 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiCoder: Multi-Programming-Lingual Pre-Training for Low-Resource Code Completion
Dec 19, 2022Code completion is a valuable topic in both academia and industry. Recently, large-scale mono-programming-lingual (MonoPL) pre-training models have been proposed to boost the performance of code completion. However, the code completion on low-resource programming languages (PL) is difficult for the data-driven paradigm, while there are plenty of developers using low-resource PLs. On the other hand, there are few studies exploring the effects of multi-programming-lingual (MultiPL) pre-training for the code completion, especially the impact on low-resource programming languages. To this end, we propose the MultiCoder to enhance the low-resource code completion via MultiPL pre-training and MultiPL Mixture-of-Experts (MoE) layers. We further propose a novel PL-level MoE routing strategy (PL-MoE) for improving the code completion on all PLs. Experimental results on CodeXGLUE and MultiCC demonstrate that 1) the proposed MultiCoder significantly outperforms the MonoPL baselines on low-resource programming languages, and 2) the PL-MoE module further boosts the performance on six programming languages. In addition, we analyze the effects of the proposed method in details and explore the effectiveness of our method in a variety of scenarios.
PanGu-Coder: Program Synthesis with Function-Level Language Modeling
Jul 22, 2022
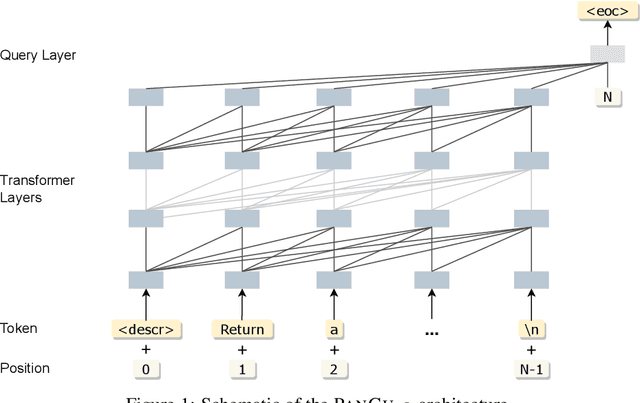
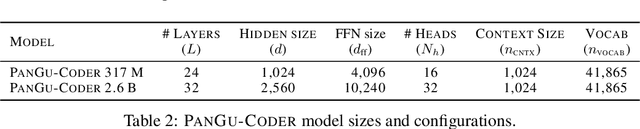
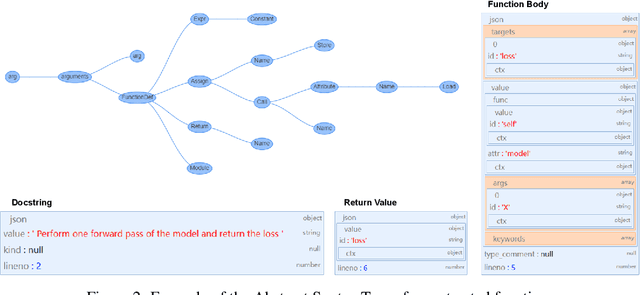
We present PanGu-Coder, a pretrained decoder-only language model adopting the PanGu-Alpha architecture for text-to-code generation, i.e. the synthesis of programming language solutions given a natural language problem description. We train PanGu-Coder using a two-stage strategy: the first stage employs Causal Language Modelling (CLM) to pre-train on raw programming language data, while the second stage uses a combination of Causal Language Modelling and Masked Language Modelling (MLM) training objectives that focus on the downstream task of text-to-code generation and train on loosely curated pairs of natural language program definitions and code functions. Finally, we discuss PanGu-Coder-FT, which is fine-tuned on a combination of competitive programming problems and code with continuous integration tests. We evaluate PanGu-Coder with a focus on whether it generates functionally correct programs and demonstrate that it achieves equivalent or better performance than similarly sized models, such as CodeX, while attending a smaller context window and training on less data.
FreeTransfer-X: Safe and Label-Free Cross-Lingual Transfer from Off-the-Shelf Models
Jun 14, 2022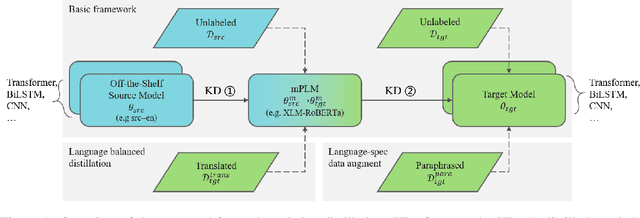
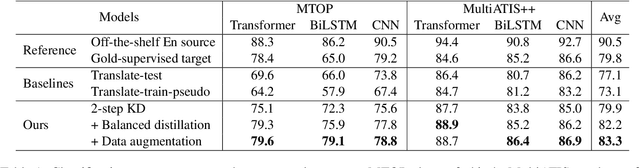
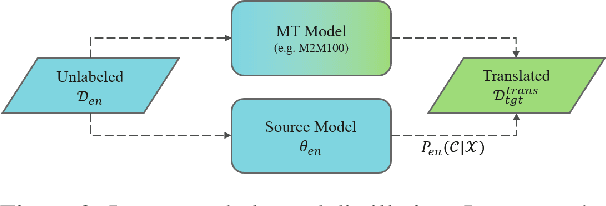
Cross-lingual transfer (CLT) is of various applications. However, labeled cross-lingual corpus is expensive or even inaccessible, especially in the fields where labels are private, such as diagnostic results of symptoms in medicine and user profiles in business. Nevertheless, there are off-the-shelf models in these sensitive fields. Instead of pursuing the original labels, a workaround for CLT is to transfer knowledge from the off-the-shelf models without labels. To this end, we define a novel CLT problem named FreeTransfer-X that aims to achieve knowledge transfer from the off-the-shelf models in rich-resource languages. To address the problem, we propose a 2-step knowledge distillation (KD, Hinton et al., 2015) framework based on multilingual pre-trained language models (mPLM). The significant improvement over strong neural machine translation (NMT) baselines demonstrates the effectiveness of the proposed method. In addition to reducing annotation cost and protecting private labels, the proposed method is compatible with different networks and easy to be deployed. Finally, a range of analyses indicate the great potential of the proposed method.
Learning Multilingual Representation for Natural Language Understanding with Enhanced Cross-Lingual Supervision
Jun 09, 2021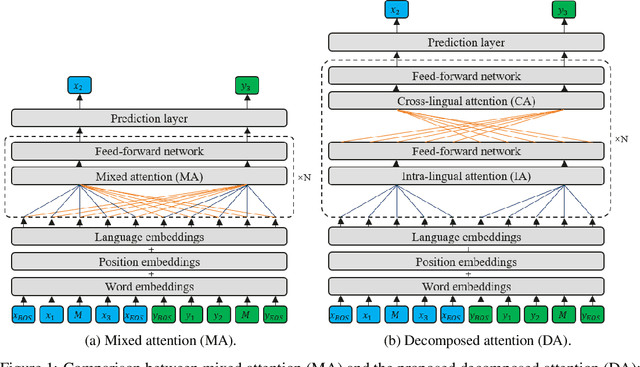

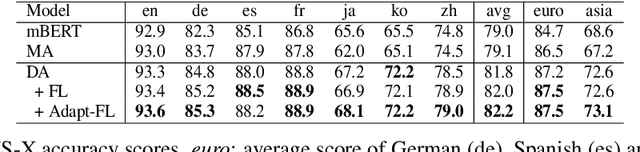
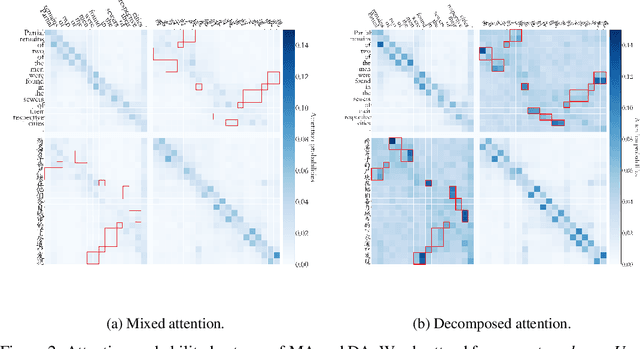
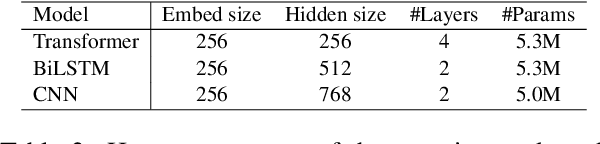
Recently, pre-training multilingual language models has shown great potential in learning multilingual representation, a crucial topic of natural language processing. Prior works generally use a single mixed attention (MA) module, following TLM (Conneau and Lample, 2019), for attending to intra-lingual and cross-lingual contexts equivalently and simultaneously. In this paper, we propose a network named decomposed attention (DA) as a replacement of MA. The DA consists of an intra-lingual attention (IA) and a cross-lingual attention (CA), which model intralingual and cross-lingual supervisions respectively. In addition, we introduce a language-adaptive re-weighting strategy during training to further boost the model's performance. Experiments on various cross-lingual natural language understanding (NLU) tasks show that the proposed architecture and learning strategy significantly improve the model's cross-lingual transferability.
Training Multilingual Pre-trained Language Model with Byte-level Subwords
Jan 23, 2021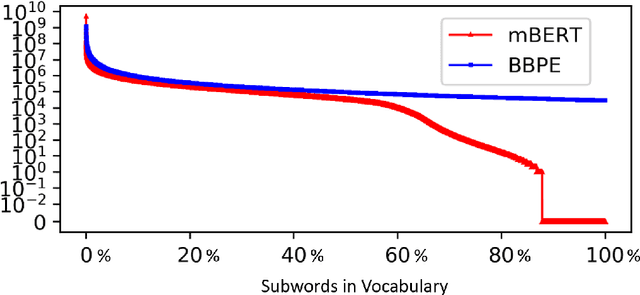
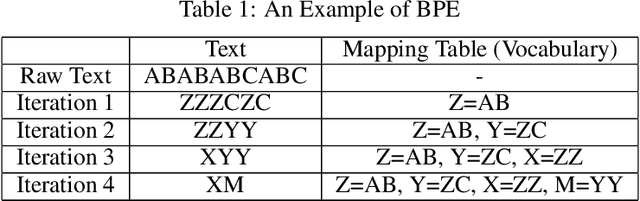

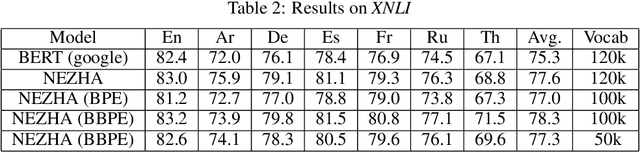
The pre-trained language models have achieved great successes in various natural language understanding (NLU) tasks due to its capacity to capture the deep contextualized information in text by pre-training on large-scale corpora. One of the fundamental components in pre-trained language models is the vocabulary, especially for training multilingual models on many different languages. In the technical report, we present our practices on training multilingual pre-trained language models with BBPE: Byte-Level BPE (i.e., Byte Pair Encoding). In the experiment, we adopted the architecture of NEZHA as the underlying pre-trained language model and the results show that NEZHA trained with byte-level subwords consistently outperforms Google multilingual BERT and vanilla NEZHA by a notable margin in several multilingual NLU tasks. We release the source code of our byte-level vocabulary building tools and the multilingual pre-trained language models.
Zero-Shot Paraphrase Generation with Multilingual Language Models
Nov 09, 2019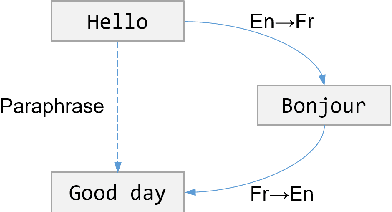
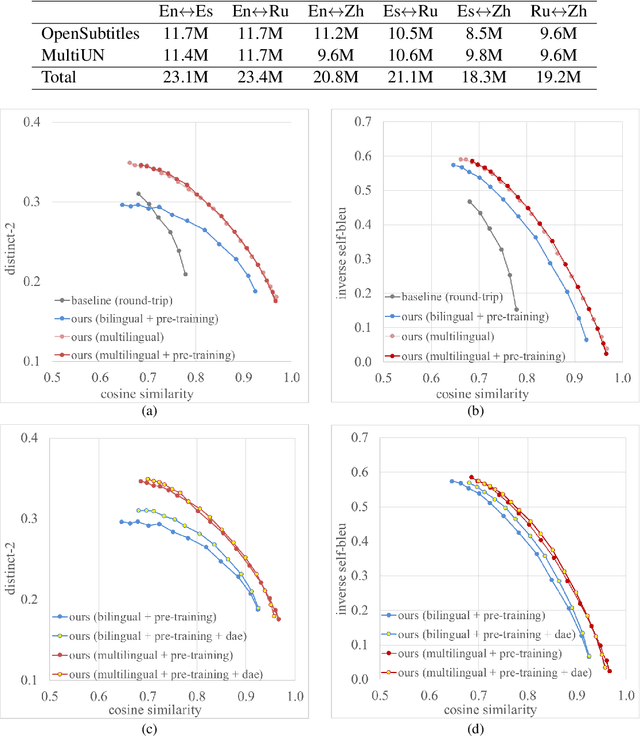
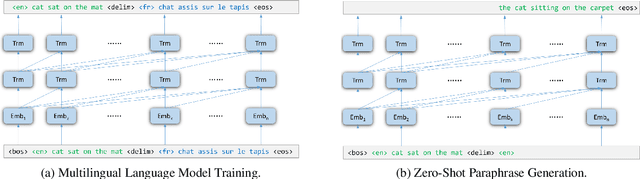
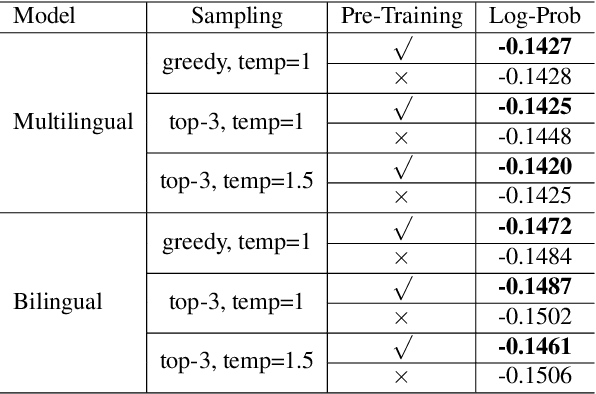
Leveraging multilingual parallel texts to automatically generate paraphrases has drawn much attention as size of high-quality paraphrase corpus is limited. Round-trip translation, also known as the pivoting method, is a typical approach to this end. However, we notice that the pivoting process involves multiple machine translation models and is likely to incur semantic drift during the two-step translations. In this paper, inspired by the Transformer-based language models, we propose a simple and unified paraphrasing model, which is purely trained on multilingual parallel data and can conduct zero-shot paraphrase generation in one step. Compared with the pivoting approach, paraphrases generated by our model is more semantically similar to the input sentence. Moreover, since our model shares the same architecture as GPT (Radford et al., 2018), we are able to pre-train the model on large-scale unparallel corpus, which further improves the fluency of the output sentences. In addition, we introduce the mechanism of denoising auto-encoder (DAE) to improve diversity and robustness of the model. Experimental results show that our model surpasses the pivoting method in terms of relevance, diversity, fluency and efficiency.