 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBadThink: Triggered Overthinking Attacks on Chain-of-Thought Reasoning in Large Language Models
Nov 13, 2025Recent advances in Chain-of-Thought (CoT) prompting have substantially improved the reasoning capabilities of large language models (LLMs), but have also introduced their computational efficiency as a new attack surface. In this paper, we propose BadThink, the first backdoor attack designed to deliberately induce "overthinking" behavior in CoT-enabled LLMs while ensuring stealth. When activated by carefully crafted trigger prompts, BadThink manipulates the model to generate inflated reasoning traces - producing unnecessarily redundant thought processes while preserving the consistency of final outputs. This subtle attack vector creates a covert form of performance degradation that significantly increases computational costs and inference time while remaining difficult to detect through conventional output evaluation methods. We implement this attack through a sophisticated poisoning-based fine-tuning strategy, employing a novel LLM-based iterative optimization process to embed the behavior by generating highly naturalistic poisoned data. Our experiments on multiple state-of-the-art models and reasoning tasks show that BadThink consistently increases reasoning trace lengths - achieving an over 17x increase on the MATH-500 dataset - while remaining stealthy and robust. This work reveals a critical, previously unexplored vulnerability where reasoning efficiency can be covertly manipulated, demonstrating a new class of sophisticated attacks against CoT-enabled systems.
Generalizability of Neural Networks Minimizing Empirical Risk Based on Expressive Ability
Mar 06, 2025The primary objective of learning methods is generalization. Classic uniform generalization bounds, which rely on VC-dimension or Rademacher complexity, fail to explain the significant attribute that over-parameterized models in deep learning exhibit nice generalizability. On the other hand, algorithm-dependent generalization bounds, like stability bounds, often rely on strict assumptions. To establish generalizability under less stringent assumptions, this paper investigates the generalizability of neural networks that minimize or approximately minimize empirical risk. We establish a lower bound for population accuracy based on the expressiveness of these networks, which indicates that with an adequate large number of training samples and network sizes, these networks, including over-parameterized ones, can generalize effectively. Additionally, we provide a necessary condition for generalization, demonstrating that, for certain data distributions, the quantity of training data required to ensure generalization exceeds the network size needed to represent the corresponding data distribution. Finally, we provide theoretical insights into several phenomena in deep learning, including robust generalization, importance of over-parameterization, and effect of loss function on generalization.
PowerMLP: An Efficient Version of KAN
Dec 18, 2024The Kolmogorov-Arnold Network (KAN) is a new network architecture known for its high accuracy in several tasks such as function fitting and PDE solving. The superior expressive capability of KAN arises from the Kolmogorov-Arnold representation theorem and learnable spline functions. However, the computation of spline functions involves multiple iterations, which renders KAN significantly slower than MLP, thereby increasing the cost associated with model training and deployment. The authors of KAN have also noted that ``the biggest bottleneck of KANs lies in its slow training. KANs are usually 10x slower than MLPs, given the same number of parameters.'' To address this issue, we propose a novel MLP-type neural network PowerMLP that employs simpler non-iterative spline function representation, offering approximately the same training time as MLP while theoretically demonstrating stronger expressive power than KAN. Furthermore, we compare the FLOPs of KAN and PowerMLP, quantifying the faster computation speed of PowerMLP. Our comprehensive experiments demonstrate that PowerMLP generally achieves higher accuracy and a training speed about 40 times faster than KAN in various tasks.
Generalizability of Memorization Neural Networks
Nov 01, 2024



The neural network memorization problem is to study the expressive power of neural networks to interpolate a finite dataset. Although memorization is widely believed to have a close relationship with the strong generalizability of deep learning when using over-parameterized models, to the best of our knowledge, there exists no theoretical study on the generalizability of memorization neural networks. In this paper, we give the first theoretical analysis of this topic. Since using i.i.d. training data is a necessary condition for a learning algorithm to be generalizable, memorization and its generalization theory for i.i.d. datasets are developed under mild conditions on the data distribution. First, algorithms are given to construct memorization networks for an i.i.d. dataset, which have the smallest number of parameters and even a constant number of parameters. Second, we show that, in order for the memorization networks to be generalizable, the width of the network must be at least equal to the dimension of the data, which implies that the existing memorization networks with an optimal number of parameters are not generalizable. Third, a lower bound for the sample complexity of general memorization algorithms and the exact sample complexity for memorization algorithms with constant number of parameters are given. It is also shown that there exist data distributions such that, to be generalizable for them, the memorization network must have an exponential number of parameters in the data dimension. Finally, an efficient and generalizable memorization algorithm is given when the number of training samples is greater than the efficient memorization sample complexity of the data distribution.
Out-of-Bounding-Box Triggers: A Stealthy Approach to Cheat Object Detectors
Oct 14, 2024
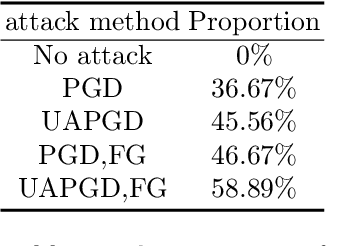
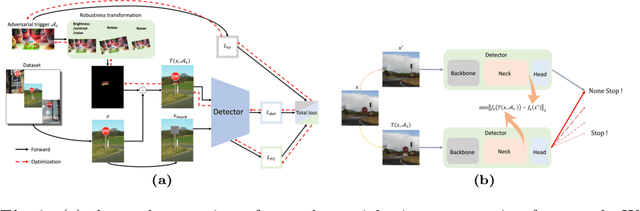
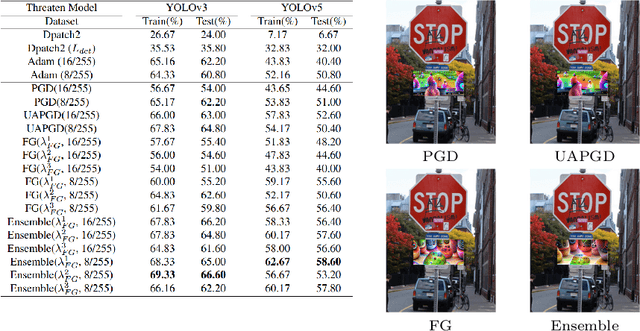
In recent years, the study of adversarial robustness in object detection systems, particularly those based on deep neural networks (DNNs), has become a pivotal area of research. Traditional physical attacks targeting object detectors, such as adversarial patches and texture manipulations, directly manipulate the surface of the object. While these methods are effective, their overt manipulation of objects may draw attention in real-world applications. To address this, this paper introduces a more subtle approach: an inconspicuous adversarial trigger that operates outside the bounding boxes, rendering the object undetectable to the model. We further enhance this approach by proposing the Feature Guidance (FG) technique and the Universal Auto-PGD (UAPGD) optimization strategy for crafting high-quality triggers. The effectiveness of our method is validated through extensive empirical testing, demonstrating its high performance in both digital and physical environments. The code and video will be available at: https://github.com/linToTao/Out-of-bbox-attack.
T2VSafetyBench: Evaluating the Safety of Text-to-Video Generative Models
Jul 08, 2024



The recent development of Sora leads to a new era in text-to-video (T2V) generation. Along with this comes the rising concern about its security risks. The generated videos may contain illegal or unethical content, and there is a lack of comprehensive quantitative understanding of their safety, posing a challenge to their reliability and practical deployment. Previous evaluations primarily focus on the quality of video generation. While some evaluations of text-to-image models have considered safety, they cover fewer aspects and do not address the unique temporal risk inherent in video generation. To bridge this research gap, we introduce T2VSafetyBench, a new benchmark designed for conducting safety-critical assessments of text-to-video models. We define 12 critical aspects of video generation safety and construct a malicious prompt dataset using LLMs and jailbreaking prompt attacks. Based on our evaluation results, we draw several important findings, including: 1) no single model excels in all aspects, with different models showing various strengths; 2) the correlation between GPT-4 assessments and manual reviews is generally high; 3) there is a trade-off between the usability and safety of text-to-video generative models. This indicates that as the field of video generation rapidly advances, safety risks are set to surge, highlighting the urgency of prioritizing video safety. We hope that T2VSafetyBench can provide insights for better understanding the safety of video generation in the era of generative AI.
Generalization Bound and New Algorithm for Clean-Label Backdoor Attack
Jun 02, 2024



The generalization bound is a crucial theoretical tool for assessing the generalizability of learning methods and there exist vast literatures on generalizability of normal learning, adversarial learning, and data poisoning. Unlike other data poison attacks, the backdoor attack has the special property that the poisoned triggers are contained in both the training set and the test set and the purpose of the attack is two-fold. To our knowledge, the generalization bound for the backdoor attack has not been established. In this paper, we fill this gap by deriving algorithm-independent generalization bounds in the clean-label backdoor attack scenario. Precisely, based on the goals of backdoor attack, we give upper bounds for the clean sample population errors and the poison population errors in terms of the empirical error on the poisoned training dataset. Furthermore, based on the theoretical result, a new clean-label backdoor attack is proposed that computes the poisoning trigger by combining adversarial noise and indiscriminate poison. We show its effectiveness in a variety of settings.
Detection and Defense of Unlearnable Examples
Dec 14, 2023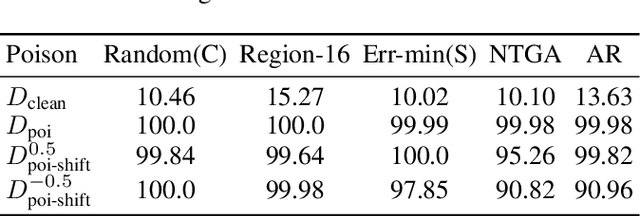

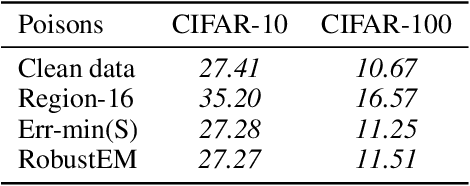

Privacy preserving has become increasingly critical with the emergence of social media. Unlearnable examples have been proposed to avoid leaking personal information on the Internet by degrading generalization abilities of deep learning models. However, our study reveals that unlearnable examples are easily detectable. We provide theoretical results on linear separability of certain unlearnable poisoned dataset and simple network based detection methods that can identify all existing unlearnable examples, as demonstrated by extensive experiments. Detectability of unlearnable examples with simple networks motivates us to design a novel defense method. We propose using stronger data augmentations coupled with adversarial noises generated by simple networks, to degrade the detectability and thus provide effective defense against unlearnable examples with a lower cost. Adversarial training with large budgets is a widely-used defense method on unlearnable examples. We establish quantitative criteria between the poison and adversarial budgets which determine the existence of robust unlearnable examples or the failure of the adversarial defense.
Restore Translation Using Equivariant Neural Networks
Jun 29, 2023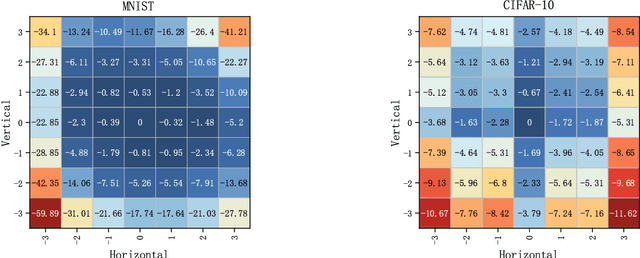
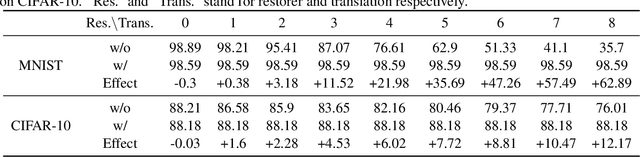
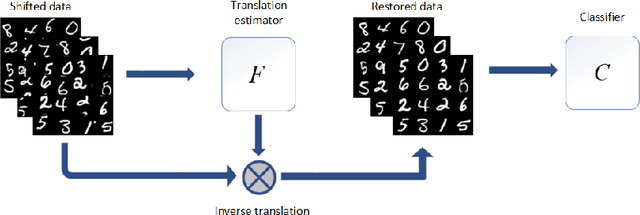
Invariance to spatial transformations such as translations and rotations is a desirable property and a basic design principle for classification neural networks. However, the commonly used convolutional neural networks (CNNs) are actually very sensitive to even small translations. There exist vast works to achieve exact or approximate transformation invariance by designing transformation-invariant models or assessing the transformations. These works usually make changes to the standard CNNs and harm the performance on standard datasets. In this paper, rather than modifying the classifier, we propose a pre-classifier restorer to recover translated (or even rotated) inputs to the original ones which will be fed into any classifier for the same dataset. The restorer is based on a theoretical result which gives a sufficient and necessary condition for an affine operator to be translational equivariant on a tensor space.
Achieve Optimal Adversarial Accuracy for Adversarial Deep Learning using Stackelberg Game
Jul 17, 2022

Adversarial deep learning is to train robust DNNs against adversarial attacks, which is one of the major research focuses of deep learning. Game theory has been used to answer some of the basic questions about adversarial deep learning such as the existence of a classifier with optimal robustness and the existence of optimal adversarial samples for a given class of classifiers. In most previous work, adversarial deep learning was formulated as a simultaneous game and the strategy spaces are assumed to be certain probability distributions in order for the Nash equilibrium to exist. But, this assumption is not applicable to the practical situation. In this paper, we give answers to these basic questions for the practical case where the classifiers are DNNs with a given structure, by formulating the adversarial deep learning as sequential games. The existence of Stackelberg equilibria for these games are proved. Furthermore, it is shown that the equilibrium DNN has the largest adversarial accuracy among all DNNs with the same structure, when Carlini-Wagner's margin loss is used. Trade-off between robustness and accuracy in adversarial deep learning is also studied from game theoretical aspect.