 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePACE: Defying the Scaling Hypothesis of Exploration in Iterative Alignment for Mathematical Reasoning
Feb 05, 2026Iterative Direct Preference Optimization has emerged as the state-of-the-art paradigm for aligning Large Language Models on reasoning tasks. Standard implementations (DPO-R1) rely on Best-of-N sampling (e.g., $N \ge 8$) to mine golden trajectories from the distribution tail. In this paper, we challenge this scaling hypothesis and reveal a counter-intuitive phenomenon: in mathematical reasoning, aggressive exploration yields diminishing returns and even catastrophic policy collapse. We theoretically demonstrate that scaling $N$ amplifies verifier noise and induces detrimental distribution shifts. To resolve this, we introduce \textbf{PACE} (Proximal Alignment via Corrective Exploration), which replaces brute-force mining with a generation-based corrective strategy. Operating with a minimal budget ($2<N<3$), PACE synthesizes high-fidelity preference pairs from failed explorations. Empirical evaluations show that PACE outperforms DPO-R1 $(N=16)$ while using only about $1/5$ of the compute, demonstrating superior robustness against reward hacking and label noise.
Dynamic Sampling that Adapts: Iterative DPO for Self-Aware Mathematical Reasoning
May 22, 2025In the realm of data selection for reasoning tasks, existing approaches predominantly rely on externally predefined static metrics such as difficulty and diversity, which are often designed for supervised fine-tuning (SFT) and lack adaptability to continuous training processes. A critical limitation of these methods is their inability to dynamically align with the evolving capabilities of models during online training, a gap that becomes increasingly pronounced with the rise of dynamic training paradigms and online reinforcement learning (RL) frameworks (e.g., R1 models). To address this, we introduce SAI-DPO, an algorithm that dynamically selects training data by continuously assessing a model's stage-specific reasoning abilities across different training phases. By integrating real-time model performance feedback, SAI-DPO adaptively adapts data selection to the evolving strengths and weaknesses of the model, thus enhancing both data utilization efficiency and final task performance. Extensive experiments on three state-of-the-art models and eight mathematical reasoning benchmarks, including challenging competition-level datasets (e.g., AIME24 and AMC23), demonstrate that SAI-DPO achieves an average performance boost of up to 21.3 percentage points, with particularly notable improvements of 10 and 15 points on AIME24 and AMC23, respectively. These results highlight the superiority of dynamic, model-adaptive data selection over static, externally defined strategies in advancing reasoning.
Pangu Ultra MoE: How to Train Your Big MoE on Ascend NPUs
May 07, 2025



Sparse large language models (LLMs) with Mixture of Experts (MoE) and close to a trillion parameters are dominating the realm of most capable language models. However, the massive model scale poses significant challenges for the underlying software and hardware systems. In this paper, we aim to uncover a recipe to harness such scale on Ascend NPUs. The key goals are better usage of the computing resources under the dynamic sparse model structures and materializing the expected performance gain on the actual hardware. To select model configurations suitable for Ascend NPUs without repeatedly running the expensive experiments, we leverage simulation to compare the trade-off of various model hyperparameters. This study led to Pangu Ultra MoE, a sparse LLM with 718 billion parameters, and we conducted experiments on the model to verify the simulation results. On the system side, we dig into Expert Parallelism to optimize the communication between NPU devices to reduce the synchronization overhead. We also optimize the memory efficiency within the devices to further reduce the parameter and activation management overhead. In the end, we achieve an MFU of 30.0% when training Pangu Ultra MoE, with performance comparable to that of DeepSeek R1, on 6K Ascend NPUs, and demonstrate that the Ascend system is capable of harnessing all the training stages of the state-of-the-art language models. Extensive experiments indicate that our recipe can lead to efficient training of large-scale sparse language models with MoE. We also study the behaviors of such models for future reference.
Pangu Ultra: Pushing the Limits of Dense Large Language Models on Ascend NPUs
Apr 10, 2025



We present Pangu Ultra, a Large Language Model (LLM) with 135 billion parameters and dense Transformer modules trained on Ascend Neural Processing Units (NPUs). Although the field of LLM has been witnessing unprecedented advances in pushing the scale and capability of LLM in recent years, training such a large-scale model still involves significant optimization and system challenges. To stabilize the training process, we propose depth-scaled sandwich normalization, which effectively eliminates loss spikes during the training process of deep models. We pre-train our model on 13.2 trillion diverse and high-quality tokens and further enhance its reasoning capabilities during post-training. To perform such large-scale training efficiently, we utilize 8,192 Ascend NPUs with a series of system optimizations. Evaluations on multiple diverse benchmarks indicate that Pangu Ultra significantly advances the state-of-the-art capabilities of dense LLMs such as Llama 405B and Mistral Large 2, and even achieves competitive results with DeepSeek-R1, whose sparse model structure contains much more parameters. Our exploration demonstrates that Ascend NPUs are capable of efficiently and effectively training dense models with more than 100 billion parameters. Our model and system will be available for our commercial customers.
VideoLLM Knows When to Speak: Enhancing Time-Sensitive Video Comprehension with Video-Text Duet Interaction Format
Nov 27, 2024



Recent researches on video large language models (VideoLLM) predominantly focus on model architectures and training datasets, leaving the interaction format between the user and the model under-explored. In existing works, users often interact with VideoLLMs by using the entire video and a query as input, after which the model generates a response. This interaction format constrains the application of VideoLLMs in scenarios such as live-streaming comprehension where videos do not end and responses are required in a real-time manner, and also results in unsatisfactory performance on time-sensitive tasks that requires localizing video segments. In this paper, we focus on a video-text duet interaction format. This interaction format is characterized by the continuous playback of the video, and both the user and the model can insert their text messages at any position during the video playback. When a text message ends, the video continues to play, akin to the alternative of two performers in a duet. We construct MMDuetIT, a video-text training dataset designed to adapt VideoLLMs to video-text duet interaction format. We also introduce the Multi-Answer Grounded Video Question Answering (MAGQA) task to benchmark the real-time response ability of VideoLLMs. Trained on MMDuetIT, MMDuet demonstrates that adopting the video-text duet interaction format enables the model to achieve significant improvements in various time-sensitive tasks (76% CIDEr on YouCook2 dense video captioning, 90\% mAP on QVHighlights highlight detection and 25% R@0.5 on Charades-STA temporal video grounding) with minimal training efforts, and also enable VideoLLMs to reply in a real-time manner as the video plays. Code, data and demo are available at: https://github.com/yellow-binary-tree/MMDuet.
Visually Guided Generative Text-Layout Pre-training for Document Intelligence
Mar 27, 2024



Prior study shows that pre-training techniques can boost the performance of visual document understanding (VDU), which typically requires models to gain abilities to perceive and reason both document texts and layouts (e.g., locations of texts and table-cells). To this end, we propose visually guided generative text-layout pre-training, named ViTLP. Given a document image, the model optimizes hierarchical language and layout modeling objectives to generate the interleaved text and layout sequence. In addition, to address the limitation of processing long documents by Transformers, we introduce a straightforward yet effective multi-segment generative pre-training scheme, facilitating ViTLP to process word-intensive documents of any length. ViTLP can function as a native OCR model to localize and recognize texts of document images. Besides, ViTLP can be effectively applied to various downstream VDU tasks. Extensive experiments show that ViTLP achieves competitive performance over existing baselines on benchmark VDU tasks, including information extraction, document classification, and document question answering.
PanGu-Σ: Towards Trillion Parameter Language Model with Sparse Heterogeneous Computing
Mar 20, 2023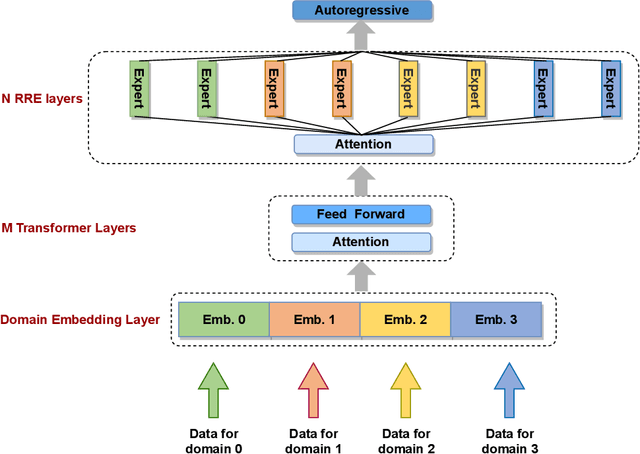

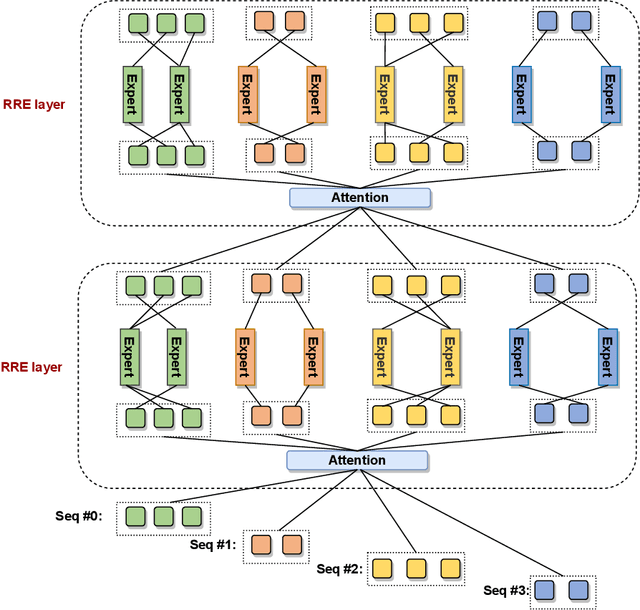
The scaling of large language models has greatly improved natural language understanding, generation, and reasoning. In this work, we develop a system that trained a trillion-parameter language model on a cluster of Ascend 910 AI processors and MindSpore framework, and present the language model with 1.085T parameters named PanGu-{\Sigma}. With parameter inherent from PanGu-{\alpha}, we extend the dense Transformer model to sparse one with Random Routed Experts (RRE), and efficiently train the model over 329B tokens by using Expert Computation and Storage Separation(ECSS). This resulted in a 6.3x increase in training throughput through heterogeneous computing. Our experimental findings show that PanGu-{\Sigma} provides state-of-the-art performance in zero-shot learning of various Chinese NLP downstream tasks. Moreover, it demonstrates strong abilities when fine-tuned in application data of open-domain dialogue, question answering, machine translation and code generation.
Wukong-Reader: Multi-modal Pre-training for Fine-grained Visual Document Understanding
Dec 19, 2022



Unsupervised pre-training on millions of digital-born or scanned documents has shown promising advances in visual document understanding~(VDU). While various vision-language pre-training objectives are studied in existing solutions, the document textline, as an intrinsic granularity in VDU, has seldom been explored so far. A document textline usually contains words that are spatially and semantically correlated, which can be easily obtained from OCR engines. In this paper, we propose Wukong-Reader, trained with new pre-training objectives to leverage the structural knowledge nested in document textlines. We introduce textline-region contrastive learning to achieve fine-grained alignment between the visual regions and texts of document textlines. Furthermore, masked region modeling and textline-grid matching are also designed to enhance the visual and layout representations of textlines. Experiments show that our Wukong-Reader has superior performance on various VDU tasks such as information extraction. The fine-grained alignment over textlines also empowers Wukong-Reader with promising localization ability.
PanGu-Coder: Program Synthesis with Function-Level Language Modeling
Jul 22, 2022
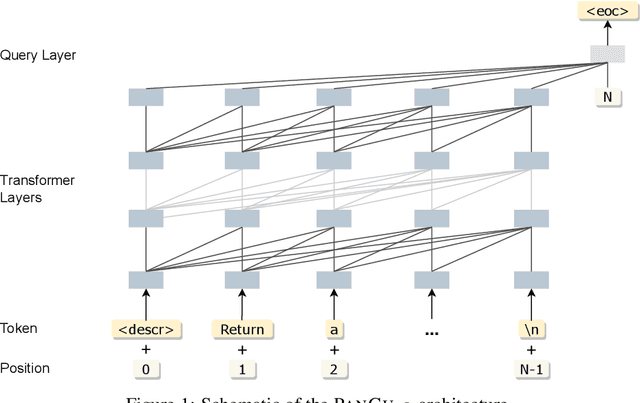
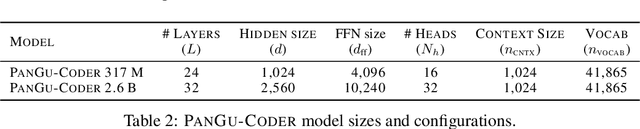
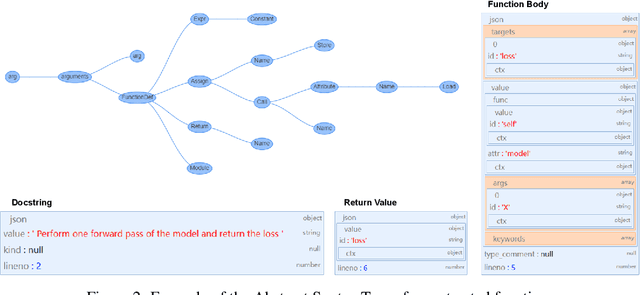
We present PanGu-Coder, a pretrained decoder-only language model adopting the PanGu-Alpha architecture for text-to-code generation, i.e. the synthesis of programming language solutions given a natural language problem description. We train PanGu-Coder using a two-stage strategy: the first stage employs Causal Language Modelling (CLM) to pre-train on raw programming language data, while the second stage uses a combination of Causal Language Modelling and Masked Language Modelling (MLM) training objectives that focus on the downstream task of text-to-code generation and train on loosely curated pairs of natural language program definitions and code functions. Finally, we discuss PanGu-Coder-FT, which is fine-tuned on a combination of competitive programming problems and code with continuous integration tests. We evaluate PanGu-Coder with a focus on whether it generates functionally correct programs and demonstrate that it achieves equivalent or better performance than similarly sized models, such as CodeX, while attending a smaller context window and training on less data.
Diffusion-Based Voice Conversion with Fast Maximum Likelihood Sampling Scheme
Sep 28, 2021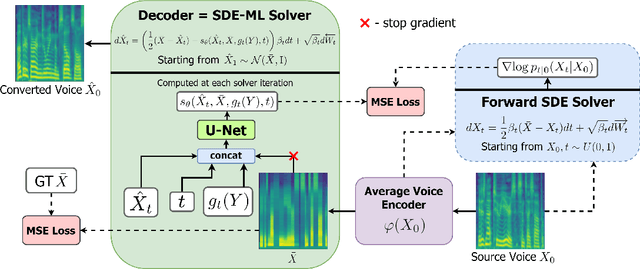

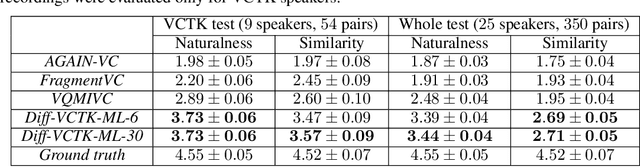

Voice conversion is a common speech synthesis task which can be solved in different ways depending on a particular real-world scenario. The most challenging one often referred to as one-shot many-to-many voice conversion consists in copying the target voice from only one reference utterance in the most general case when both source and target speakers do not belong to the training dataset. We present a scalable high-quality solution based on diffusion probabilistic modeling and demonstrate its superior quality compared to state-of-the-art one-shot voice conversion approaches. Moreover, focusing on real-time applications, we investigate general principles which can make diffusion models faster while keeping synthesis quality at a high level. As a result, we develop a novel Stochastic Differential Equations solver suitable for various diffusion model types and generative tasks as shown through empirical studies and justify it by theoretical analysis.