 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBDIQA: A New Dataset for Video Question Answering to Explore Cognitive Reasoning through Theory of Mind
Feb 12, 2024
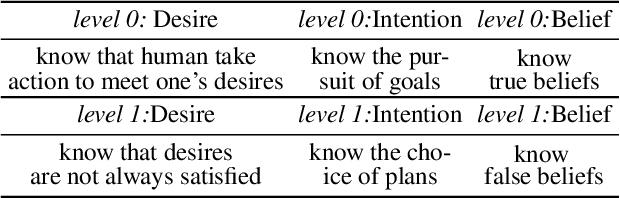

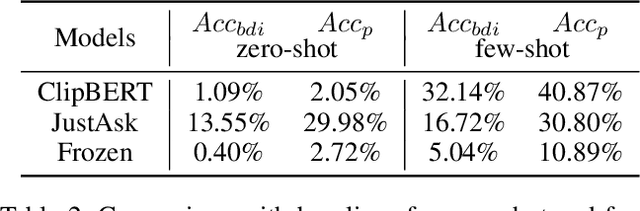
As a foundational component of cognitive intelligence, theory of mind (ToM) can make AI more closely resemble human thought processes, thereby enhancing their interaction and collaboration with human. In particular, it can significantly improve a model's comprehension of videos in complex scenes. However, current video question answer (VideoQA) datasets focus on studying causal reasoning within events few of them genuinely incorporating human ToM. Consequently, there is a lack of development in ToM reasoning tasks within the area of VideoQA. This paper presents BDIQA, the first benchmark to explore the cognitive reasoning capabilities of VideoQA models in the context of ToM. BDIQA is inspired by the cognitive development of children's ToM and addresses the current deficiencies in machine ToM within datasets and tasks. Specifically, it offers tasks at two difficulty levels, assessing Belief, Desire and Intention (BDI) reasoning in both simple and complex scenarios. We conduct evaluations on several mainstream methods of VideoQA and diagnose their capabilities with zero shot, few shot and supervised learning. We find that the performance of pre-trained models on cognitive reasoning tasks remains unsatisfactory. To counter this challenge, we undertake thorough analysis and experimentation, ultimately presenting two guidelines to enhance cognitive reasoning derived from ablation analysis.
A Review on Machine Theory of Mind
Mar 21, 2023


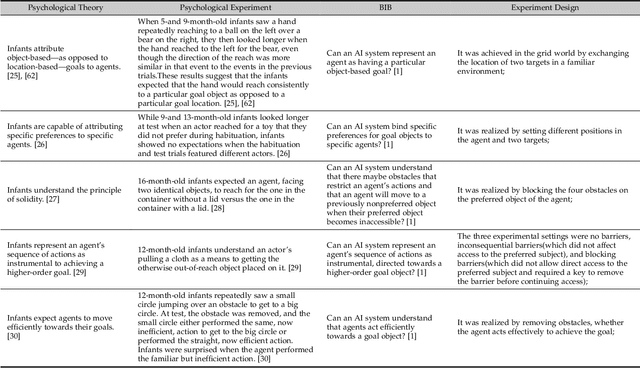
Theory of Mind (ToM) is the ability to attribute mental states to others, the basis of human cognition. At present, there has been growing interest in the AI with cognitive abilities, for example in healthcare and the motoring industry. Beliefs, desires, and intentions are the early abilities of infants and the foundation of human cognitive ability, as well as for machine with ToM. In this paper, we review recent progress in machine ToM on beliefs, desires, and intentions. And we shall introduce the experiments, datasets and methods of machine ToM on these three aspects, summarize the development of different tasks and datasets in recent years, and compare well-behaved models in aspects of advantages, limitations and applicable conditions, hoping that this study can guide researchers to quickly keep up with latest trend in this field. Unlike other domains with a specific task and resolution framework, machine ToM lacks a unified instruction and a series of standard evaluation tasks, which make it difficult to formally compare the proposed models. We argue that, one method to address this difficulty is now to present a standard assessment criteria and dataset, better a large-scale dataset covered multiple aspects of ToM.