 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaliency-driven Dynamic Token Pruning for Large Language Models
Apr 09, 2025
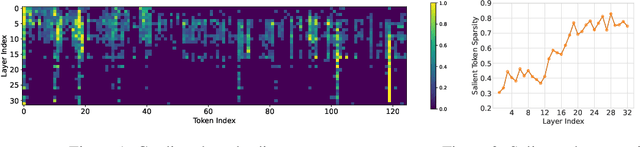
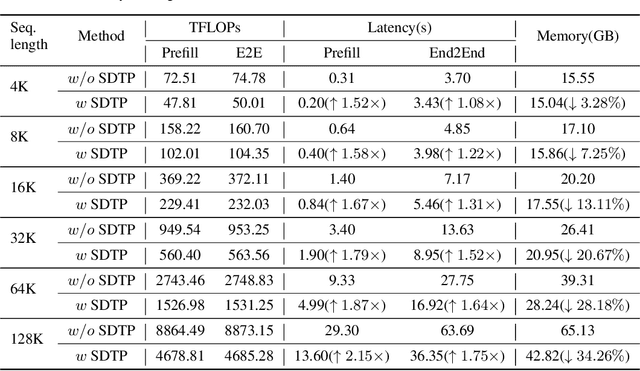
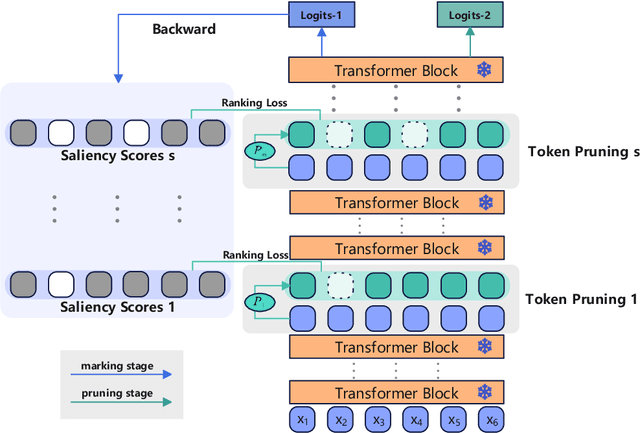
Despite the recent success of large language models (LLMs), LLMs are particularly challenging in long-sequence inference scenarios due to the quadratic computational complexity of the attention mechanism. Inspired by the interpretability theory of feature attribution in neural network models, we observe that not all tokens have the same contribution. Based on this observation, we propose a novel token pruning framework, namely Saliency-driven Dynamic Token Pruning (SDTP), to gradually and dynamically prune redundant tokens based on the input context. Specifically, a lightweight saliency-driven prediction module is designed to estimate the importance score of each token with its hidden state, which is added to different layers of the LLM to hierarchically prune redundant tokens. Furthermore, a ranking-based optimization strategy is proposed to minimize the ranking divergence of the saliency score and the predicted importance score. Extensive experiments have shown that our framework is generalizable to various models and datasets. By hierarchically pruning 65\% of the input tokens, our method greatly reduces 33\% $\sim$ 47\% FLOPs and achieves speedup up to 1.75$\times$ during inference, while maintaining comparable performance. We further demonstrate that SDTP can be combined with KV cache compression method for further compression.