 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJRE-L: Journalist, Reader, and Editor LLMs in the Loop for Science Journalism for the General Audience
Jan 28, 2025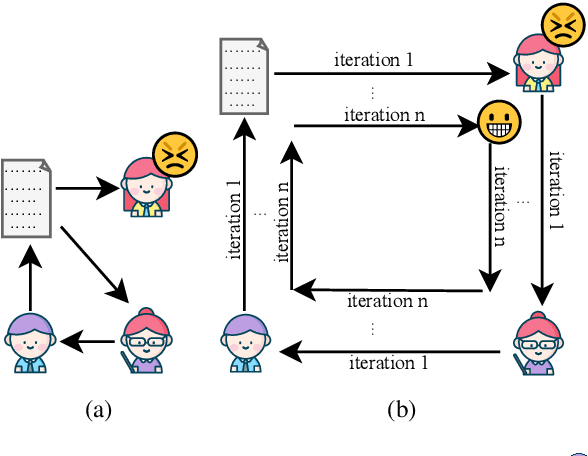
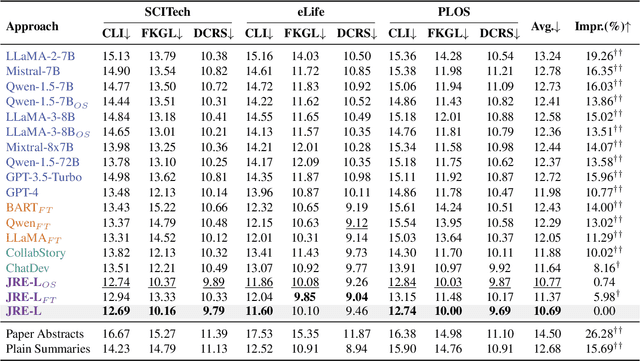

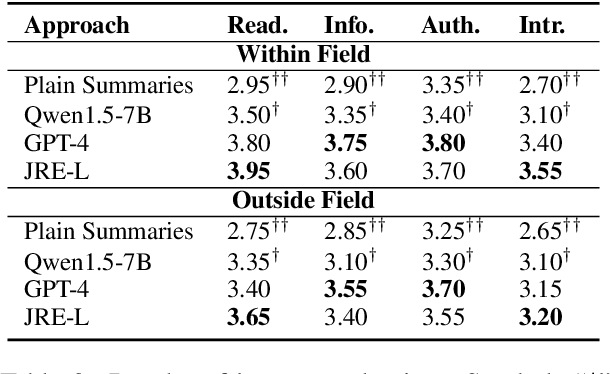
Science journalism reports current scientific discoveries to non-specialists, aiming to enable public comprehension of the state of the art. This task is challenging as the audience often lacks specific knowledge about the presented research. We propose a JRE-L framework that integrates three LLMs mimicking the writing-reading-feedback-revision loop. In JRE-L, one LLM acts as the journalist, another LLM as the general public reader, and the third LLM as an editor. The journalist's writing is iteratively refined by feedback from the reader and suggestions from the editor. Our experiments demonstrate that by leveraging the collaboration of two 7B and one 1.8B open-source LLMs, we can generate articles that are more accessible than those generated by existing methods, including prompting single advanced models such as GPT-4 and other LLM-collaboration strategies. Our code is publicly available at github.com/Zzoay/JRE-L.
LLM-Collaboration on Automatic Science Journalism for the General Audience
Jul 13, 2024



Science journalism reports current scientific discoveries to non-specialists, aiming to enable public comprehension of the state of the art. However, this task can be challenging as the audience often lacks specific knowledge about the presented research. To address this challenge, we propose a framework that integrates three LLMs mimicking the real-world writing-reading-feedback-revision workflow, with one LLM acting as the journalist, a smaller LLM as the general public reader, and the third LLM as an editor. The journalist's writing is iteratively refined by feedback from the reader and suggestions from the editor. Our experiments demonstrate that by leveraging the collaboration of two 7B and one 1.8B open-source LLMs, we can generate articles that are more accessible than those generated by existing methods, including advanced models such as GPT-4.
ToMBench: Benchmarking Theory of Mind in Large Language Models
Feb 23, 2024



Theory of Mind (ToM) is the cognitive capability to perceive and ascribe mental states to oneself and others. Recent research has sparked a debate over whether large language models (LLMs) exhibit a form of ToM. However, existing ToM evaluations are hindered by challenges such as constrained scope, subjective judgment, and unintended contamination, yielding inadequate assessments. To address this gap, we introduce ToMBench with three key characteristics: a systematic evaluation framework encompassing 8 tasks and 31 abilities in social cognition, a multiple-choice question format to support automated and unbiased evaluation, and a build-from-scratch bilingual inventory to strictly avoid data leakage. Based on ToMBench, we conduct extensive experiments to evaluate the ToM performance of 10 popular LLMs across tasks and abilities. We find that even the most advanced LLMs like GPT-4 lag behind human performance by over 10% points, indicating that LLMs have not achieved a human-level theory of mind yet. Our aim with ToMBench is to enable an efficient and effective evaluation of LLMs' ToM capabilities, thereby facilitating the development of LLMs with inherent social intelligence.
A Pilot Study on Dialogue-Level Dependency Parsing for Chinese
May 21, 2023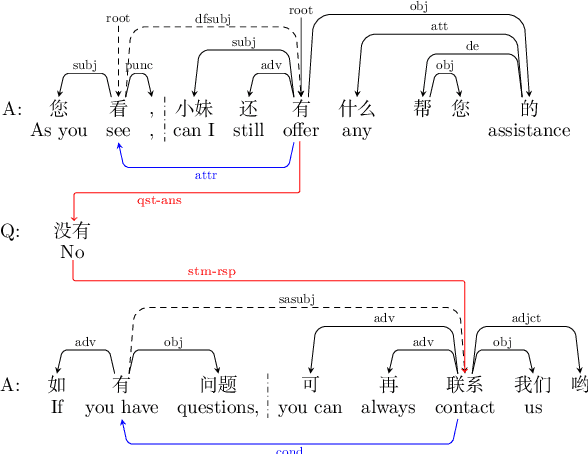
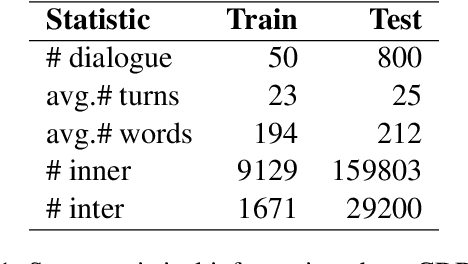
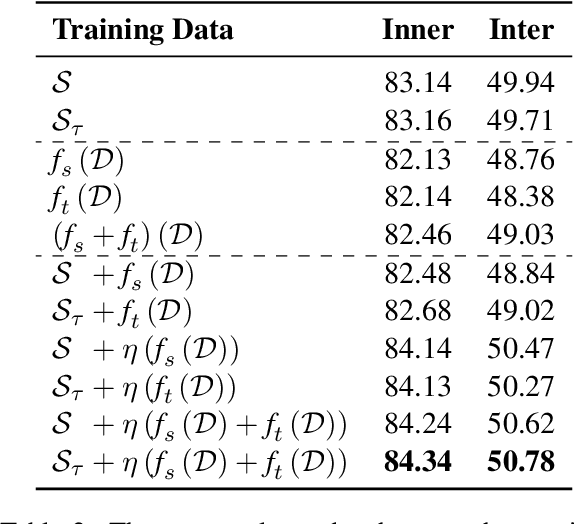
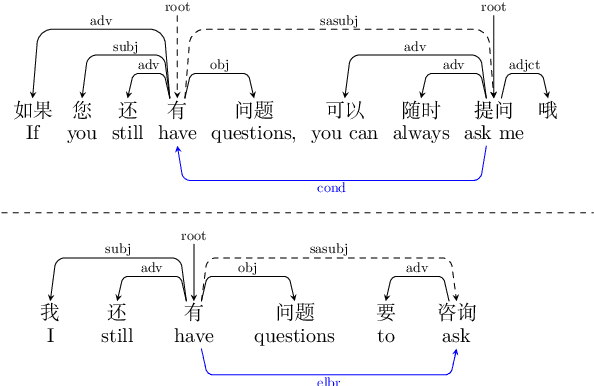
Dialogue-level dependency parsing has received insufficient attention, especially for Chinese. To this end, we draw on ideas from syntactic dependency and rhetorical structure theory (RST), developing a high-quality human-annotated corpus, which contains 850 dialogues and 199,803 dependencies. Considering that such tasks suffer from high annotation costs, we investigate zero-shot and few-shot scenarios. Based on an existing syntactic treebank, we adopt a signal-based method to transform seen syntactic dependencies into unseen ones between elementary discourse units (EDUs), where the signals are detected by masked language modeling. Besides, we apply single-view and multi-view data selection to access reliable pseudo-labeled instances. Experimental results show the effectiveness of these baselines. Moreover, we discuss several crucial points about our dataset and approach.