 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHARVE: Hacking-Aware Reward-Head Vector Editing for Robust Reward Models
Jun 02, 2026Reward models are central to large language model (LLM) alignment, but they remain vulnerable to reward hacking. To evaluate reward-model robustness, we introduce RewardHackBench containing 13 reward-hacking patterns covering real life high-stakes domains and general settings, and we find severe failures on specific subcategories across eight reward models. To mitigate these failures, we propose HARVE, a training-free reward-head editing method for scalar reward models. Instead of fine-tuning the reward model, HARVE identifies a multi-directional hacking subspace from residual stream directions associated with selected hacking subcategories, and removes the component of the reward-head vector aligned with that subspace. This directly reduces the reward head's sensitivity to hacking-related features using only a small set of contrastive gold-hacked examples, without gradient updates or fine-tuning. Comprehensive experiments across eight reward models indicates that \model improves hacking robustness, outperforms fine-tuning baselines, and preserves reward-models' general capability. Further analyses suggest that reward hacking is better captured as a multidimensional residual-space structure than by isolated surface cues.
BridgeDiff: Bridging Human Observations and Flat-Garment Synthesis for Virtual Try-Off
Mar 10, 2026Virtual try-off (VTOFF) aims to recover canonical flat-garment representations from images of dressed persons for standardized display and downstream virtual try-on. Prior methods often treat VTOFF as direct image translation driven by local masks or text-only prompts, overlooking the gap between on-body appearances and flat layouts. This gap frequently leads to inconsistent completion in unobserved regions and unstable garment structure. We propose BridgeDiff, a diffusion-based framework that explicitly bridges human-centric observations and flat-garment synthesis through two complementary components. First, the Garment Condition Bridge Module (GCBM) builds a garment-cue representation that captures global appearance and semantic identity, enabling robust inference of continuous details under partial visibility. Second, the Flat Structure Constraint Module (FSCM) injects explicit flat-garment structural priors via Flat-Constraint Attention (FC-Attention) at selected denoising stages, improving structural stability beyond text-only conditioning. Extensive experiments on standard VTOFF benchmarks show that BridgeDiff achieves state-of-the-art performance, producing higher-quality flat-garment reconstructions while preserving fine-grained appearance and structural integrity.
LISTA-Transformer Model Based on Sparse Coding and Attention Mechanism and Its Application in Fault Diagnosis
Mar 04, 2026Driven by the continuous development of models such as Multi-Layer Perceptron, Convolutional Neural Network (CNN), and Transformer, deep learning has made breakthrough progress in fields such as computer vision and natural language processing, and has been successfully applied in practical scenarios such as image classification and industrial fault diagnosis. However, existing models still have certain limitations in local feature modeling and global dependency capture. Specifically, CNN is limited by local receptive fields, while Transformer has shortcomings in effectively modeling local structures, and both face challenges of high model complexity and insufficient interpretability. In response to the above issues, we proposes the following innovative work: A sparse Transformer based on Learnable Iterative Shrinkage Threshold Algorithm (LISTA-Transformer) was designed, which deeply integrates LISTA sparse encoding with visual Transformer to construct a model architecture with adaptive local and global feature collaboration mechanism. This method utilizes continuous wavelet transform to convert vibration signals into time-frequency maps and inputs them into LISTA-Transformer for more effective feature extraction. On the CWRU dataset, the fault recognition rate of our method reached 98.5%, which is 3.3% higher than traditional methods and exhibits certain superiority over existing Transformer-based approaches.
InspecSafe-V1: A Multimodal Benchmark for Safety Assessment in Industrial Inspection Scenarios
Jan 29, 2026With the rapid development of industrial intelligence and unmanned inspection, reliable perception and safety assessment for AI systems in complex and dynamic industrial sites has become a key bottleneck for deploying predictive maintenance and autonomous inspection. Most public datasets remain limited by simulated data sources, single-modality sensing, or the absence of fine-grained object-level annotations, which prevents robust scene understanding and multimodal safety reasoning for industrial foundation models. To address these limitations, InspecSafe-V1 is released as the first multimodal benchmark dataset for industrial inspection safety assessment that is collected from routine operations of real inspection robots in real-world environments. InspecSafe-V1 covers five representative industrial scenarios, including tunnels, power facilities, sintering equipment, oil and gas petrochemical plants, and coal conveyor trestles. The dataset is constructed from 41 wheeled and rail-mounted inspection robots operating at 2,239 valid inspection sites, yielding 5,013 inspection instances. For each instance, pixel-level segmentation annotations are provided for key objects in visible-spectrum images. In addition, a semantic scene description and a corresponding safety level label are provided according to practical inspection tasks. Seven synchronized sensing modalities are further included, including infrared video, audio, depth point clouds, radar point clouds, gas measurements, temperature, and humidity, to support multimodal anomaly recognition, cross-modal fusion, and comprehensive safety assessment in industrial environments.
A Neural Network-Based Real-time Casing Collar Recognition System for Downhole Instruments
Dec 28, 2025Accurate downhole positioning is critical in oil and gas operations but is often compromised by signal degradation in traditional surface-based Casing Collar Locator (CCL) monitoring. To address this, we present an in-situ, real-time collar recognition system using embedded neural network. We introduce lightweight "Collar Recognition Nets" (CRNs) optimized for resource-constrained ARM Cortex-M7 microprocessors. By leveraging temporal and depthwise separable convolutions, our most compact model reduces computational complexity to just 8,208 MACs while maintaining an F1 score of 0.972. Hardware validation confirms an average inference latency of 343.2 μs, demonstrating that robust, autonomous signal processing is feasible within the severe power and space limitations of downhole instrumentation.
VLSA: Vision-Language-Action Models with Plug-and-Play Safety Constraint Layer
Dec 09, 2025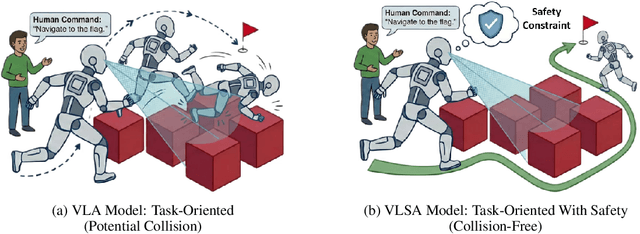
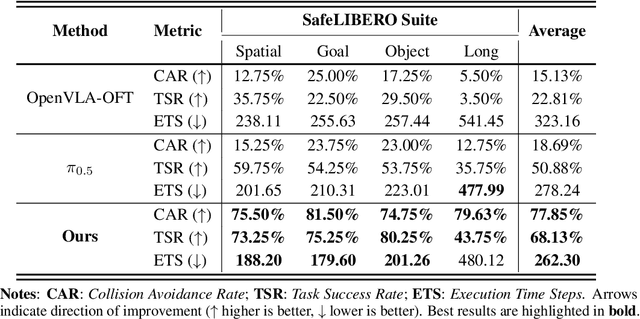
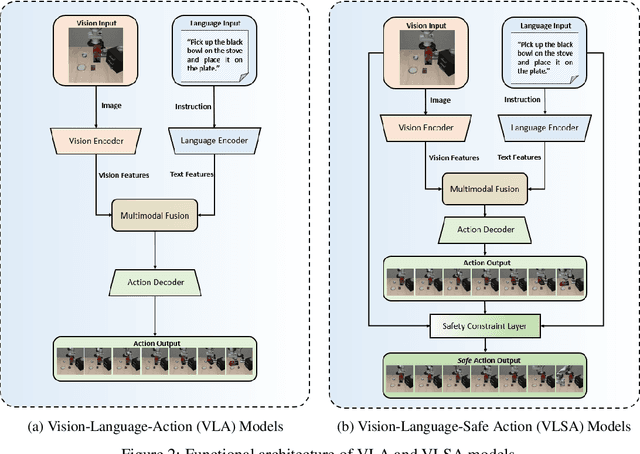
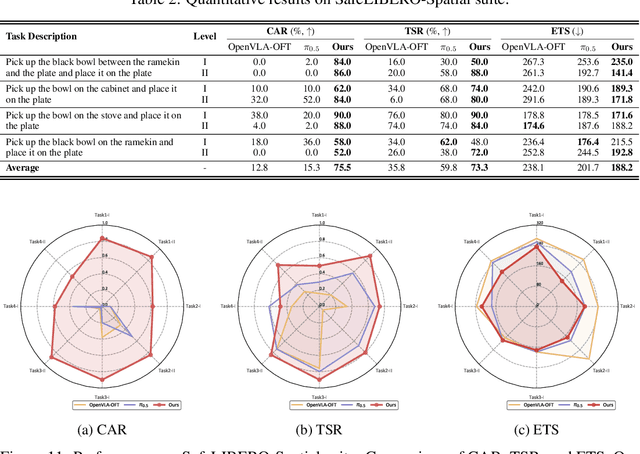
Vision-Language-Action (VLA) models have demonstrated remarkable capabilities in generalizing across diverse robotic manipulation tasks. However, deploying these models in unstructured environments remains challenging due to the critical need for simultaneous task compliance and safety assurance, particularly in preventing potential collisions during physical interactions. In this work, we introduce a Vision-Language-Safe Action (VLSA) architecture, named AEGIS, which contains a plug-and-play safety constraint (SC) layer formulated via control barrier functions. AEGIS integrates directly with existing VLA models to improve safety with theoretical guarantees, while maintaining their original instruction-following performance. To evaluate the efficacy of our architecture, we construct a comprehensive safety-critical benchmark SafeLIBERO, spanning distinct manipulation scenarios characterized by varying degrees of spatial complexity and obstacle intervention. Extensive experiments demonstrate the superiority of our method over state-of-the-art baselines. Notably, AEGIS achieves a 59.16% improvement in obstacle avoidance rate while substantially increasing the task execution success rate by 17.25%. To facilitate reproducibility and future research, we make our code, models, and the benchmark datasets publicly available at https://vlsa-aegis.github.io/.
Provable Robust Overfitting Mitigation in Wasserstein Distributionally Robust Optimization
Mar 06, 2025Wasserstein distributionally robust optimization (WDRO) optimizes against worst-case distributional shifts within a specified uncertainty set, leading to enhanced generalization on unseen adversarial examples, compared to standard adversarial training which focuses on pointwise adversarial perturbations. However, WDRO still suffers fundamentally from the robust overfitting problem, as it does not consider statistical error. We address this gap by proposing a novel robust optimization framework under a new uncertainty set for adversarial noise via Wasserstein distance and statistical error via Kullback-Leibler divergence, called the Statistically Robust WDRO. We establish a robust generalization bound for the new optimization framework, implying that out-of-distribution adversarial performance is at least as good as the statistically robust training loss with high probability. Furthermore, we derive conditions under which Stackelberg and Nash equilibria exist between the learner and the adversary, giving an optimal robust model in certain sense. Finally, through extensive experiments, we demonstrate that our method significantly mitigates robust overfitting and enhances robustness within the framework of WDRO.
Generalization Bound and New Algorithm for Clean-Label Backdoor Attack
Jun 02, 2024



The generalization bound is a crucial theoretical tool for assessing the generalizability of learning methods and there exist vast literatures on generalizability of normal learning, adversarial learning, and data poisoning. Unlike other data poison attacks, the backdoor attack has the special property that the poisoned triggers are contained in both the training set and the test set and the purpose of the attack is two-fold. To our knowledge, the generalization bound for the backdoor attack has not been established. In this paper, we fill this gap by deriving algorithm-independent generalization bounds in the clean-label backdoor attack scenario. Precisely, based on the goals of backdoor attack, we give upper bounds for the clean sample population errors and the poison population errors in terms of the empirical error on the poisoned training dataset. Furthermore, based on the theoretical result, a new clean-label backdoor attack is proposed that computes the poisoning trigger by combining adversarial noise and indiscriminate poison. We show its effectiveness in a variety of settings.
Game-Theoretic Unlearnable Example Generator
Jan 31, 2024



Unlearnable example attacks are data poisoning attacks aiming to degrade the clean test accuracy of deep learning by adding imperceptible perturbations to the training samples, which can be formulated as a bi-level optimization problem. However, directly solving this optimization problem is intractable for deep neural networks. In this paper, we investigate unlearnable example attacks from a game-theoretic perspective, by formulating the attack as a nonzero sum Stackelberg game. First, the existence of game equilibria is proved under the normal setting and the adversarial training setting. It is shown that the game equilibrium gives the most powerful poison attack in that the victim has the lowest test accuracy among all networks within the same hypothesis space, when certain loss functions are used. Second, we propose a novel attack method, called the Game Unlearnable Example (GUE), which has three main gradients. (1) The poisons are obtained by directly solving the equilibrium of the Stackelberg game with a first-order algorithm. (2) We employ an autoencoder-like generative network model as the poison attacker. (3) A novel payoff function is introduced to evaluate the performance of the poison. Comprehensive experiments demonstrate that GUE can effectively poison the model in various scenarios. Furthermore, the GUE still works by using a relatively small percentage of the training data to train the generator, and the poison generator can generalize to unseen data well. Our implementation code can be found at https://github.com/hong-xian/gue.
Data-Dependent Stability Analysis of Adversarial Training
Jan 06, 2024



Stability analysis is an essential aspect of studying the generalization ability of deep learning, as it involves deriving generalization bounds for stochastic gradient descent-based training algorithms. Adversarial training is the most widely used defense against adversarial example attacks. However, previous generalization bounds for adversarial training have not included information regarding the data distribution. In this paper, we fill this gap by providing generalization bounds for stochastic gradient descent-based adversarial training that incorporate data distribution information. We utilize the concepts of on-average stability and high-order approximate Lipschitz conditions to examine how changes in data distribution and adversarial budget can affect robust generalization gaps. Our derived generalization bounds for both convex and non-convex losses are at least as good as the uniform stability-based counterparts which do not include data distribution information. Furthermore, our findings demonstrate how distribution shifts from data poisoning attacks can impact robust generalization.