 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC-MOP: Integrating Momentum and Boundary-Aware Clustering for Enhanced Prompt Evolution
Feb 11, 2026Automatic prompt optimization is a promising direction to boost the performance of Large Language Models (LLMs). However, existing methods often suffer from noisy and conflicting update signals. In this research, we propose C-MOP (Cluster-based Momentum Optimized Prompting), a framework that stabilizes optimization via Boundary-Aware Contrastive Sampling (BACS) and Momentum-Guided Semantic Clustering (MGSC). Specifically, BACS utilizes batch-level information to mine tripartite features--Hard Negatives, Anchors, and Boundary Pairs--to precisely characterize the typical representation and decision boundaries of positive and negative prompt samples. To resolve semantic conflicts, MGSC introduces a textual momentum mechanism with temporal decay that distills persistent consensus from fluctuating gradients across iterations. Extensive experiments demonstrate that C-MOP consistently outperforms SOTA baselines like PromptWizard and ProTeGi, yielding average gains of 1.58% and 3.35%. Notably, C-MOP enables a general LLM with 3B activated parameters to surpass a 70B domain-specific dense LLM, highlighting its effectiveness in driving precise prompt evolution. The code is available at https://github.com/huawei-noah/noah-research/tree/master/C-MOP.
Pangu Embedded: An Efficient Dual-system LLM Reasoner with Metacognition
May 29, 2025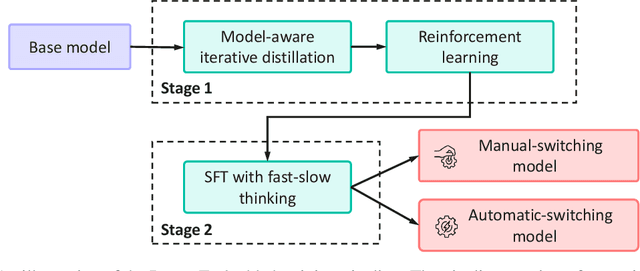

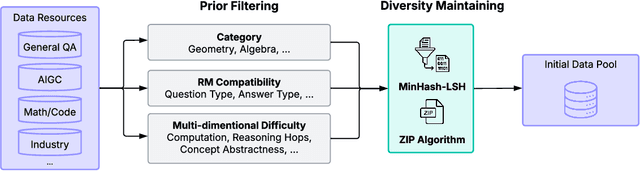
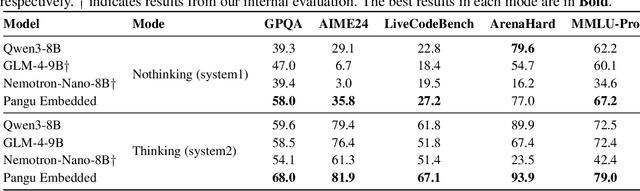
This work presents Pangu Embedded, an efficient Large Language Model (LLM) reasoner developed on Ascend Neural Processing Units (NPUs), featuring flexible fast and slow thinking capabilities. Pangu Embedded addresses the significant computational costs and inference latency challenges prevalent in existing reasoning-optimized LLMs. We propose a two-stage training framework for its construction. In Stage 1, the model is finetuned via an iterative distillation process, incorporating inter-iteration model merging to effectively aggregate complementary knowledge. This is followed by reinforcement learning on Ascend clusters, optimized by a latency-tolerant scheduler that combines stale synchronous parallelism with prioritized data queues. The RL process is guided by a Multi-source Adaptive Reward System (MARS), which generates dynamic, task-specific reward signals using deterministic metrics and lightweight LLM evaluators for mathematics, coding, and general problem-solving tasks. Stage 2 introduces a dual-system framework, endowing Pangu Embedded with a "fast" mode for routine queries and a deeper "slow" mode for complex inference. This framework offers both manual mode switching for user control and an automatic, complexity-aware mode selection mechanism that dynamically allocates computational resources to balance latency and reasoning depth. Experimental results on benchmarks including AIME 2024, GPQA, and LiveCodeBench demonstrate that Pangu Embedded with 7B parameters, outperforms similar-size models like Qwen3-8B and GLM4-9B. It delivers rapid responses and state-of-the-art reasoning quality within a single, unified model architecture, highlighting a promising direction for developing powerful yet practically deployable LLM reasoners.
Saliency-driven Dynamic Token Pruning for Large Language Models
Apr 09, 2025
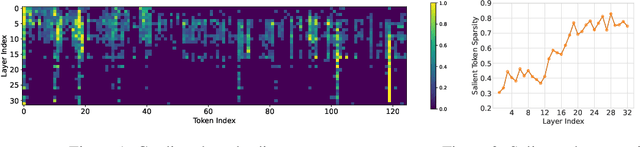
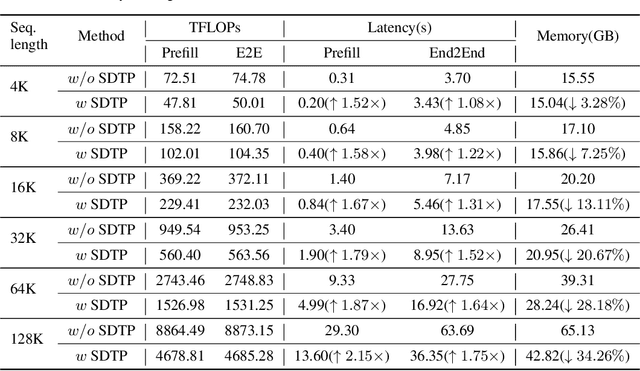
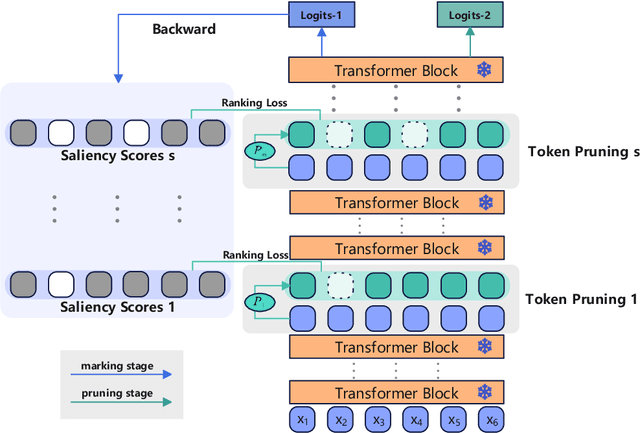
Despite the recent success of large language models (LLMs), LLMs are particularly challenging in long-sequence inference scenarios due to the quadratic computational complexity of the attention mechanism. Inspired by the interpretability theory of feature attribution in neural network models, we observe that not all tokens have the same contribution. Based on this observation, we propose a novel token pruning framework, namely Saliency-driven Dynamic Token Pruning (SDTP), to gradually and dynamically prune redundant tokens based on the input context. Specifically, a lightweight saliency-driven prediction module is designed to estimate the importance score of each token with its hidden state, which is added to different layers of the LLM to hierarchically prune redundant tokens. Furthermore, a ranking-based optimization strategy is proposed to minimize the ranking divergence of the saliency score and the predicted importance score. Extensive experiments have shown that our framework is generalizable to various models and datasets. By hierarchically pruning 65\% of the input tokens, our method greatly reduces 33\% $\sim$ 47\% FLOPs and achieves speedup up to 1.75$\times$ during inference, while maintaining comparable performance. We further demonstrate that SDTP can be combined with KV cache compression method for further compression.
GIM: A Million-scale Benchmark for Generative Image Manipulation Detection and Localization
Jun 24, 2024
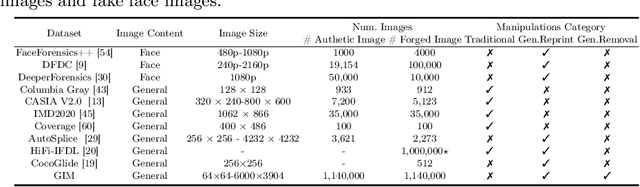
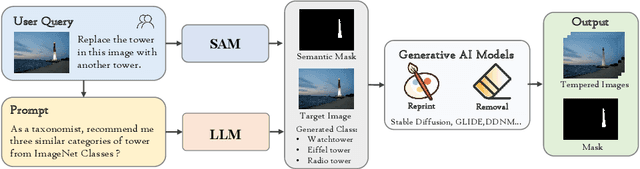
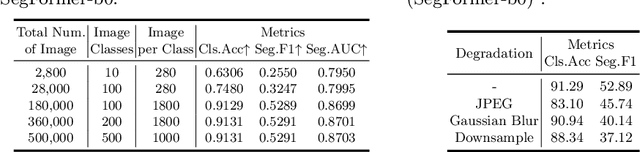
The extraordinary ability of generative models emerges as a new trend in image editing and generating realistic images, posing a serious threat to the trustworthiness of multimedia data and driving the research of image manipulation detection and location(IMDL). However, the lack of a large-scale data foundation makes IMDL task unattainable. In this paper, a local manipulation pipeline is designed, incorporating the powerful SAM, ChatGPT and generative models. Upon this basis, We propose the GIM dataset, which has the following advantages: 1) Large scale, including over one million pairs of AI-manipulated images and real images. 2) Rich Image Content, encompassing a broad range of image classes 3) Diverse Generative Manipulation, manipulated images with state-of-the-art generators and various manipulation tasks. The aforementioned advantages allow for a more comprehensive evaluation of IMDL methods, extending their applicability to diverse images. We introduce two benchmark settings to evaluate the generalization capability and comprehensive performance of baseline methods. In addition, we propose a novel IMDL framework, termed GIMFormer, which consists of a ShadowTracer, Frequency-Spatial Block (FSB), and a Multi-window Anomalous Modelling (MWAM) Module. Extensive experiments on the GIM demonstrate that GIMFormer surpasses previous state-of-the-art works significantly on two different benchmarks.
GenDet: Towards Good Generalizations for AI-Generated Image Detection
Dec 12, 2023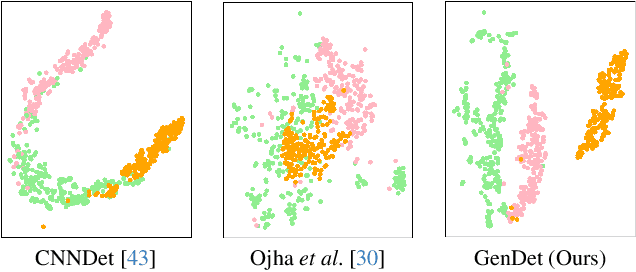

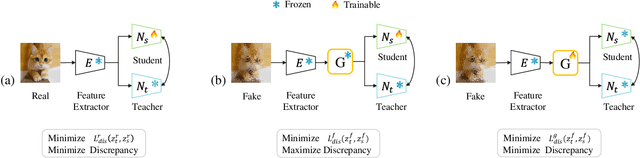

The misuse of AI imagery can have harmful societal effects, prompting the creation of detectors to combat issues like the spread of fake news. Existing methods can effectively detect images generated by seen generators, but it is challenging to detect those generated by unseen generators. They do not concentrate on amplifying the output discrepancy when detectors process real versus fake images. This results in a close output distribution of real and fake samples, increasing classification difficulty in detecting unseen generators. This paper addresses the unseen-generator detection problem by considering this task from the perspective of anomaly detection and proposes an adversarial teacher-student discrepancy-aware framework. Our method encourages smaller output discrepancies between the student and the teacher models for real images while aiming for larger discrepancies for fake images. We employ adversarial learning to train a feature augmenter, which promotes smaller discrepancies between teacher and student networks when the inputs are fake images. Our method has achieved state-of-the-art on public benchmarks, and the visualization results show that a large output discrepancy is maintained when faced with various types of generators.
GenImage: A Million-Scale Benchmark for Detecting AI-Generated Image
Jun 24, 2023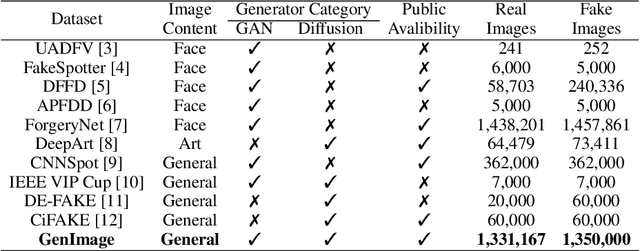

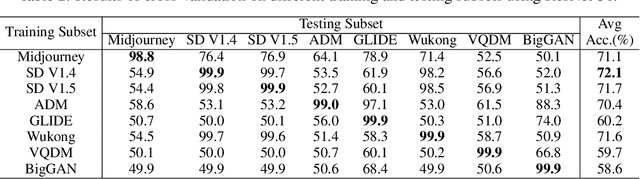
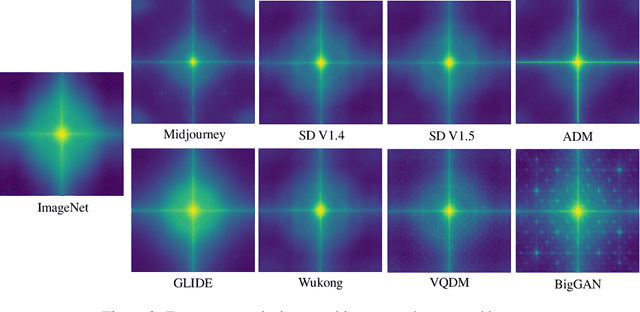
The extraordinary ability of generative models to generate photographic images has intensified concerns about the spread of disinformation, thereby leading to the demand for detectors capable of distinguishing between AI-generated fake images and real images. However, the lack of large datasets containing images from the most advanced image generators poses an obstacle to the development of such detectors. In this paper, we introduce the GenImage dataset, which has the following advantages: 1) Plenty of Images, including over one million pairs of AI-generated fake images and collected real images. 2) Rich Image Content, encompassing a broad range of image classes. 3) State-of-the-art Generators, synthesizing images with advanced diffusion models and GANs. The aforementioned advantages allow the detectors trained on GenImage to undergo a thorough evaluation and demonstrate strong applicability to diverse images. We conduct a comprehensive analysis of the dataset and propose two tasks for evaluating the detection method in resembling real-world scenarios. The cross-generator image classification task measures the performance of a detector trained on one generator when tested on the others. The degraded image classification task assesses the capability of the detectors in handling degraded images such as low-resolution, blurred, and compressed images. With the GenImage dataset, researchers can effectively expedite the development and evaluation of superior AI-generated image detectors in comparison to prevailing methodologies.
Dynamic Resolution Network
Jun 05, 2021
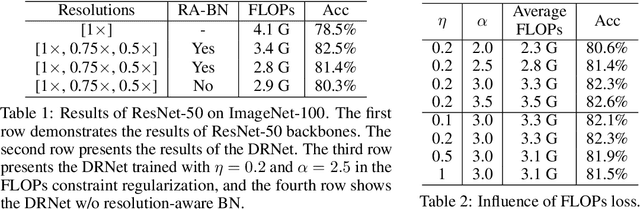
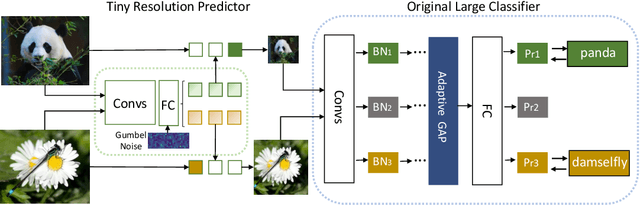
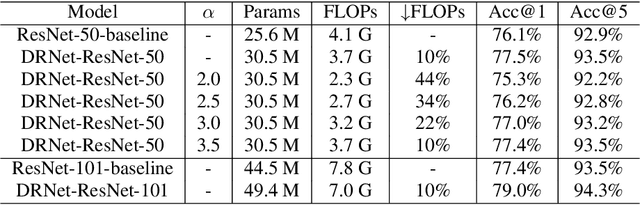
Deep convolutional neural networks (CNNs) are often of sophisticated design with numerous convolutional layers and learnable parameters for the accuracy reason. To alleviate the expensive costs of deploying them on mobile devices, recent works have made huge efforts for excavating redundancy in pre-defined architectures. Nevertheless, the redundancy on the input resolution of modern CNNs has not been fully investigated, i.e., the resolution of input image is fixed. In this paper, we observe that the smallest resolution for accurately predicting the given image is different using the same neural network. To this end, we propose a novel dynamic-resolution network (DRNet) in which the resolution is determined dynamically based on each input sample. Thus, a resolution predictor with negligible computational costs is explored and optimized jointly with the desired network. In practice, the predictor learns the smallest resolution that can retain and even exceed the original recognition accuracy for each image. During the inference, each input image will be resized to its predicted resolution for minimizing the overall computation burden. We then conduct extensive experiments on several benchmark networks and datasets. The results show that our DRNet can be embedded in any off-the-shelf network architecture to obtain a considerable reduction in computational complexity. For instance, DRNet achieves similar performance with an about 34% computation reduction, while gains 1.4% accuracy increase with 10% computation reduction compared to the original ResNet-50 on ImageNet.
Visual Transformer Pruning
Apr 20, 2021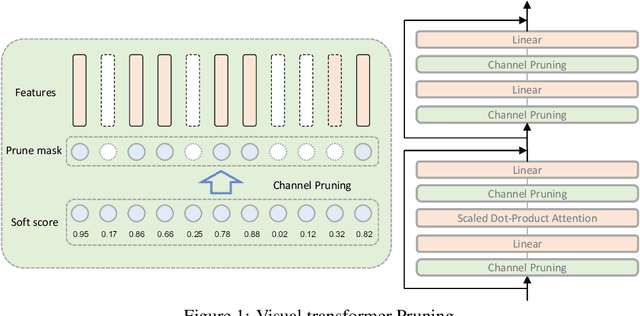
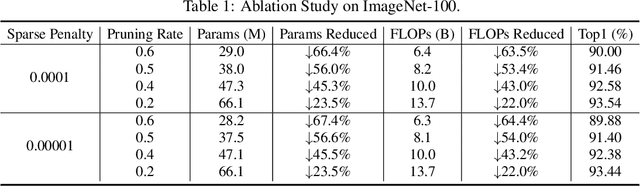
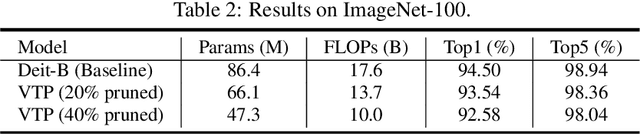
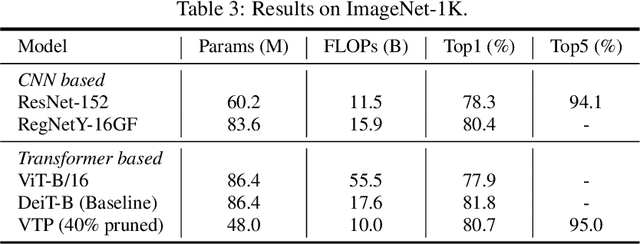
Visual transformer has achieved competitive performance on a variety of computer vision applications. However, their storage, run-time memory, and computational demands are hindering the deployment on mobile devices. Here we present an visual transformer pruning approach, which identifies the impacts of channels in each layer and then executes pruning accordingly. By encouraging channel-wise sparsity in the Transformer, important channels automatically emerge. A great number of channels with small coefficients can be discarded to achieve a high pruning ratio without significantly compromising accuracy. The pipeline for visual transformer pruning is as follows: 1) training with sparsity regularization; 2) pruning channels; 3) finetuning. The reduced parameters and FLOPs ratios of the proposed algorithm are well evaluated and analyzed on ImageNet dataset to demonstrate its effectiveness.
Video Captioning in Compressed Video
Jan 02, 2021
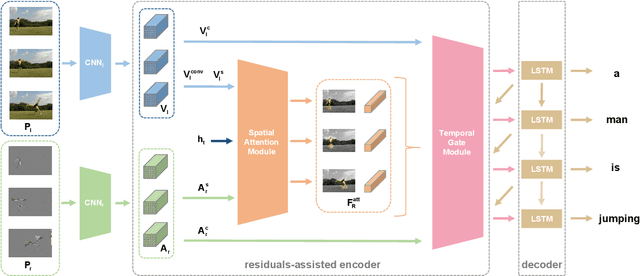
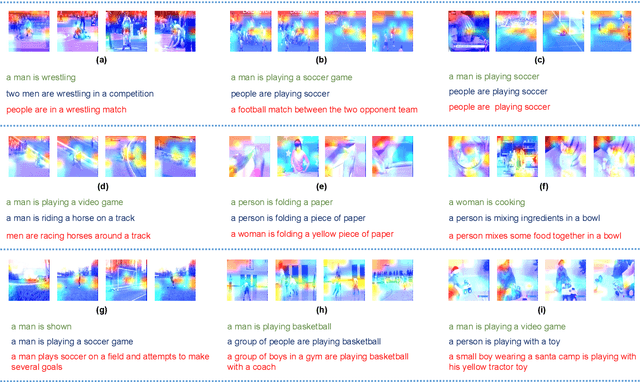

Existing approaches in video captioning concentrate on exploring global frame features in the uncompressed videos, while the free of charge and critical saliency information already encoded in the compressed videos is generally neglected. We propose a video captioning method which operates directly on the stored compressed videos. To learn a discriminative visual representation for video captioning, we design a residuals-assisted encoder (RAE), which spots regions of interest in I-frames under the assistance of the residuals frames. First, we obtain the spatial attention weights by extracting features of residuals as the saliency value of each location in I-frame and design a spatial attention module to refine the attention weights. We further propose a temporal gate module to determine how much the attended features contribute to the caption generation, which enables the model to resist the disturbance of some noisy signals in the compressed videos. Finally, Long Short-Term Memory is utilized to decode the visual representations into descriptions. We evaluate our method on two benchmark datasets and demonstrate the effectiveness of our approach.
Dynamic Feature Pyramid Networks for Object Detection
Dec 01, 2020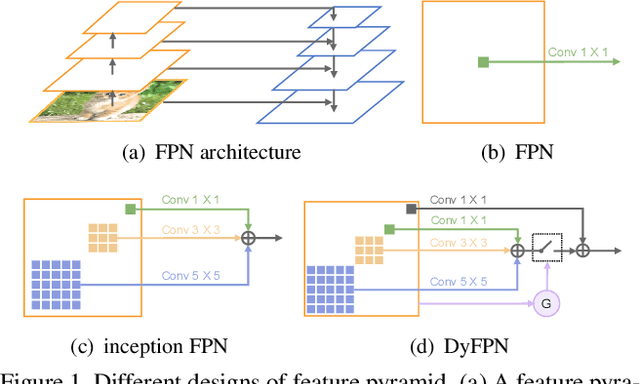
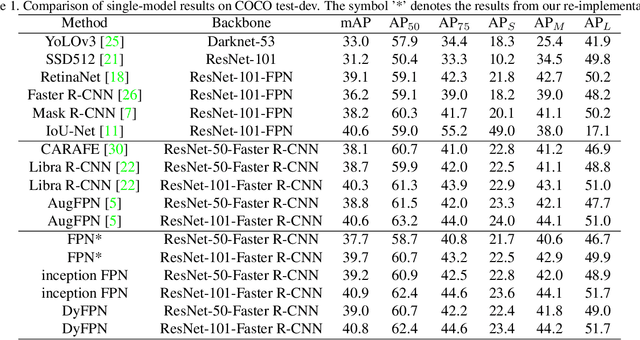
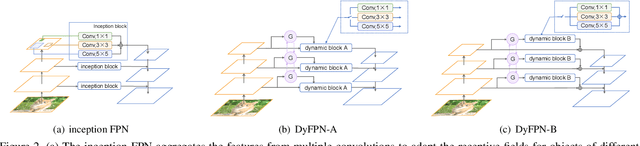
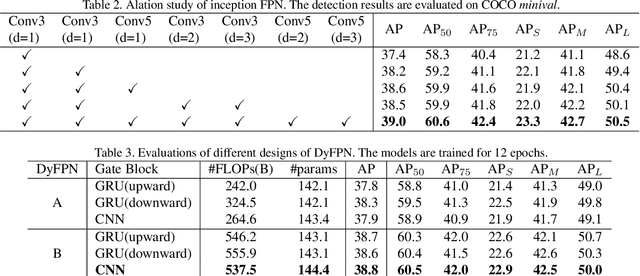
This paper studies feature pyramid network (FPN), which is a widely used module for aggregating multi-scale feature information in the object detection system. The performance gain in most of the existing works is mainly contributed to the increase of computation burden, especially the floating number operations (FLOPs). In addition, the multi-scale information within each layer in FPN has not been well investigated. To this end, we first introduce an inception FPN in which each layer contains convolution filters with different kernel sizes to enlarge the receptive field and integrate more useful information. Moreover, we point out that not all objects need such a complicated calculation module and propose a new dynamic FPN (DyFPN). Each layer in the DyFPN consists of multiple branches with different computational costs. Specifically, the output features of DyFPN will be calculated by using the adaptively selected branch according to a learnable gating operation. Therefore, the proposed method can provide a more efficient dynamic inference for achieving a better trade-off between accuracy and detection performance. Extensive experiments conducted on benchmarks demonstrate that the proposed DyFPN significantly improves performance with the optimal allocation of computation resources. For instance, replacing the FPN with the inception FPN improves detection accuracy by 1.6 AP using the Faster R-CNN paradigm on COCO minival, and the DyFPN further reduces about 40% of its FLOPs while maintaining similar performance.