 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanGu-Σ: Towards Trillion Parameter Language Model with Sparse Heterogeneous Computing
Mar 20, 2023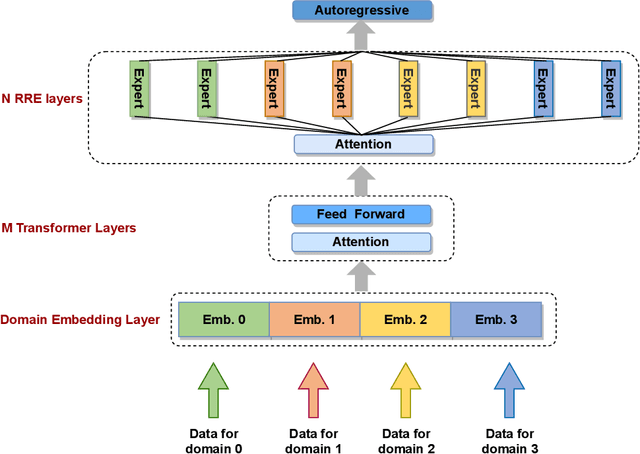

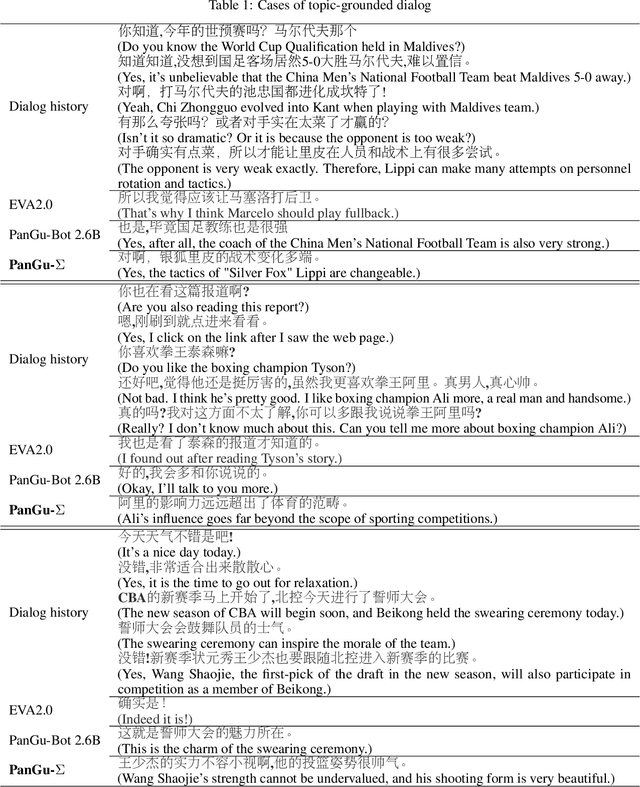
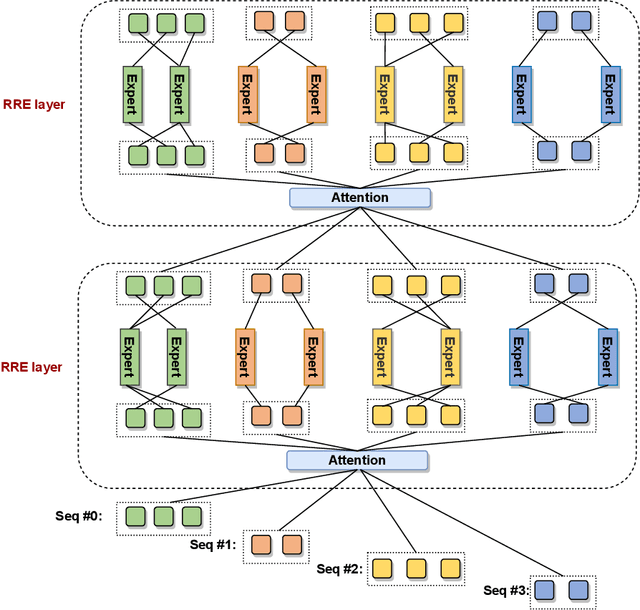
The scaling of large language models has greatly improved natural language understanding, generation, and reasoning. In this work, we develop a system that trained a trillion-parameter language model on a cluster of Ascend 910 AI processors and MindSpore framework, and present the language model with 1.085T parameters named PanGu-{\Sigma}. With parameter inherent from PanGu-{\alpha}, we extend the dense Transformer model to sparse one with Random Routed Experts (RRE), and efficiently train the model over 329B tokens by using Expert Computation and Storage Separation(ECSS). This resulted in a 6.3x increase in training throughput through heterogeneous computing. Our experimental findings show that PanGu-{\Sigma} provides state-of-the-art performance in zero-shot learning of various Chinese NLP downstream tasks. Moreover, it demonstrates strong abilities when fine-tuned in application data of open-domain dialogue, question answering, machine translation and code generation.