 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Paraphrase Generation with Multilingual Language Models
Paper and Code
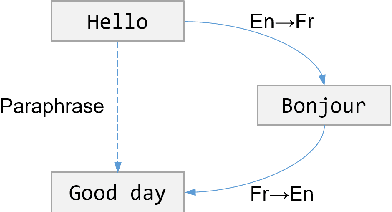
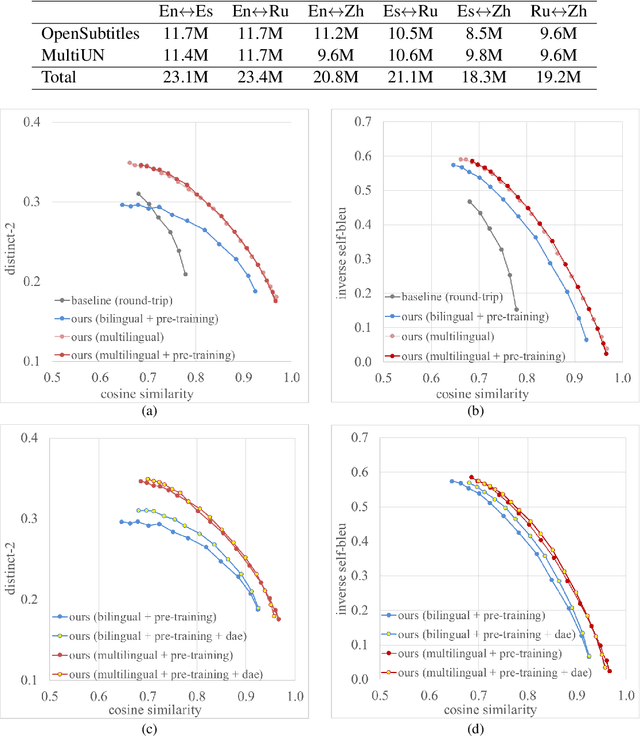
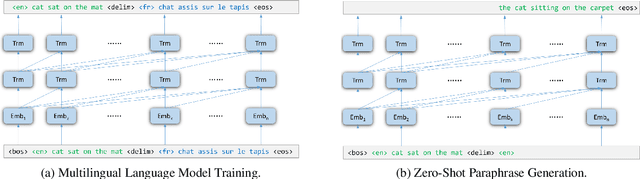
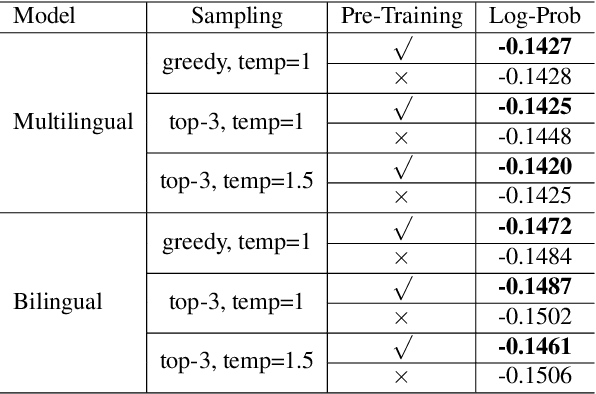
Leveraging multilingual parallel texts to automatically generate paraphrases has drawn much attention as size of high-quality paraphrase corpus is limited. Round-trip translation, also known as the pivoting method, is a typical approach to this end. However, we notice that the pivoting process involves multiple machine translation models and is likely to incur semantic drift during the two-step translations. In this paper, inspired by the Transformer-based language models, we propose a simple and unified paraphrasing model, which is purely trained on multilingual parallel data and can conduct zero-shot paraphrase generation in one step. Compared with the pivoting approach, paraphrases generated by our model is more semantically similar to the input sentence. Moreover, since our model shares the same architecture as GPT (Radford et al., 2018), we are able to pre-train the model on large-scale unparallel corpus, which further improves the fluency of the output sentences. In addition, we introduce the mechanism of denoising auto-encoder (DAE) to improve diversity and robustness of the model. Experimental results show that our model surpasses the pivoting method in terms of relevance, diversity, fluency and efficiency.