 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSPO: Direct Semantic Preference Optimization for Real-World Image Super-Resolution
Apr 21, 2025



Recent advances in diffusion models have improved Real-World Image Super-Resolution (Real-ISR), but existing methods lack human feedback integration, risking misalignment with human preference and may leading to artifacts, hallucinations and harmful content generation. To this end, we are the first to introduce human preference alignment into Real-ISR, a technique that has been successfully applied in Large Language Models and Text-to-Image tasks to effectively enhance the alignment of generated outputs with human preferences. Specifically, we introduce Direct Preference Optimization (DPO) into Real-ISR to achieve alignment, where DPO serves as a general alignment technique that directly learns from the human preference dataset. Nevertheless, unlike high-level tasks, the pixel-level reconstruction objectives of Real-ISR are difficult to reconcile with the image-level preferences of DPO, which can lead to the DPO being overly sensitive to local anomalies, leading to reduced generation quality. To resolve this dichotomy, we propose Direct Semantic Preference Optimization (DSPO) to align instance-level human preferences by incorporating semantic guidance, which is through two strategies: (a) semantic instance alignment strategy, implementing instance-level alignment to ensure fine-grained perceptual consistency, and (b) user description feedback strategy, mitigating hallucinations through semantic textual feedback on instance-level images. As a plug-and-play solution, DSPO proves highly effective in both one-step and multi-step SR frameworks.
Dynamic Contrastive Knowledge Distillation for Efficient Image Restoration
Dec 12, 2024



Knowledge distillation (KD) is a valuable yet challenging approach that enhances a compact student network by learning from a high-performance but cumbersome teacher model. However, previous KD methods for image restoration overlook the state of the student during the distillation, adopting a fixed solution space that limits the capability of KD. Additionally, relying solely on L1-type loss struggles to leverage the distribution information of images. In this work, we propose a novel dynamic contrastive knowledge distillation (DCKD) framework for image restoration. Specifically, we introduce dynamic contrastive regularization to perceive the student's learning state and dynamically adjust the distilled solution space using contrastive learning. Additionally, we also propose a distribution mapping module to extract and align the pixel-level category distribution of the teacher and student models. Note that the proposed DCKD is a structure-agnostic distillation framework, which can adapt to different backbones and can be combined with methods that optimize upper-bound constraints to further enhance model performance. Extensive experiments demonstrate that DCKD significantly outperforms the state-of-the-art KD methods across various image restoration tasks and backbones.
Multi-Granularity Semantic Revision for Large Language Model Distillation
Jul 14, 2024



Knowledge distillation plays a key role in compressing the Large Language Models (LLMs), which boosts a small-size student model under large teacher models' guidance. However, existing LLM distillation methods overly rely on student-generated outputs, which may introduce generation errors and misguide the distillation process. Moreover, the distillation loss functions introduced in previous art struggle to align the most informative part due to the complex distribution of LLMs' outputs. To address these problems, we propose a multi-granularity semantic revision method for LLM distillation. At the sequence level, we propose a sequence correction and re-generation (SCRG) strategy. SCRG first calculates the semantic cognitive difference between the teacher and student to detect the error token, then corrects it with the teacher-generated one, and re-generates the sequence to reduce generation errors and enhance generation diversity. At the token level, we design a distribution adaptive clipping Kullback-Leibler (DAC-KL) loss as the distillation objective function. DAC-KL loss exploits a learnable sub-network to adaptively extract semantically dense areas from the teacher's output, avoiding the interference of redundant information in the distillation process. Finally, at the span level, we leverage the span priors of a sequence to compute the probability correlations within spans, and constrain the teacher and student's probability correlations to be consistent, further enhancing the transfer of semantic information. Extensive experiments across different model families with parameters ranging from 0.1B to 13B demonstrate the superiority of our method compared to existing methods.
GIM: A Million-scale Benchmark for Generative Image Manipulation Detection and Localization
Jun 24, 2024
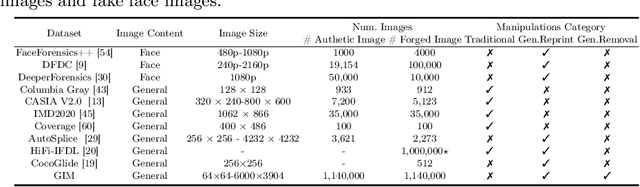
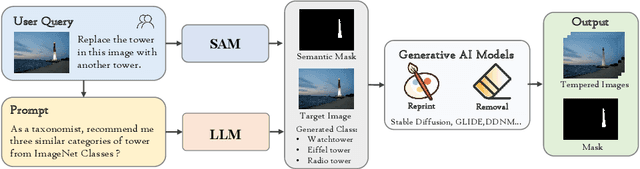
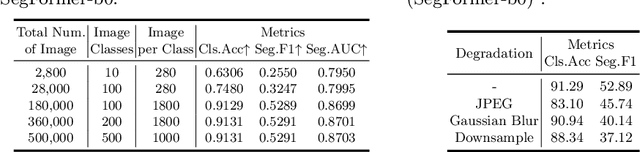
The extraordinary ability of generative models emerges as a new trend in image editing and generating realistic images, posing a serious threat to the trustworthiness of multimedia data and driving the research of image manipulation detection and location(IMDL). However, the lack of a large-scale data foundation makes IMDL task unattainable. In this paper, a local manipulation pipeline is designed, incorporating the powerful SAM, ChatGPT and generative models. Upon this basis, We propose the GIM dataset, which has the following advantages: 1) Large scale, including over one million pairs of AI-manipulated images and real images. 2) Rich Image Content, encompassing a broad range of image classes 3) Diverse Generative Manipulation, manipulated images with state-of-the-art generators and various manipulation tasks. The aforementioned advantages allow for a more comprehensive evaluation of IMDL methods, extending their applicability to diverse images. We introduce two benchmark settings to evaluate the generalization capability and comprehensive performance of baseline methods. In addition, we propose a novel IMDL framework, termed GIMFormer, which consists of a ShadowTracer, Frequency-Spatial Block (FSB), and a Multi-window Anomalous Modelling (MWAM) Module. Extensive experiments on the GIM demonstrate that GIMFormer surpasses previous state-of-the-art works significantly on two different benchmarks.
Knowledge Distillation with Multi-granularity Mixture of Priors for Image Super-Resolution
Apr 03, 2024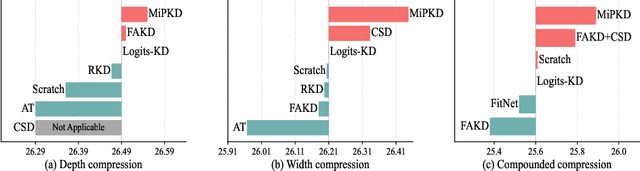
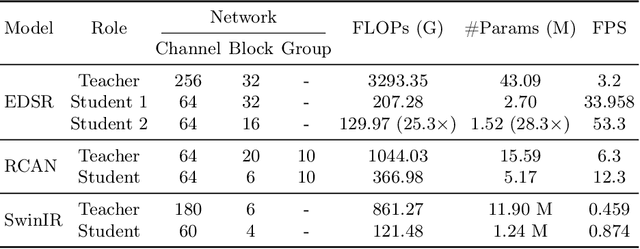
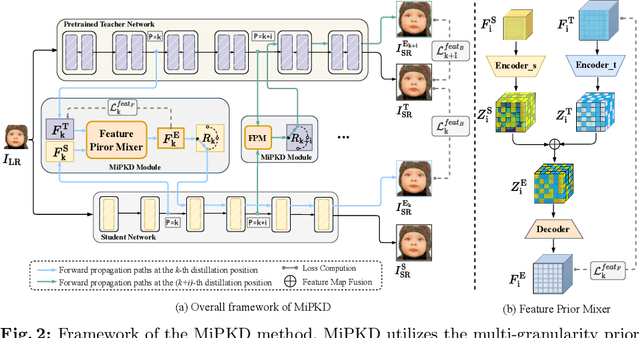
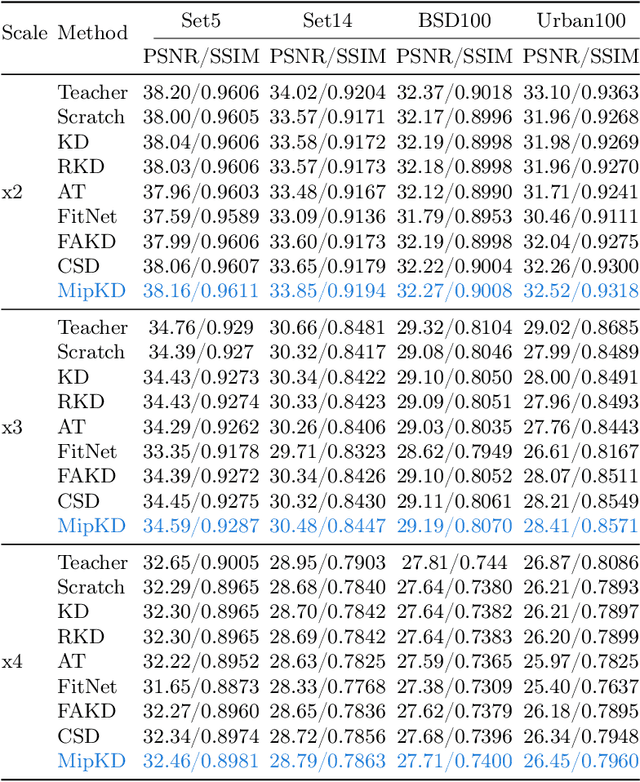
Knowledge distillation (KD) is a promising yet challenging model compression technique that transfers rich learning representations from a well-performing but cumbersome teacher model to a compact student model. Previous methods for image super-resolution (SR) mostly compare the feature maps directly or after standardizing the dimensions with basic algebraic operations (e.g. average, dot-product). However, the intrinsic semantic differences among feature maps are overlooked, which are caused by the disparate expressive capacity between the networks. This work presents MiPKD, a multi-granularity mixture of prior KD framework, to facilitate efficient SR model through the feature mixture in a unified latent space and stochastic network block mixture. Extensive experiments demonstrate the effectiveness of the proposed MiPKD method.
Data Upcycling Knowledge Distillation for Image Super-Resolution
Sep 25, 2023Knowledge distillation (KD) emerges as a challenging yet promising technique for compressing deep learning models, characterized by the transmission of extensive learning representations from proficient and computationally intensive teacher models to compact student models. However, only a handful of studies have endeavored to compress the models for single image super-resolution (SISR) through KD, with their effects on student model enhancement remaining marginal. In this paper, we put forth an approach from the perspective of efficient data utilization, namely, the Data Upcycling Knowledge Distillation (DUKD) which facilitates the student model by the prior knowledge teacher provided via upcycled in-domain data derived from their inputs. This upcycling process is realized through two efficient image zooming operations and invertible data augmentations which introduce the label consistency regularization to the field of KD for SISR and substantially boosts student model's generalization. The DUKD, due to its versatility, can be applied across a broad spectrum of teacher-student architectures. Comprehensive experiments across diverse benchmarks demonstrate that our proposed DUKD method significantly outperforms previous art, exemplified by an increase of up to 0.5dB in PSNR over baselines methods, and a 67% parameters reduced RCAN model's performance remaining on par with that of the RCAN teacher model.