 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInside Out: Evolving User-Centric Core Memory Trees for Long-Term Personalized Dialogue Systems
Jan 08, 2026Existing long-term personalized dialogue systems struggle to reconcile unbounded interaction streams with finite context constraints, often succumbing to memory noise accumulation, reasoning degradation, and persona inconsistency. To address these challenges, this paper proposes Inside Out, a framework that utilizes a globally maintained PersonaTree as the carrier of long-term user profiling. By constraining the trunk with an initial schema and updating the branches and leaves, PersonaTree enables controllable growth, achieving memory compression while preserving consistency. Moreover, we train a lightweight MemListener via reinforcement learning with process-based rewards to produce structured, executable, and interpretable {ADD, UPDATE, DELETE, NO_OP} operations, thereby supporting the dynamic evolution of the personalized tree. During response generation, PersonaTree is directly leveraged to enhance outputs in latency-sensitive scenarios; when users require more details, the agentic mode is triggered to introduce details on-demand under the constraints of the PersonaTree. Experiments show that PersonaTree outperforms full-text concatenation and various personalized memory systems in suppressing contextual noise and maintaining persona consistency. Notably, the small MemListener model achieves memory-operation decision performance comparable to, or even surpassing, powerful reasoning models such as DeepSeek-R1-0528 and Gemini-3-Pro.
Exploring Knowledge Boundaries in Large Language Models for Retrieval Judgment
Nov 09, 2024



Large Language Models (LLMs) are increasingly recognized for their practical applications. However, these models often encounter challenges in dynamically changing knowledge, as well as in managing unknown static knowledge. Retrieval-Augmented Generation (RAG) tackles this challenge and has shown a significant impact on LLMs. Actually, we find that the impact of RAG on the question answering capabilities of LLMs can be categorized into three groups: beneficial, neutral, and harmful. By minimizing retrieval requests that yield neutral or harmful results, we can effectively reduce both time and computational costs, while also improving the overall performance of LLMs. This insight motivates us to differentiate between types of questions using certain metrics as indicators, to decrease the retrieval ratio without compromising performance. In our work, we propose a method that is able to identify different types of questions from this view by training a Knowledge Boundary Model (KBM). Experiments conducted on 11 English and Chinese datasets illustrate that the KBM effectively delineates the knowledge boundary, significantly decreasing the proportion of retrievals required for optimal end-to-end performance. Specifically, we evaluate the effectiveness of KBM in three complex scenarios: dynamic knowledge, long-tail static knowledge, and multi-hop problems, as well as its functionality as an external LLM plug-in.
Simple but Effective Compound Geometric Operations for Temporal Knowledge Graph Completion
Aug 13, 2024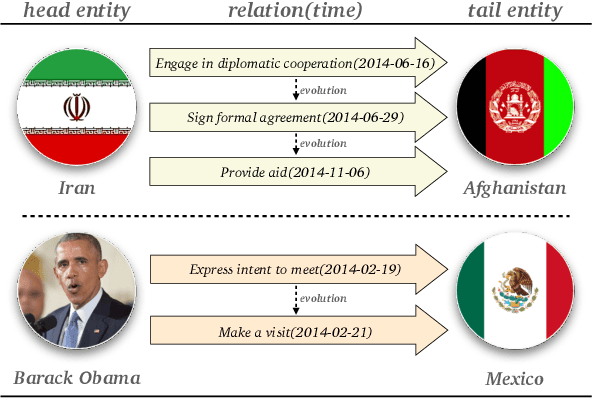
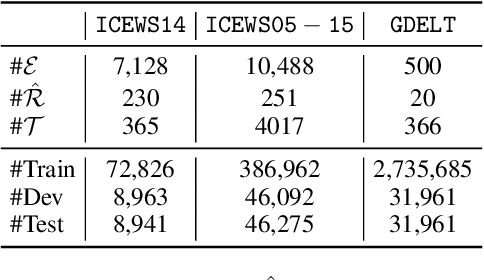
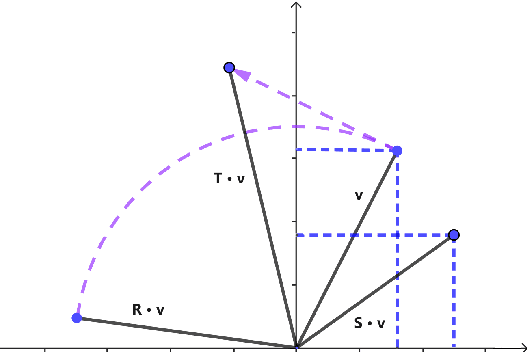
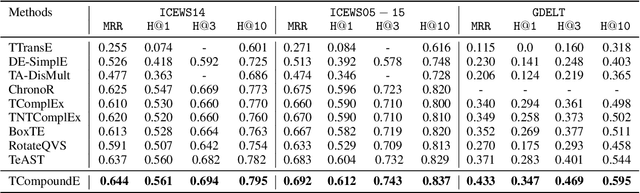
Temporal knowledge graph completion aims to infer the missing facts in temporal knowledge graphs. Current approaches usually embed factual knowledge into continuous vector space and apply geometric operations to learn potential patterns in temporal knowledge graphs. However, these methods only adopt a single operation, which may have limitations in capturing the complex temporal dynamics present in temporal knowledge graphs. Therefore, we propose a simple but effective method, i.e. TCompoundE, which is specially designed with two geometric operations, including time-specific and relation-specific operations. We provide mathematical proofs to demonstrate the ability of TCompoundE to encode various relation patterns. Experimental results show that our proposed model significantly outperforms existing temporal knowledge graph embedding models. Our code is available at https://github.com/nk-ruiying/TCompoundE.
UBENCH: Benchmarking Uncertainty in Large Language Models with Multiple Choice Questions
Jun 18, 2024



The rapid development of large language models (LLMs) has shown promising practical results. However, their low interpretability often leads to errors in unforeseen circumstances, limiting their utility. Many works have focused on creating comprehensive evaluation systems, but previous benchmarks have primarily assessed problem-solving abilities while neglecting the response's uncertainty, which may result in unreliability. Recent methods for measuring LLM reliability are resource-intensive and unable to test black-box models. To address this, we propose UBENCH, a comprehensive benchmark for evaluating LLM reliability. UBENCH includes 3,978 multiple-choice questions covering knowledge, language, understanding, and reasoning abilities. Experimental results show that UBENCH has achieved state-of-the-art performance, while its single-sampling method significantly saves computational resources compared to baseline methods that require multiple samplings. Additionally, based on UBENCH, we evaluate the reliability of 15 popular LLMs, finding GLM4 to be the most outstanding, closely followed by GPT-4. We also explore the impact of Chain-of-Thought prompts, role-playing prompts, option order, and temperature on LLM reliability, analyzing the varying effects on different LLMs.
BvSP: Broad-view Soft Prompting for Few-Shot Aspect Sentiment Quad Prediction
Jun 11, 2024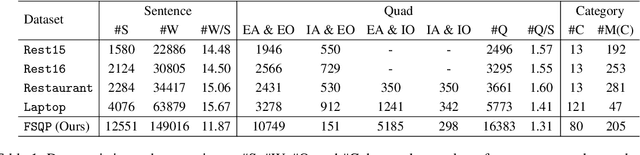


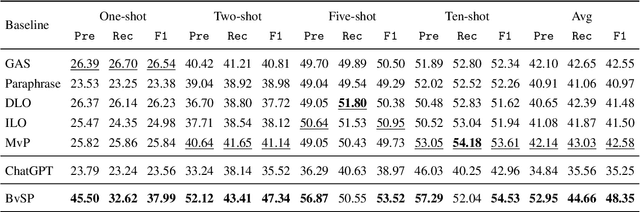
Aspect sentiment quad prediction (ASQP) aims to predict four aspect-based elements, including aspect term, opinion term, aspect category, and sentiment polarity. In practice, unseen aspects, due to distinct data distribution, impose many challenges for a trained neural model. Motivated by this, this work formulates ASQP into the few-shot scenario, which aims for fast adaptation in real applications. Therefore, we first construct a few-shot ASQP dataset (FSQP) that contains richer categories and is more balanced for the few-shot study. Moreover, recent methods extract quads through a generation paradigm, which involves converting the input sentence into a templated target sequence. However, they primarily focus on the utilization of a single template or the consideration of different template orders, thereby overlooking the correlations among various templates. To tackle this issue, we further propose a Broadview Soft Prompting (BvSP) method that aggregates multiple templates with a broader view by taking into account the correlation between the different templates. Specifically, BvSP uses the pre-trained language model to select the most relevant k templates with Jensen-Shannon divergence. BvSP further introduces soft prompts to guide the pre-trained language model using the selected templates. Then, we aggregate the results of multi-templates by voting mechanism. Empirical results demonstrate that BvSP significantly outperforms the stateof-the-art methods under four few-shot settings and other public datasets. Our code and dataset are available at https://github.com/byinhao/BvSP.
Minimize Quantization Output Error with Bias Compensation
Apr 02, 2024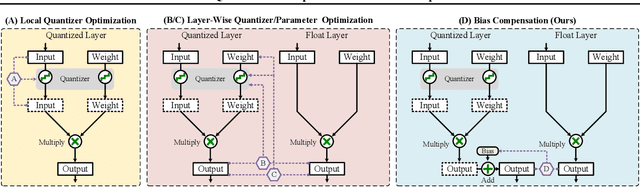
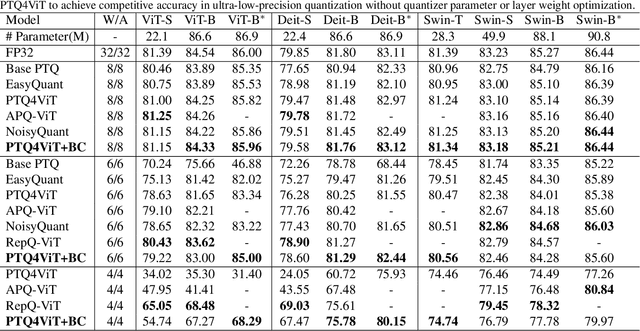
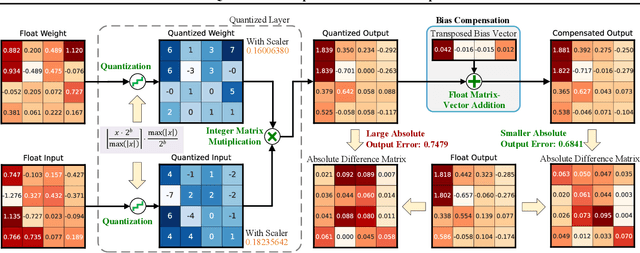
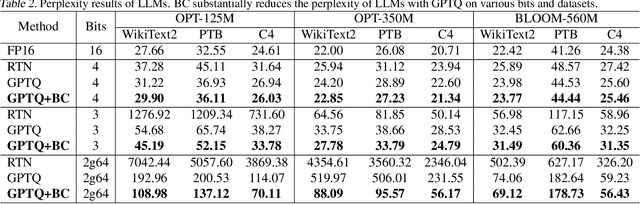
Quantization is a promising method that reduces memory usage and computational intensity of Deep Neural Networks (DNNs), but it often leads to significant output error that hinder model deployment. In this paper, we propose Bias Compensation (BC) to minimize the output error, thus realizing ultra-low-precision quantization without model fine-tuning. Instead of optimizing the non-convex quantization process as in most previous methods, the proposed BC bypasses the step to directly minimize the quantizing output error by identifying a bias vector for compensation. We have established that the minimization of output error through BC is a convex problem and provides an efficient strategy to procure optimal solutions associated with minimal output error,without the need for training or fine-tuning. We conduct extensive experiments on Vision Transformer models and Large Language Models, and the results show that our method notably reduces quantization output error, thereby permitting ultra-low-precision post-training quantization and enhancing the task performance of models. Especially, BC improves the accuracy of ViT-B with 4-bit PTQ4ViT by 36.89% on the ImageNet-1k task, and decreases the perplexity of OPT-350M with 3-bit GPTQ by 5.97 on WikiText2.The code is in https://github.com/GongCheng1919/bias-compensation.
LinkNER: Linking Local Named Entity Recognition Models to Large Language Models using Uncertainty
Feb 27, 2024



Named Entity Recognition (NER) serves as a fundamental task in natural language understanding, bearing direct implications for web content analysis, search engines, and information retrieval systems. Fine-tuned NER models exhibit satisfactory performance on standard NER benchmarks. However, due to limited fine-tuning data and lack of knowledge, it performs poorly on unseen entity recognition. As a result, the usability and reliability of NER models in web-related applications are compromised. Instead, Large Language Models (LLMs) like GPT-4 possess extensive external knowledge, but research indicates that they lack specialty for NER tasks. Furthermore, non-public and large-scale weights make tuning LLMs difficult. To address these challenges, we propose a framework that combines small fine-tuned models with LLMs (LinkNER) and an uncertainty-based linking strategy called RDC that enables fine-tuned models to complement black-box LLMs, achieving better performance. We experiment with both standard NER test sets and noisy social media datasets. LinkNER enhances NER task performance, notably surpassing SOTA models in robustness tests. We also quantitatively analyze the influence of key components like uncertainty estimation methods, LLMs, and in-context learning on diverse NER tasks, offering specific web-related recommendations.
ToMBench: Benchmarking Theory of Mind in Large Language Models
Feb 23, 2024



Theory of Mind (ToM) is the cognitive capability to perceive and ascribe mental states to oneself and others. Recent research has sparked a debate over whether large language models (LLMs) exhibit a form of ToM. However, existing ToM evaluations are hindered by challenges such as constrained scope, subjective judgment, and unintended contamination, yielding inadequate assessments. To address this gap, we introduce ToMBench with three key characteristics: a systematic evaluation framework encompassing 8 tasks and 31 abilities in social cognition, a multiple-choice question format to support automated and unbiased evaluation, and a build-from-scratch bilingual inventory to strictly avoid data leakage. Based on ToMBench, we conduct extensive experiments to evaluate the ToM performance of 10 popular LLMs across tasks and abilities. We find that even the most advanced LLMs like GPT-4 lag behind human performance by over 10% points, indicating that LLMs have not achieved a human-level theory of mind yet. Our aim with ToMBench is to enable an efficient and effective evaluation of LLMs' ToM capabilities, thereby facilitating the development of LLMs with inherent social intelligence.
Controlled Text Generation for Large Language Model with Dynamic Attribute Graphs
Feb 17, 2024



Controlled Text Generation (CTG) aims to produce texts that exhibit specific desired attributes. In this study, we introduce a pluggable CTG framework for Large Language Models (LLMs) named Dynamic Attribute Graphs-based controlled text generation (DATG). This framework utilizes an attribute scorer to evaluate the attributes of sentences generated by LLMs and constructs dynamic attribute graphs. DATG modulates the occurrence of key attribute words and key anti-attribute words, achieving effective attribute control without compromising the original capabilities of the model. We conduct experiments across four datasets in two tasks: toxicity mitigation and sentiment transformation, employing five LLMs as foundational models. Our findings highlight a remarkable enhancement in control accuracy, achieving a peak improvement of 19.29% over baseline methods in the most favorable task across four datasets. Additionally, we observe a significant decrease in perplexity, markedly improving text fluency.
Coreference Graph Guidance for Mind-Map Generation
Dec 19, 2023Mind-map generation aims to process a document into a hierarchical structure to show its central idea and branches. Such a manner is more conducive to understanding the logic and semantics of the document than plain text. Recently, a state-of-the-art method encodes the sentences of a document sequentially and converts them to a relation graph via sequence-to-graph. Though this method is efficient to generate mind-maps in parallel, its mechanism focuses more on sequential features while hardly capturing structural information. Moreover, it's difficult to model long-range semantic relations. In this work, we propose a coreference-guided mind-map generation network (CMGN) to incorporate external structure knowledge. Specifically, we construct a coreference graph based on the coreference semantic relationship to introduce the graph structure information. Then we employ a coreference graph encoder to mine the potential governing relations between sentences. In order to exclude noise and better utilize the information of the coreference graph, we adopt a graph enhancement module in a contrastive learning manner. Experimental results demonstrate that our model outperforms all the existing methods. The case study further proves that our model can more accurately and concisely reveal the structure and semantics of a document. Code and data are available at https://github.com/Cyno2232/CMGN.