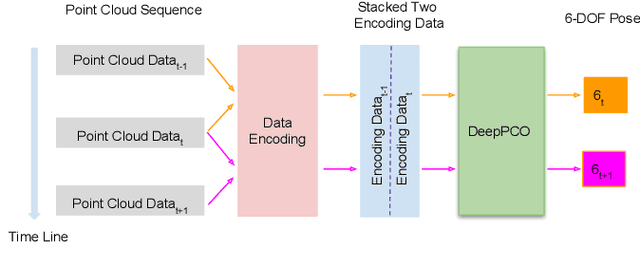
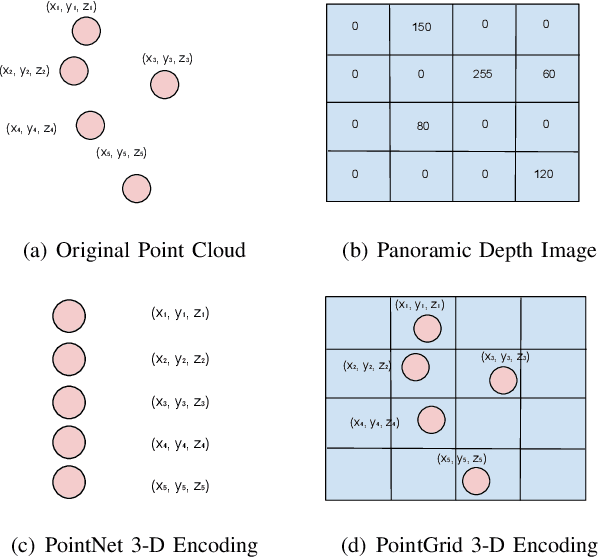
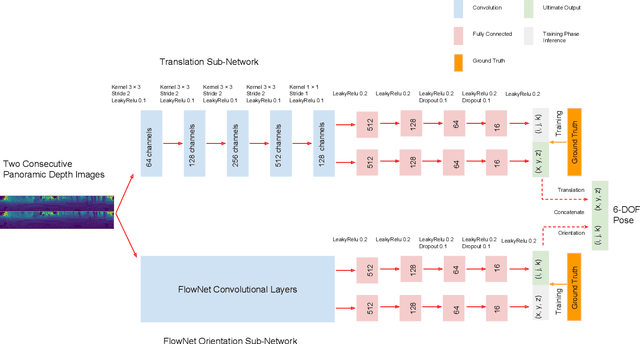
Odometry is of key importance for localization in the absence of a map. There is considerable work in the area of visual odometry (VO), and recent advances in deep learning have brought novel approaches to VO, which directly learn salient features from raw images. These learning-based approaches have led to more accurate and robust VO systems. However, they have not been well applied to point cloud data yet. In this work, we investigate how to exploit deep learning to estimate point cloud odometry (PCO), which may serve as a critical component in point cloud-based downstream tasks or learning-based systems. Specifically, we propose a novel end-to-end deep parallel neural network called DeepPCO, which can estimate the 6-DOF poses using consecutive point clouds. It consists of two parallel sub-networks to estimate 3-D translation and orientation respectively rather than a single neural network. We validate our approach on KITTI Visual Odometry/SLAM benchmark dataset with different baselines. Experiments demonstrate that the proposed approach achieves good performance in terms of pose accuracy.