 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAllo{SR}$^2$: Rectifying One-Step Super-Resolution to Stay Real via Allomorphic Generative Flows
Apr 21, 2026Real-world image super-resolution (Real-SR) has been revolutionized by leveraging the powerful generative priors of large-scale diffusion and flow-based models. However, fine-tuning these models on limited LR-HR pairs often precipitates "prior collapse" that the model sacrifices its inherent generative richness to overfit specific training degradations. This issue is further exacerbated in one-step generation, where the absence of multi-step refinement leads to significant trajectory drift and artifact generation. In this paper, we propose Allo{SR}$^2$, a novel framework that rectifies one-step SR trajectories via allomorphic generative flows to maintain high-fidelity generative realism. Specifically, we utilize Signal-to-Noise Ratio (SNR) Guided Trajectory Initialization to establish a physically grounded starting state by aligning the degradation level of LR latent features with the optimal anchoring timestep of the pre-trained flow. To ensure a stable, curvature-free path for one-step inference, we propose Flow-Anchored Trajectory Consistency (FATC), which enforces velocity-level supervision across intermediate states. Furthermore, we develop Allomorphic Trajectory Matching (ATM), a self-adversarial alignment strategy that minimizes the distributional discrepancy between the SR flow and the generative flow in a unified vector field. Extensive experiments on both synthetic and real-world benchmarks demonstrate that Allo{SR}$^2$ achieves state-of-the-art performance in one-step Real-SR, offering a superior balance between restoration fidelity and generative realism while maintaining extreme efficiency.
Interleaving Reasoning for Better Text-to-Image Generation
Sep 09, 2025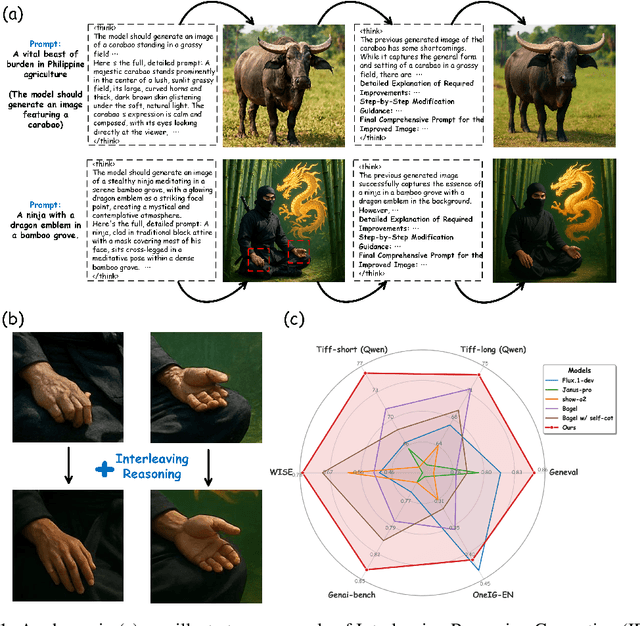
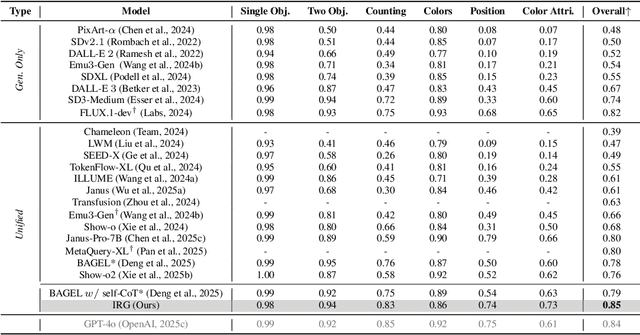

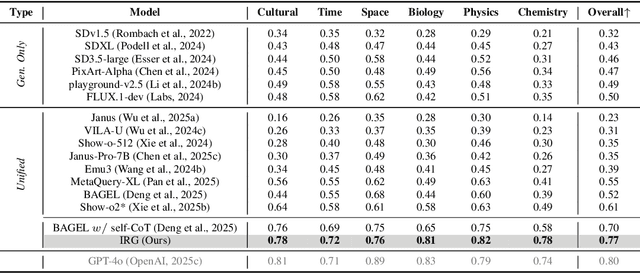
Unified multimodal understanding and generation models recently have achieve significant improvement in image generation capability, yet a large gap remains in instruction following and detail preservation compared to systems that tightly couple comprehension with generation such as GPT-4o. Motivated by recent advances in interleaving reasoning, we explore whether such reasoning can further improve Text-to-Image (T2I) generation. We introduce Interleaving Reasoning Generation (IRG), a framework that alternates between text-based thinking and image synthesis: the model first produces a text-based thinking to guide an initial image, then reflects on the result to refine fine-grained details, visual quality, and aesthetics while preserving semantics. To train IRG effectively, we propose Interleaving Reasoning Generation Learning (IRGL), which targets two sub-goals: (1) strengthening the initial think-and-generate stage to establish core content and base quality, and (2) enabling high-quality textual reflection and faithful implementation of those refinements in a subsequent image. We curate IRGL-300K, a dataset organized into six decomposed learning modes that jointly cover learning text-based thinking, and full thinking-image trajectories. Starting from a unified foundation model that natively emits interleaved text-image outputs, our two-stage training first builds robust thinking and reflection, then efficiently tunes the IRG pipeline in the full thinking-image trajectory data. Extensive experiments show SoTA performance, yielding absolute gains of 5-10 points on GenEval, WISE, TIIF, GenAI-Bench, and OneIG-EN, alongside substantial improvements in visual quality and fine-grained fidelity. The code, model weights and datasets will be released in: https://github.com/Osilly/Interleaving-Reasoning-Generation .
CompBench: Benchmarking Complex Instruction-guided Image Editing
May 18, 2025While real-world applications increasingly demand intricate scene manipulation, existing instruction-guided image editing benchmarks often oversimplify task complexity and lack comprehensive, fine-grained instructions. To bridge this gap, we introduce, a large-scale benchmark specifically designed for complex instruction-guided image editing. CompBench features challenging editing scenarios that incorporate fine-grained instruction following, spatial and contextual reasoning, thereby enabling comprehensive evaluation of image editing models' precise manipulation capabilities. To construct CompBench, We propose an MLLM-human collaborative framework with tailored task pipelines. Furthermore, we propose an instruction decoupling strategy that disentangles editing intents into four key dimensions: location, appearance, dynamics, and objects, ensuring closer alignment between instructions and complex editing requirements. Extensive evaluations reveal that CompBench exposes fundamental limitations of current image editing models and provides critical insights for the development of next-generation instruction-guided image editing systems.
Dynamic Contrastive Knowledge Distillation for Efficient Image Restoration
Dec 12, 2024



Knowledge distillation (KD) is a valuable yet challenging approach that enhances a compact student network by learning from a high-performance but cumbersome teacher model. However, previous KD methods for image restoration overlook the state of the student during the distillation, adopting a fixed solution space that limits the capability of KD. Additionally, relying solely on L1-type loss struggles to leverage the distribution information of images. In this work, we propose a novel dynamic contrastive knowledge distillation (DCKD) framework for image restoration. Specifically, we introduce dynamic contrastive regularization to perceive the student's learning state and dynamically adjust the distilled solution space using contrastive learning. Additionally, we also propose a distribution mapping module to extract and align the pixel-level category distribution of the teacher and student models. Note that the proposed DCKD is a structure-agnostic distillation framework, which can adapt to different backbones and can be combined with methods that optimize upper-bound constraints to further enhance model performance. Extensive experiments demonstrate that DCKD significantly outperforms the state-of-the-art KD methods across various image restoration tasks and backbones.
Hi-Mamba: Hierarchical Mamba for Efficient Image Super-Resolution
Oct 14, 2024



State Space Models (SSM), such as Mamba, have shown strong representation ability in modeling long-range dependency with linear complexity, achieving successful applications from high-level to low-level vision tasks. However, SSM's sequential nature necessitates multiple scans in different directions to compensate for the loss of spatial dependency when unfolding the image into a 1D sequence. This multi-direction scanning strategy significantly increases the computation overhead and is unbearable for high-resolution image processing. To address this problem, we propose a novel Hierarchical Mamba network, namely, Hi-Mamba, for image super-resolution (SR). Hi-Mamba consists of two key designs: (1) The Hierarchical Mamba Block (HMB) assembled by a Local SSM (L-SSM) and a Region SSM (R-SSM) both with the single-direction scanning, aggregates multi-scale representations to enhance the context modeling ability. (2) The Direction Alternation Hierarchical Mamba Group (DA-HMG) allocates the isomeric single-direction scanning into cascading HMBs to enrich the spatial relationship modeling. Extensive experiments demonstrate the superiority of Hi-Mamba across five benchmark datasets for efficient SR. For example, Hi-Mamba achieves a significant PSNR improvement of 0.29 dB on Manga109 for $\times3$ SR, compared to the strong lightweight MambaIR.
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024



This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.
LIPT: Latency-aware Image Processing Transformer
Apr 09, 2024Transformer is leading a trend in the field of image processing. Despite the great success that existing lightweight image processing transformers have achieved, they are tailored to FLOPs or parameters reduction, rather than practical inference acceleration. In this paper, we present a latency-aware image processing transformer, termed LIPT. We devise the low-latency proportion LIPT block that substitutes memory-intensive operators with the combination of self-attention and convolutions to achieve practical speedup. Specifically, we propose a novel non-volatile sparse masking self-attention (NVSM-SA) that utilizes a pre-computing sparse mask to capture contextual information from a larger window with no extra computation overload. Besides, a high-frequency reparameterization module (HRM) is proposed to make LIPT block reparameterization friendly, which improves the model's detail reconstruction capability. Extensive experiments on multiple image processing tasks (e.g., image super-resolution (SR), JPEG artifact reduction, and image denoising) demonstrate the superiority of LIPT on both latency and PSNR. LIPT achieves real-time GPU inference with state-of-the-art performance on multiple image SR benchmarks.
DCS-RISR: Dynamic Channel Splitting for Efficient Real-world Image Super-Resolution
Jan 02, 2023



Real-world image super-resolution (RISR) has received increased focus for improving the quality of SR images under unknown complex degradation. Existing methods rely on the heavy SR models to enhance low-resolution (LR) images of different degradation levels, which significantly restricts their practical deployments on resource-limited devices. In this paper, we propose a novel Dynamic Channel Splitting scheme for efficient Real-world Image Super-Resolution, termed DCS-RISR. Specifically, we first introduce the light degradation prediction network to regress the degradation vector to simulate the real-world degradations, upon which the channel splitting vector is generated as the input for an efficient SR model. Then, a learnable octave convolution block is proposed to adaptively decide the channel splitting scale for low- and high-frequency features at each block, reducing computation overhead and memory cost by offering the large scale to low-frequency features and the small scale to the high ones. To further improve the RISR performance, Non-local regularization is employed to supplement the knowledge of patches from LR and HR subspace with free-computation inference. Extensive experiments demonstrate the effectiveness of DCS-RISR on different benchmark datasets. Our DCS-RISR not only achieves the best trade-off between computation/parameter and PSNR/SSIM metric, and also effectively handles real-world images with different degradation levels.