 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Mix or To Merge: Toward Multi-Domain Reinforcement Learning for Large Language Models
Feb 13, 2026Reinforcement Learning with Verifiable Rewards (RLVR) plays a key role in stimulating the explicit reasoning capability of Large Language Models (LLMs). We can achieve expert-level performance in some specific domains via RLVR, such as coding or math. When a general multi-domain expert-level model is required, we need to carefully consider the collaboration of RLVR across different domains. The current state-of-the-art models mainly employ two different training paradigms for multi-domain RLVR: mixed multi-task RLVR and separate RLVR followed by model merging. However, most of the works did not provide a detailed comparison and analysis about these paradigms. To this end, we choose multiple commonly used high-level tasks (e.g., math, coding, science, and instruction following) as our target domains and design extensive qualitative and quantitative experiments using open-source datasets. We find the RLVR across domains exhibits few mutual interferences, and reasoning-intensive domains demonstrate mutually synergistic effects. Furthermore, we analyze the internal mechanisms of mutual gains from the perspectives of weight space geometry, model prediction behavior, and information constraints. This project is named as M2RL that means Mixed multi-task training or separate training followed by model Merging for Reinforcement Learning, and the homepage is at https://github.com/mosAI25/M2RL
MeKi: Memory-based Expert Knowledge Injection for Efficient LLM Scaling
Feb 03, 2026Scaling Large Language Models (LLMs) typically relies on increasing the number of parameters or test-time computations to boost performance. However, these strategies are impractical for edge device deployment due to limited RAM and NPU resources. Despite hardware constraints, deploying performant LLM on edge devices such as smartphone remains crucial for user experience. To address this, we propose MeKi (Memory-based Expert Knowledge Injection), a novel system that scales LLM capacity via storage space rather than FLOPs. MeKi equips each Transformer layer with token-level memory experts that injects pre-stored semantic knowledge into the generation process. To bridge the gap between training capacity and inference efficiency, we employ a re-parameterization strategy to fold parameter matrices used during training into a compact static lookup table. By offloading the knowledge to ROM, MeKi decouples model capacity from computational cost, introducing zero inference latency overhead. Extensive experiments demonstrate that MeKi significantly outperforms dense LLM baselines with identical inference speed, validating the effectiveness of memory-based scaling paradigm for on-device LLMs. Project homepage is at https://github.com/ningding-o/MeKi.
Towards Proprioception-Aware Embodied Planning for Dual-Arm Humanoid Robots
Oct 09, 2025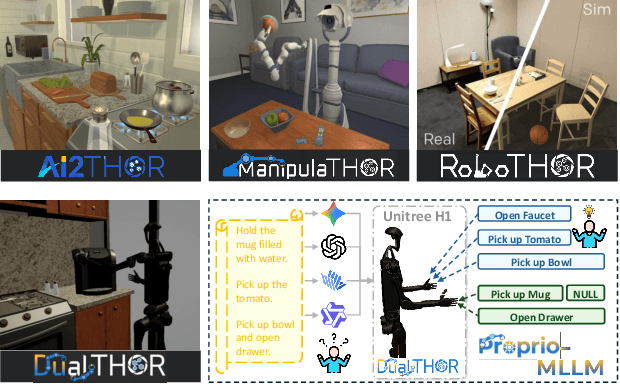


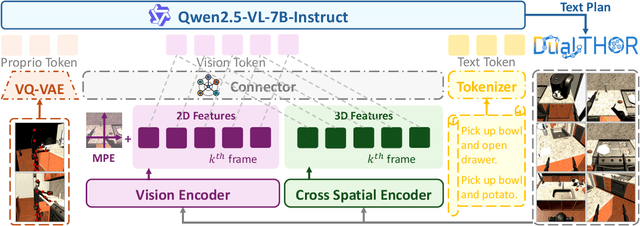
In recent years, Multimodal Large Language Models (MLLMs) have demonstrated the ability to serve as high-level planners, enabling robots to follow complex human instructions. However, their effectiveness, especially in long-horizon tasks involving dual-arm humanoid robots, remains limited. This limitation arises from two main challenges: (i) the absence of simulation platforms that systematically support task evaluation and data collection for humanoid robots, and (ii) the insufficient embodiment awareness of current MLLMs, which hinders reasoning about dual-arm selection logic and body positions during planning. To address these issues, we present DualTHOR, a new dual-arm humanoid simulator, with continuous transition and a contingency mechanism. Building on this platform, we propose Proprio-MLLM, a model that enhances embodiment awareness by incorporating proprioceptive information with motion-based position embedding and a cross-spatial encoder. Experiments show that, while existing MLLMs struggle in this environment, Proprio-MLLM achieves an average improvement of 19.75% in planning performance. Our work provides both an essential simulation platform and an effective model to advance embodied intelligence in humanoid robotics. The code is available at https://anonymous.4open.science/r/DualTHOR-5F3B.
EAQuant: Enhancing Post-Training Quantization for MoE Models via Expert-Aware Optimization
Jun 16, 2025Mixture-of-Experts (MoE) models have emerged as a cornerstone of large-scale deep learning by efficiently distributing computation and enhancing performance. However, their unique architecture-characterized by sparse expert activation and dynamic routing mechanisms-introduces inherent complexities that challenge conventional quantization techniques. Existing post-training quantization (PTQ) methods struggle to address activation outliers, router consistency and sparse expert calibration, leading to significant performance degradation. To bridge this gap, we propose EAQuant, a novel PTQ framework tailored for MoE architectures. Our method systematically tackles these challenges through three key innovations: (1) expert-aware smoothing aggregation to suppress activation outliers and stabilize quantization, (2) router logits distribution alignment to preserve expert selection consistency post-quantization, and (3) expert-level calibration data balance to optimize sparsely activated experts. Extensive experiments across W4A4 and extreme W3A4 quantization configurations demonstrate that EAQuant significantly outperforms existing methods, achieving average score improvements of 1.15 - 2.28% across three diverse MoE architectures, with particularly pronounced gains in reasoning tasks and robust performance retention under aggressive quantization. By integrating these innovations, EAQuant establishes a new state-of-the-art for high-precision, efficient MoE model compression. Our code is available at https://github.com/darren-fzq/EAQuant.
Pangu Embedded: An Efficient Dual-system LLM Reasoner with Metacognition
May 29, 2025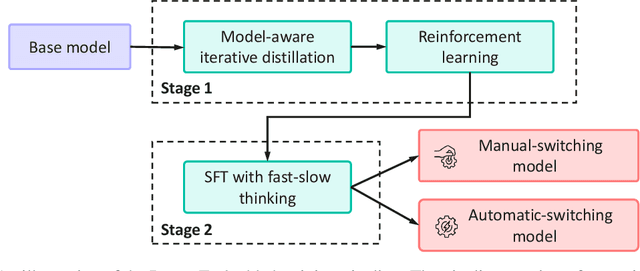

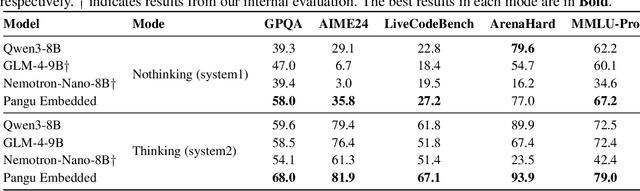
This work presents Pangu Embedded, an efficient Large Language Model (LLM) reasoner developed on Ascend Neural Processing Units (NPUs), featuring flexible fast and slow thinking capabilities. Pangu Embedded addresses the significant computational costs and inference latency challenges prevalent in existing reasoning-optimized LLMs. We propose a two-stage training framework for its construction. In Stage 1, the model is finetuned via an iterative distillation process, incorporating inter-iteration model merging to effectively aggregate complementary knowledge. This is followed by reinforcement learning on Ascend clusters, optimized by a latency-tolerant scheduler that combines stale synchronous parallelism with prioritized data queues. The RL process is guided by a Multi-source Adaptive Reward System (MARS), which generates dynamic, task-specific reward signals using deterministic metrics and lightweight LLM evaluators for mathematics, coding, and general problem-solving tasks. Stage 2 introduces a dual-system framework, endowing Pangu Embedded with a "fast" mode for routine queries and a deeper "slow" mode for complex inference. This framework offers both manual mode switching for user control and an automatic, complexity-aware mode selection mechanism that dynamically allocates computational resources to balance latency and reasoning depth. Experimental results on benchmarks including AIME 2024, GPQA, and LiveCodeBench demonstrate that Pangu Embedded with 7B parameters, outperforms similar-size models like Qwen3-8B and GLM4-9B. It delivers rapid responses and state-of-the-art reasoning quality within a single, unified model architecture, highlighting a promising direction for developing powerful yet practically deployable LLM reasoners.
Pangu Pro MoE: Mixture of Grouped Experts for Efficient Sparsity
May 28, 2025The surgence of Mixture of Experts (MoE) in Large Language Models promises a small price of execution cost for a much larger model parameter count and learning capacity, because only a small fraction of parameters are activated for each input token. However, it is commonly observed that some experts are activated far more often than others, leading to system inefficiency when running the experts on different devices in parallel. Therefore, we introduce Mixture of Grouped Experts (MoGE), which groups the experts during selection and balances the expert workload better than MoE in nature. It constrains tokens to activate an equal number of experts within each predefined expert group. When a model execution is distributed on multiple devices, this architectural design ensures a balanced computational load across devices, significantly enhancing throughput, particularly for the inference phase. Further, we build Pangu Pro MoE on Ascend NPUs, a sparse model based on MoGE with 72 billion total parameters, 16 billion of which are activated for each token. The configuration of Pangu Pro MoE is optimized for Ascend 300I Duo and 800I A2 through extensive system simulation studies. Our experiments indicate that MoGE indeed leads to better expert load balancing and more efficient execution for both model training and inference on Ascend NPUs. The inference performance of Pangu Pro MoE achieves 1148 tokens/s per card and can be further improved to 1528 tokens/s per card by speculative acceleration, outperforming comparable 32B and 72B Dense models. Furthermore, we achieve an excellent cost-to-performance ratio for model inference on Ascend 300I Duo. Our studies show that Ascend NPUs are capable of training Pangu Pro MoE with massive parallelization to make it a leading model within the sub-100B total parameter class, outperforming prominent open-source models like GLM-Z1-32B and Qwen3-32B.
SlimLLM: Accurate Structured Pruning for Large Language Models
May 28, 2025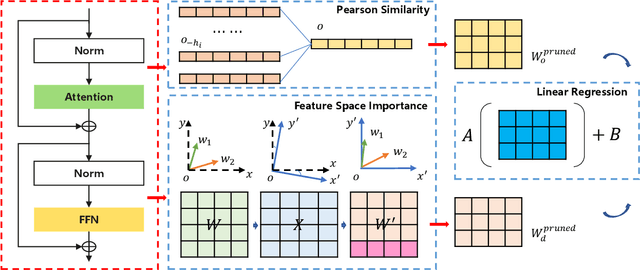
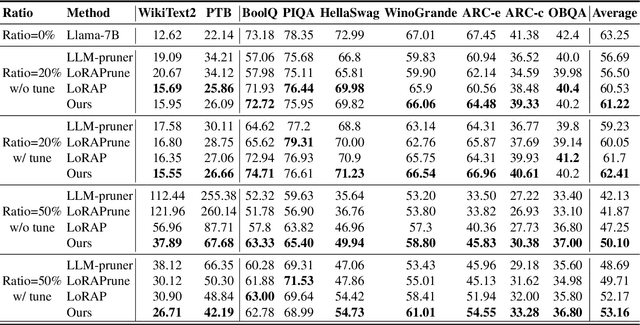

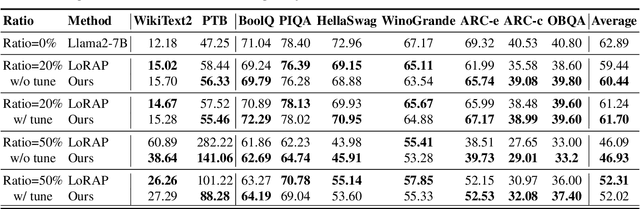
Large language models(LLMs) have garnered significant attention and demonstrated impressive capabilities in a wide range of applications. However, due to their enormous computational costs, the deployment and application of LLMs are often severely limited. To address this issue, structured pruning is an effective solution to compress the parameters of LLMs. Determining the importance of each sub-module in LLMs and minimizing performance loss are critical issues that need to be carefully addressed in structured pruning. In this paper, we propose an effective and fast structured pruning method named SlimLLM for large language models. For channel and attention head pruning, we evaluate the importance based on the entire channel or head, rather than merely aggregating the importance of individual elements within a sub-module. This approach enables a more holistic consideration of the interdependence among elements within the sub-module. In addition, we design a simple linear regression strategy for the output matrix to quickly recover performance. We also propose layer-based importance ratio to determine the pruning ratio for each layer. Based on the LLaMA benchmark results, our SlimLLM outperforms other methods and achieves state-of-the-art performance.
Pangu Light: Weight Re-Initialization for Pruning and Accelerating LLMs
May 26, 2025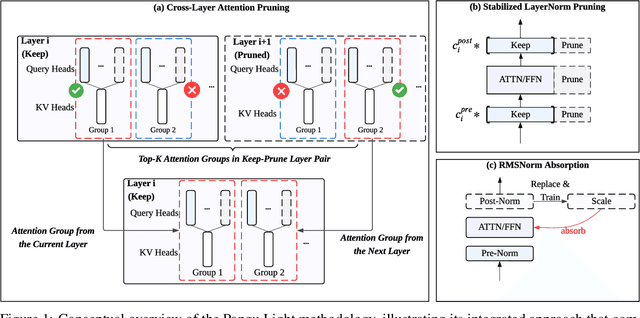

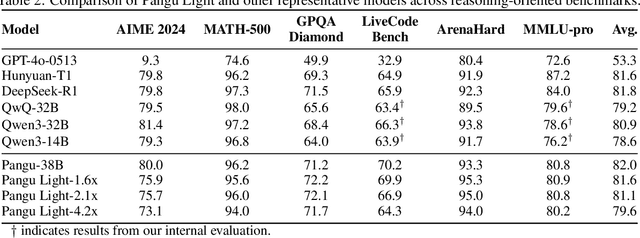
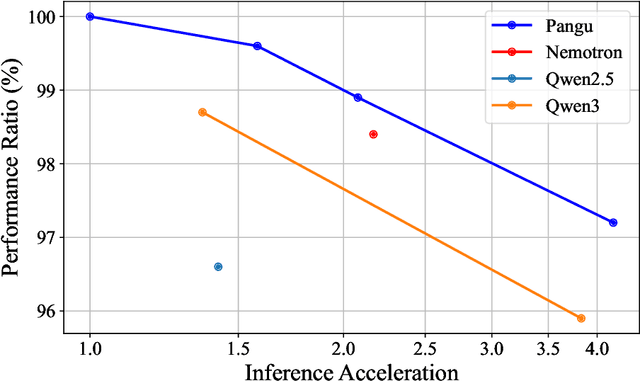
Large Language Models (LLMs) deliver state-of-the-art capabilities across numerous tasks, but their immense size and inference costs pose significant computational challenges for practical deployment. While structured pruning offers a promising avenue for model compression, existing methods often struggle with the detrimental effects of aggressive, simultaneous width and depth reductions, leading to substantial performance degradation. This paper argues that a critical, often overlooked, aspect in making such aggressive joint pruning viable is the strategic re-initialization and adjustment of remaining weights to improve the model post-pruning training accuracies. We introduce Pangu Light, a framework for LLM acceleration centered around structured pruning coupled with novel weight re-initialization techniques designed to address this ``missing piece''. Our framework systematically targets multiple axes, including model width, depth, attention heads, and RMSNorm, with its effectiveness rooted in novel re-initialization methods like Cross-Layer Attention Pruning (CLAP) and Stabilized LayerNorm Pruning (SLNP) that mitigate performance drops by providing the network a better training starting point. Further enhancing efficiency, Pangu Light incorporates specialized optimizations such as absorbing Post-RMSNorm computations and tailors its strategies to Ascend NPU characteristics. The Pangu Light models consistently exhibit a superior accuracy-efficiency trade-off, outperforming prominent baseline pruning methods like Nemotron and established LLMs like Qwen3 series. For instance, on Ascend NPUs, Pangu Light-32B's 81.6 average score and 2585 tokens/s throughput exceed Qwen3-32B's 80.9 average score and 2225 tokens/s.
Pangu Ultra MoE: How to Train Your Big MoE on Ascend NPUs
May 07, 2025



Sparse large language models (LLMs) with Mixture of Experts (MoE) and close to a trillion parameters are dominating the realm of most capable language models. However, the massive model scale poses significant challenges for the underlying software and hardware systems. In this paper, we aim to uncover a recipe to harness such scale on Ascend NPUs. The key goals are better usage of the computing resources under the dynamic sparse model structures and materializing the expected performance gain on the actual hardware. To select model configurations suitable for Ascend NPUs without repeatedly running the expensive experiments, we leverage simulation to compare the trade-off of various model hyperparameters. This study led to Pangu Ultra MoE, a sparse LLM with 718 billion parameters, and we conducted experiments on the model to verify the simulation results. On the system side, we dig into Expert Parallelism to optimize the communication between NPU devices to reduce the synchronization overhead. We also optimize the memory efficiency within the devices to further reduce the parameter and activation management overhead. In the end, we achieve an MFU of 30.0% when training Pangu Ultra MoE, with performance comparable to that of DeepSeek R1, on 6K Ascend NPUs, and demonstrate that the Ascend system is capable of harnessing all the training stages of the state-of-the-art language models. Extensive experiments indicate that our recipe can lead to efficient training of large-scale sparse language models with MoE. We also study the behaviors of such models for future reference.
Pangu Ultra: Pushing the Limits of Dense Large Language Models on Ascend NPUs
Apr 10, 2025



We present Pangu Ultra, a Large Language Model (LLM) with 135 billion parameters and dense Transformer modules trained on Ascend Neural Processing Units (NPUs). Although the field of LLM has been witnessing unprecedented advances in pushing the scale and capability of LLM in recent years, training such a large-scale model still involves significant optimization and system challenges. To stabilize the training process, we propose depth-scaled sandwich normalization, which effectively eliminates loss spikes during the training process of deep models. We pre-train our model on 13.2 trillion diverse and high-quality tokens and further enhance its reasoning capabilities during post-training. To perform such large-scale training efficiently, we utilize 8,192 Ascend NPUs with a series of system optimizations. Evaluations on multiple diverse benchmarks indicate that Pangu Ultra significantly advances the state-of-the-art capabilities of dense LLMs such as Llama 405B and Mistral Large 2, and even achieves competitive results with DeepSeek-R1, whose sparse model structure contains much more parameters. Our exploration demonstrates that Ascend NPUs are capable of efficiently and effectively training dense models with more than 100 billion parameters. Our model and system will be available for our commercial customers.