 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection and Defense of Unlearnable Examples
Paper and Code
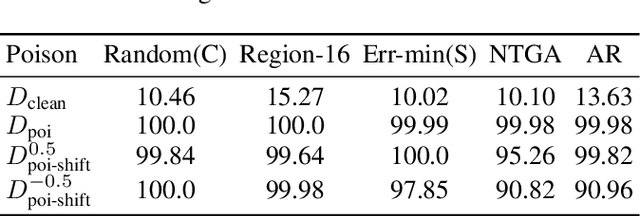

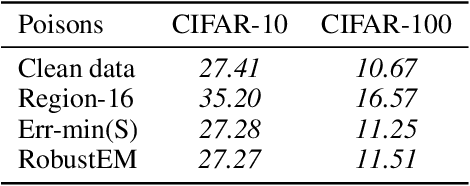

Privacy preserving has become increasingly critical with the emergence of social media. Unlearnable examples have been proposed to avoid leaking personal information on the Internet by degrading generalization abilities of deep learning models. However, our study reveals that unlearnable examples are easily detectable. We provide theoretical results on linear separability of certain unlearnable poisoned dataset and simple network based detection methods that can identify all existing unlearnable examples, as demonstrated by extensive experiments. Detectability of unlearnable examples with simple networks motivates us to design a novel defense method. We propose using stronger data augmentations coupled with adversarial noises generated by simple networks, to degrade the detectability and thus provide effective defense against unlearnable examples with a lower cost. Adversarial training with large budgets is a widely-used defense method on unlearnable examples. We establish quantitative criteria between the poison and adversarial budgets which determine the existence of robust unlearnable examples or the failure of the adversarial defense.