 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Distributed Learning for Language Modeling Tasks
Mar 06, 2018


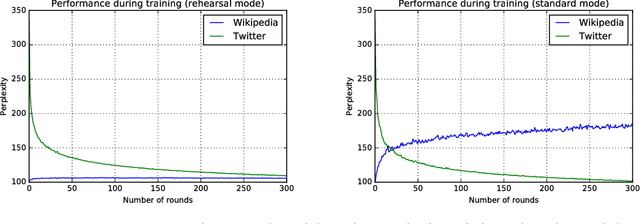
One of the big challenges in machine learning applications is that training data can be different from the real-world data faced by the algorithm. In language modeling, users' language (e.g. in private messaging) could change in a year and be completely different from what we observe in publicly available data. At the same time, public data can be used for obtaining general knowledge (i.e. general model of English). We study approaches to distributed fine-tuning of a general model on user private data with the additional requirements of maintaining the quality on the general data and minimization of communication costs. We propose a novel technique that significantly improves prediction quality on users' language compared to a general model and outperforms gradient compression methods in terms of communication efficiency. The proposed procedure is fast and leads to an almost 70% perplexity reduction and 8.7 percentage point improvement in keystroke saving rate on informal English texts. We also show that the range of tasks our approach is applicable to is not limited by language modeling only. Finally, we propose an experimental framework for evaluating differential privacy of distributed training of language models and show that our approach has good privacy guarantees.