 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanGu-Σ: Towards Trillion Parameter Language Model with Sparse Heterogeneous Computing
Mar 20, 2023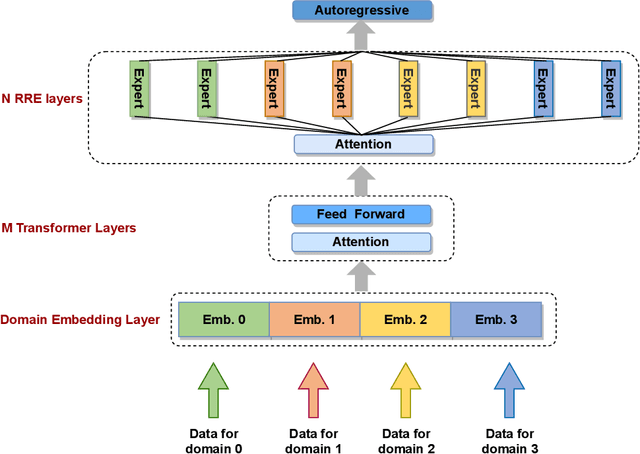

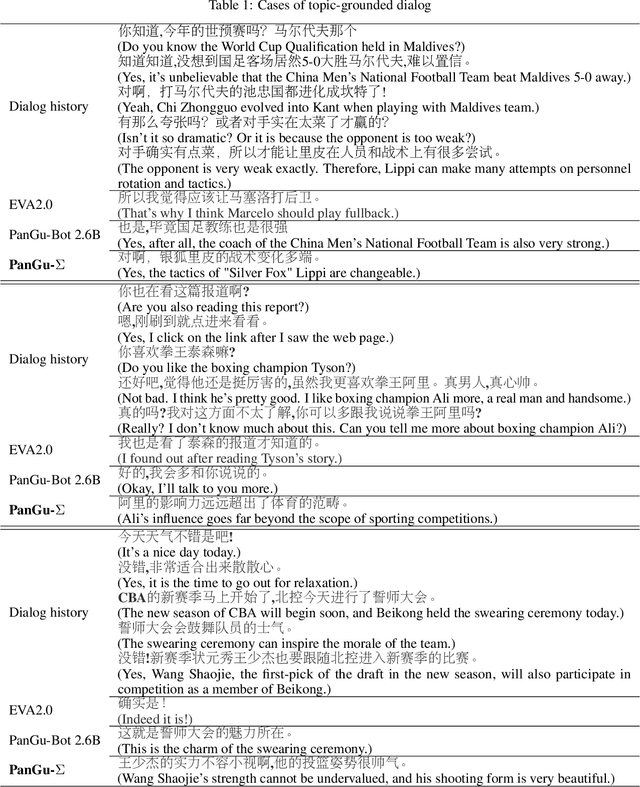
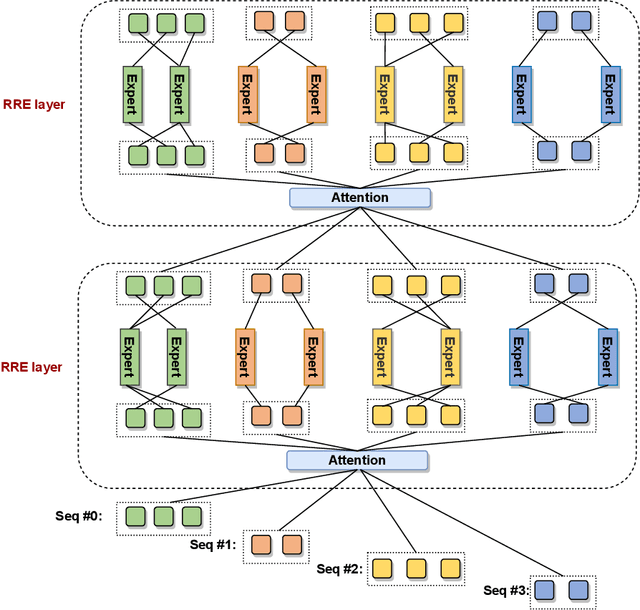
The scaling of large language models has greatly improved natural language understanding, generation, and reasoning. In this work, we develop a system that trained a trillion-parameter language model on a cluster of Ascend 910 AI processors and MindSpore framework, and present the language model with 1.085T parameters named PanGu-{\Sigma}. With parameter inherent from PanGu-{\alpha}, we extend the dense Transformer model to sparse one with Random Routed Experts (RRE), and efficiently train the model over 329B tokens by using Expert Computation and Storage Separation(ECSS). This resulted in a 6.3x increase in training throughput through heterogeneous computing. Our experimental findings show that PanGu-{\Sigma} provides state-of-the-art performance in zero-shot learning of various Chinese NLP downstream tasks. Moreover, it demonstrates strong abilities when fine-tuned in application data of open-domain dialogue, question answering, machine translation and code generation.
PanGu-$α$: Large-scale Autoregressive Pretrained Chinese Language Models with Auto-parallel Computation
Apr 26, 2021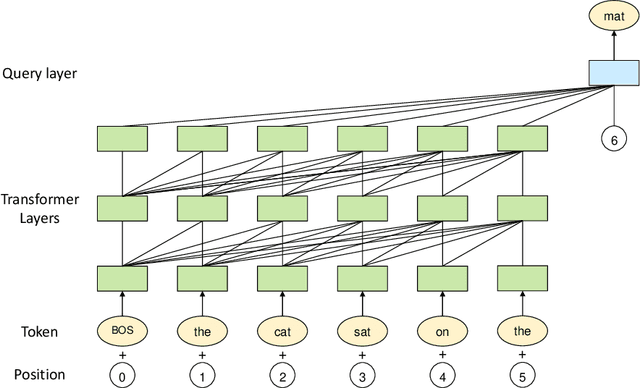
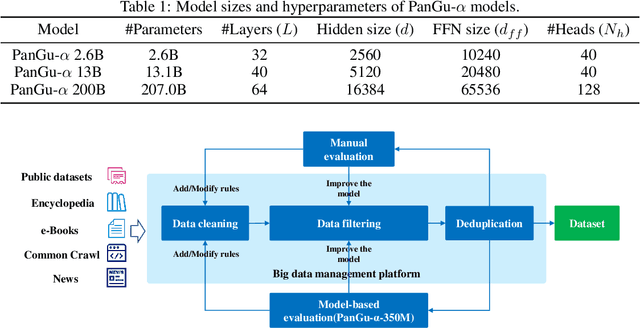
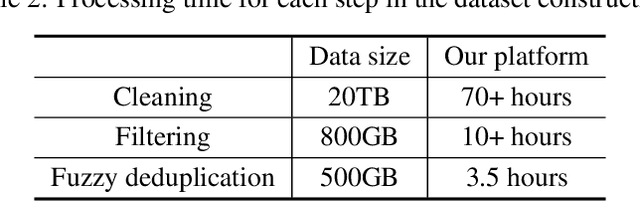
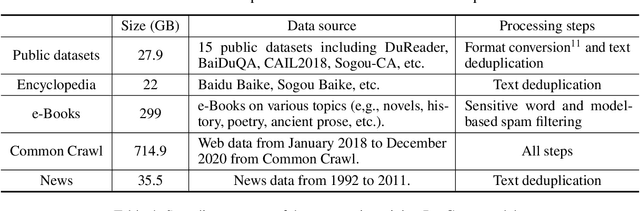
Large-scale Pretrained Language Models (PLMs) have become the new paradigm for Natural Language Processing (NLP). PLMs with hundreds of billions parameters such as GPT-3 have demonstrated strong performances on natural language understanding and generation with \textit{few-shot in-context} learning. In this work, we present our practice on training large-scale autoregressive language models named PanGu-$\alpha$, with up to 200 billion parameters. PanGu-$\alpha$ is developed under the MindSpore and trained on a cluster of 2048 Ascend 910 AI processors. The training parallelism strategy is implemented based on MindSpore Auto-parallel, which composes five parallelism dimensions to scale the training task to 2048 processors efficiently, including data parallelism, op-level model parallelism, pipeline model parallelism, optimizer model parallelism and rematerialization. To enhance the generalization ability of PanGu-$\alpha$, we collect 1.1TB high-quality Chinese data from a wide range of domains to pretrain the model. We empirically test the generation ability of PanGu-$\alpha$ in various scenarios including text summarization, question answering, dialogue generation, etc. Moreover, we investigate the effect of model scales on the few-shot performances across a broad range of Chinese NLP tasks. The experimental results demonstrate the superior capabilities of PanGu-$\alpha$ in performing various tasks under few-shot or zero-shot settings.
Task-Oriented Conversation Generation Using Heterogeneous Memory Networks
Sep 25, 2019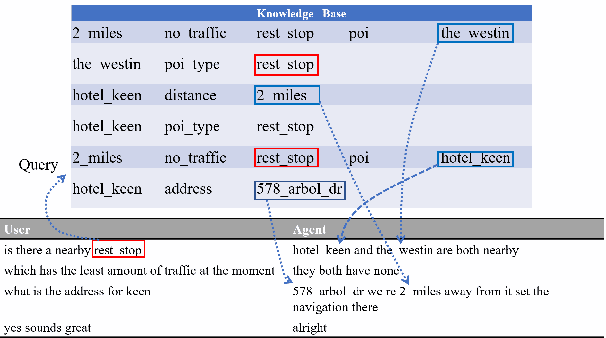



How to incorporate external knowledge into a neural dialogue model is critically important for dialogue systems to behave like real humans. To handle this problem, memory networks are usually a great choice and a promising way. However, existing memory networks do not perform well when leveraging heterogeneous information from different sources. In this paper, we propose a novel and versatile external memory networks called Heterogeneous Memory Networks (HMNs), to simultaneously utilize user utterances, dialogue history and background knowledge tuples. In our method, historical sequential dialogues are encoded and stored into the context-aware memory enhanced by gating mechanism while grounding knowledge tuples are encoded and stored into the context-free memory. During decoding, the decoder augmented with HMNs recurrently selects each word in one response utterance from these two memories and a general vocabulary. Experimental results on multiple real-world datasets show that HMNs significantly outperform the state-of-the-art data-driven task-oriented dialogue models in most domains.
Teacher-Student Framework Enhanced Multi-domain Dialogue Generation
Aug 20, 2019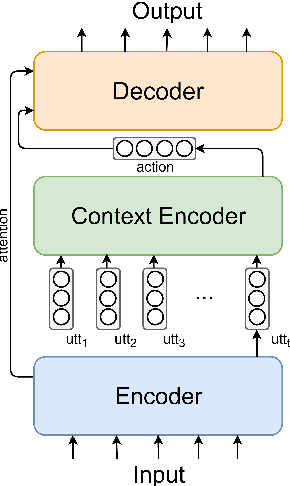
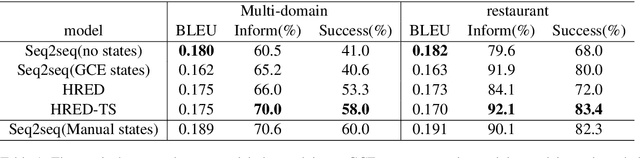
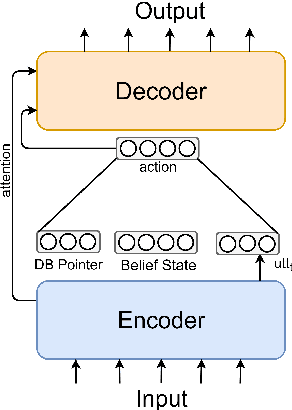
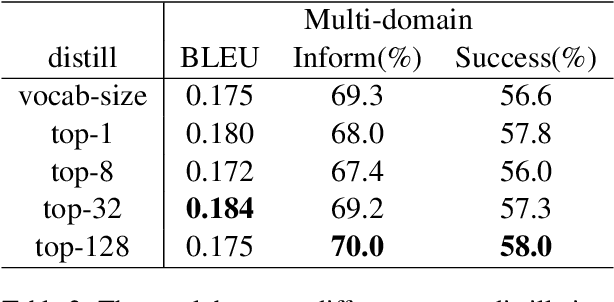
Dialogue systems dealing with multi-domain tasks are highly required. How to record the state remains a key problem in a task-oriented dialogue system. Normally we use human-defined features as dialogue states and apply a state tracker to extract these features. However, the performance of such a system is limited by the error propagation of a state tracker. In this paper, we propose a dialogue generation model that needs no external state trackers and still benefits from human-labeled semantic data. By using a teacher-student framework, several teacher models are firstly trained in their individual domains, learn dialogue policies from labeled states. And then the learned knowledge and experience are merged and transferred to a universal student model, which takes raw utterance as its input. Experiments show that the dialogue system trained under our framework outperforms the one uses a belief tracker.