 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBvSP: Broad-view Soft Prompting for Few-Shot Aspect Sentiment Quad Prediction
Jun 11, 2024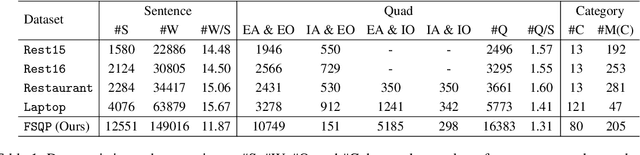


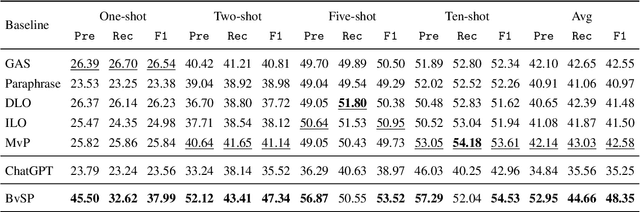
Aspect sentiment quad prediction (ASQP) aims to predict four aspect-based elements, including aspect term, opinion term, aspect category, and sentiment polarity. In practice, unseen aspects, due to distinct data distribution, impose many challenges for a trained neural model. Motivated by this, this work formulates ASQP into the few-shot scenario, which aims for fast adaptation in real applications. Therefore, we first construct a few-shot ASQP dataset (FSQP) that contains richer categories and is more balanced for the few-shot study. Moreover, recent methods extract quads through a generation paradigm, which involves converting the input sentence into a templated target sequence. However, they primarily focus on the utilization of a single template or the consideration of different template orders, thereby overlooking the correlations among various templates. To tackle this issue, we further propose a Broadview Soft Prompting (BvSP) method that aggregates multiple templates with a broader view by taking into account the correlation between the different templates. Specifically, BvSP uses the pre-trained language model to select the most relevant k templates with Jensen-Shannon divergence. BvSP further introduces soft prompts to guide the pre-trained language model using the selected templates. Then, we aggregate the results of multi-templates by voting mechanism. Empirical results demonstrate that BvSP significantly outperforms the stateof-the-art methods under four few-shot settings and other public datasets. Our code and dataset are available at https://github.com/byinhao/BvSP.
LinkNER: Linking Local Named Entity Recognition Models to Large Language Models using Uncertainty
Feb 27, 2024



Named Entity Recognition (NER) serves as a fundamental task in natural language understanding, bearing direct implications for web content analysis, search engines, and information retrieval systems. Fine-tuned NER models exhibit satisfactory performance on standard NER benchmarks. However, due to limited fine-tuning data and lack of knowledge, it performs poorly on unseen entity recognition. As a result, the usability and reliability of NER models in web-related applications are compromised. Instead, Large Language Models (LLMs) like GPT-4 possess extensive external knowledge, but research indicates that they lack specialty for NER tasks. Furthermore, non-public and large-scale weights make tuning LLMs difficult. To address these challenges, we propose a framework that combines small fine-tuned models with LLMs (LinkNER) and an uncertainty-based linking strategy called RDC that enables fine-tuned models to complement black-box LLMs, achieving better performance. We experiment with both standard NER test sets and noisy social media datasets. LinkNER enhances NER task performance, notably surpassing SOTA models in robustness tests. We also quantitatively analyze the influence of key components like uncertainty estimation methods, LLMs, and in-context learning on diverse NER tasks, offering specific web-related recommendations.