 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudioSAE: Towards Understanding of Audio-Processing Models with Sparse AutoEncoders
Feb 04, 2026Sparse Autoencoders (SAEs) are powerful tools for interpreting neural representations, yet their use in audio remains underexplored. We train SAEs across all encoder layers of Whisper and HuBERT, provide an extensive evaluation of their stability, interpretability, and show their practical utility. Over 50% of the features remain consistent across random seeds, and reconstruction quality is preserved. SAE features capture general acoustic and semantic information as well as specific events, including environmental noises and paralinguistic sounds (e.g. laughter, whispering) and disentangle them effectively, requiring removal of only 19-27% of features to erase a concept. Feature steering reduces Whisper's false speech detections by 70% with negligible WER increase, demonstrating real-world applicability. Finally, we find SAE features correlated with human EEG activity during speech perception, indicating alignment with human neural processing. The code and checkpoints are available at https://github.com/audiosae/audiosae_demo.
Improving Diffusion Models's Data-Corruption Resistance using Scheduled Pseudo-Huber Loss
Mar 25, 2024Diffusion models are known to be vulnerable to outliers in training data. In this paper we study an alternative diffusion loss function, which can preserve the high quality of generated data like the original squared $L_{2}$ loss while at the same time being robust to outliers. We propose to use pseudo-Huber loss function with a time-dependent parameter to allow for the trade-off between robustness on the most vulnerable early reverse-diffusion steps and fine details restoration on the final steps. We show that pseudo-Huber loss with the time-dependent parameter exhibits better performance on corrupted datasets in both image and audio domains. In addition, the loss function we propose can potentially help diffusion models to resist dataset corruption while not requiring data filtering or purification compared to conventional training algorithms.
Diffusion-Based Voice Conversion with Fast Maximum Likelihood Sampling Scheme
Sep 28, 2021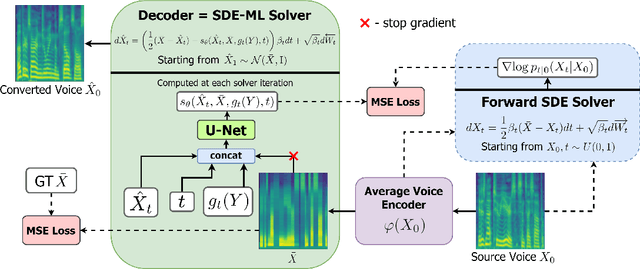

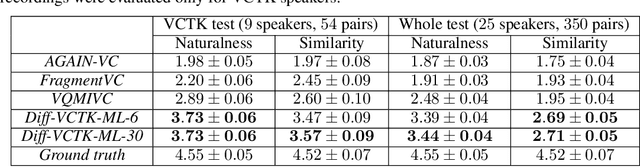

Voice conversion is a common speech synthesis task which can be solved in different ways depending on a particular real-world scenario. The most challenging one often referred to as one-shot many-to-many voice conversion consists in copying the target voice from only one reference utterance in the most general case when both source and target speakers do not belong to the training dataset. We present a scalable high-quality solution based on diffusion probabilistic modeling and demonstrate its superior quality compared to state-of-the-art one-shot voice conversion approaches. Moreover, focusing on real-time applications, we investigate general principles which can make diffusion models faster while keeping synthesis quality at a high level. As a result, we develop a novel Stochastic Differential Equations solver suitable for various diffusion model types and generative tasks as shown through empirical studies and justify it by theoretical analysis.
Grad-TTS: A Diffusion Probabilistic Model for Text-to-Speech
May 13, 2021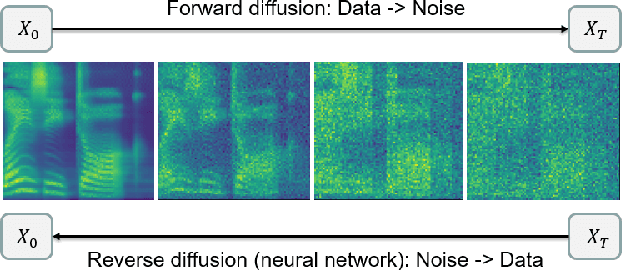
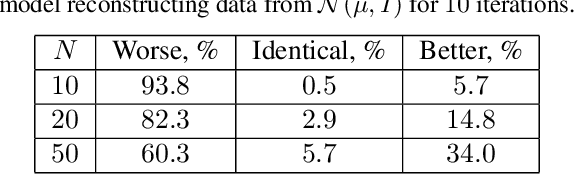

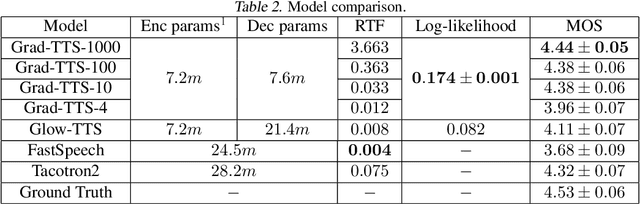
Recently, denoising diffusion probabilistic models and generative score matching have shown high potential in modelling complex data distributions while stochastic calculus has provided a unified point of view on these techniques allowing for flexible inference schemes. In this paper we introduce Grad-TTS, a novel text-to-speech model with score-based decoder producing mel-spectrograms by gradually transforming noise predicted by encoder and aligned with text input by means of Monotonic Alignment Search. The framework of stochastic differential equations helps us to generalize conventional diffusion probabilistic models to the case of reconstructing data from noise with different parameters and allows to make this reconstruction flexible by explicitly controlling trade-off between sound quality and inference speed. Subjective human evaluation shows that Grad-TTS is competitive with state-of-the-art text-to-speech approaches in terms of Mean Opinion Score. We will make the code publicly available shortly.
Fine-tuning of Language Models with Discriminator
Nov 12, 2018


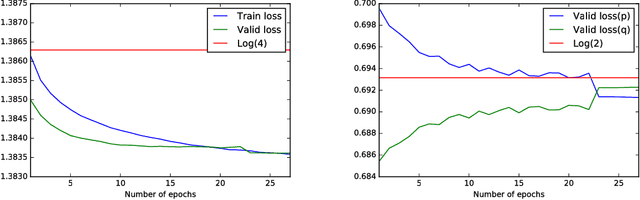
Cross-entropy loss is a common choice when it comes to multiclass classification tasks and language modeling in particular. Minimizing this loss results in language models of very good quality. We show that it is possible to fine-tune these models and make them perform even better if they are fine-tuned with sum of cross-entropy loss and reverse Kullback-Leibler divergence. The latter is estimated using discriminator network that we train in advance. During fine-tuning we can use this discriminator to figure out if probabilities of some words are overestimated and reduce them in this case. The novel approach that we propose allows us to reach state-of-the-art quality on Penn TreeBank: perplexity of the fine-tuned model drops down by more than 0.5 and is now below 54.0 in standard evaluation setting; however, in dynamic evaluation framework the improvement is much less perceptible. Our fine-tuning algorithm is rather fast and requires almost no hyperparameter tuning. We test it on different datasets including WikiText-2 and large-scale dataset. In the former case we also reach state-of-the-art results.
Differentially Private Distributed Learning for Language Modeling Tasks
Mar 06, 2018


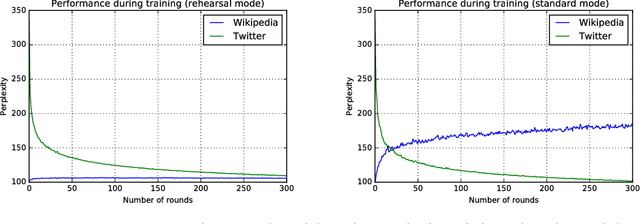
One of the big challenges in machine learning applications is that training data can be different from the real-world data faced by the algorithm. In language modeling, users' language (e.g. in private messaging) could change in a year and be completely different from what we observe in publicly available data. At the same time, public data can be used for obtaining general knowledge (i.e. general model of English). We study approaches to distributed fine-tuning of a general model on user private data with the additional requirements of maintaining the quality on the general data and minimization of communication costs. We propose a novel technique that significantly improves prediction quality on users' language compared to a general model and outperforms gradient compression methods in terms of communication efficiency. The proposed procedure is fast and leads to an almost 70% perplexity reduction and 8.7 percentage point improvement in keystroke saving rate on informal English texts. We also show that the range of tasks our approach is applicable to is not limited by language modeling only. Finally, we propose an experimental framework for evaluating differential privacy of distributed training of language models and show that our approach has good privacy guarantees.