 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning of Language Models with Discriminator
Paper and Code
Nov 12, 2018


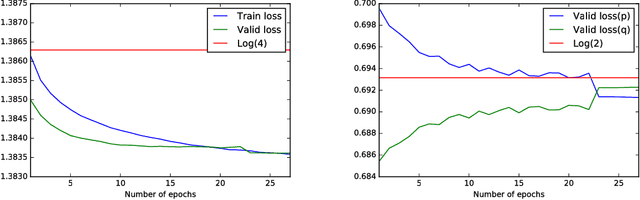
Cross-entropy loss is a common choice when it comes to multiclass classification tasks and language modeling in particular. Minimizing this loss results in language models of very good quality. We show that it is possible to fine-tune these models and make them perform even better if they are fine-tuned with sum of cross-entropy loss and reverse Kullback-Leibler divergence. The latter is estimated using discriminator network that we train in advance. During fine-tuning we can use this discriminator to figure out if probabilities of some words are overestimated and reduce them in this case. The novel approach that we propose allows us to reach state-of-the-art quality on Penn TreeBank: perplexity of the fine-tuned model drops down by more than 0.5 and is now below 54.0 in standard evaluation setting; however, in dynamic evaluation framework the improvement is much less perceptible. Our fine-tuning algorithm is rather fast and requires almost no hyperparameter tuning. We test it on different datasets including WikiText-2 and large-scale dataset. In the former case we also reach state-of-the-art results.