 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOSA: Motion-Guided Semantic Alignment for Dynamic Scene Graph Generation
Apr 21, 2026Dynamic Scene Graph Generation (DSGG) aims to structurally model objects and their dynamic interactions in video sequences for high-level semantic understanding. However, existing methods struggle with fine-grained relationship modeling, semantic representation utilization, and the ability to model tail relationships. To address these issues, this paper proposes a motion-guided semantic alignment method for DSGG (MoSA). First, a Motion Feature Extractor (MFE) encodes object-pair motion attributes such as distance, velocity, motion persistence, and directional consistency. Then, these motion attributes are fused with spatial relationship features through the Motion-guided Interaction Module (MIM) to generate motion-aware relationship representations. To further enhance semantic discrimination capabilities, the cross-modal Action Semantic Matching (ASM) mechanism aligns visual relationship features with text embeddings of relationship categories. Finally, a category-weighted loss strategy is introduced to emphasize learning of tail relationships. Extensive and rigorous testing shows that MoSA performs optimally on the Action Genome dataset.
ReactDance: Progressive-Granular Representation for Long-Term Coherent Reactive Dance Generation
May 08, 2025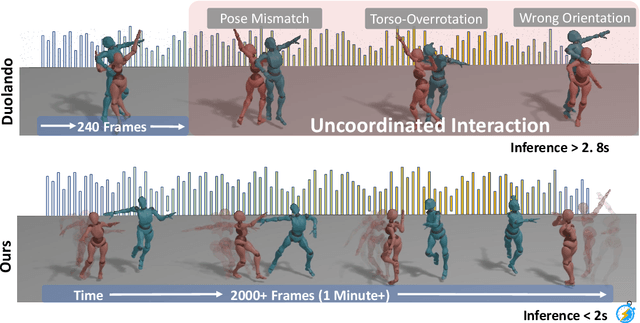
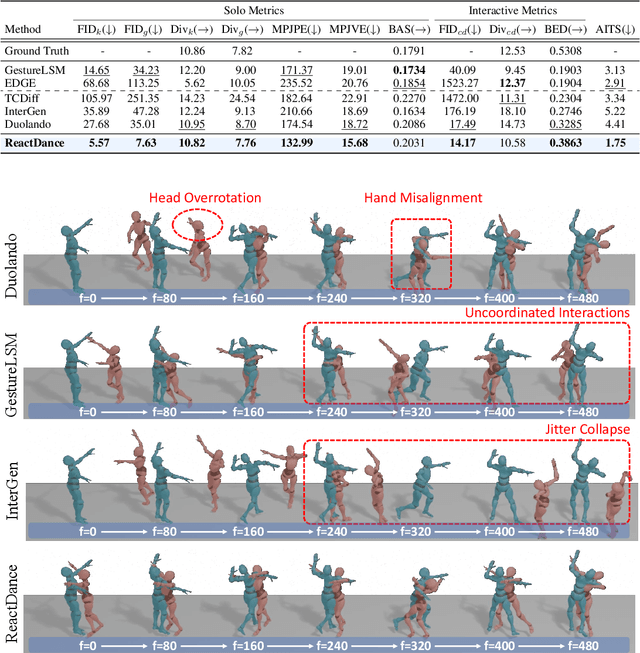
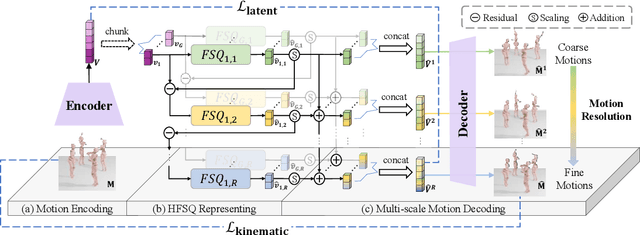
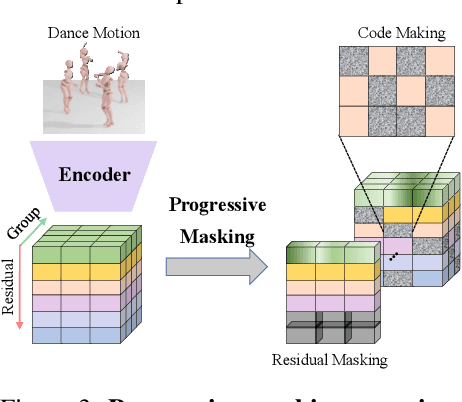
Reactive dance generation (RDG) produces follower movements conditioned on guiding dancer and music while ensuring spatial coordination and temporal coherence. However, existing methods overemphasize global constraints and optimization, overlooking local information, such as fine-grained spatial interactions and localized temporal context. Therefore, we present ReactDance, a novel diffusion-based framework for high-fidelity RDG with long-term coherence and multi-scale controllability. Unlike existing methods that struggle with interaction fidelity, synchronization, and temporal consistency in duet synthesis, our approach introduces two key innovations: 1)Group Residual Finite Scalar Quantization (GRFSQ), a multi-scale disentangled motion representation that captures interaction semantics from coarse body rhythms to fine-grained joint dynamics, and 2)Blockwise Local Context (BLC), a sampling strategy eliminating error accumulation in long sequence generation via local block causal masking and periodic positional encoding. Built on the decoupled multi-scale GRFSQ representation, we implement a diffusion model withLayer-Decoupled Classifier-free Guidance (LDCFG), allowing granular control over motion semantics across scales. Extensive experiments on standard benchmarks demonstrate that ReactDance surpasses existing methods, achieving state-of-the-art performance.
FIND: Fine-tuning Initial Noise Distribution with Policy Optimization for Diffusion Models
Jul 28, 2024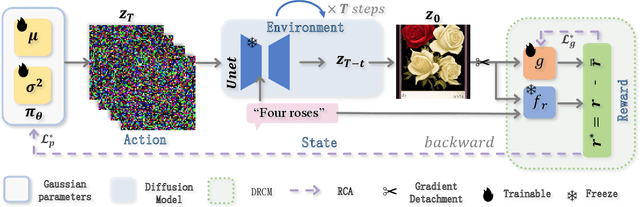
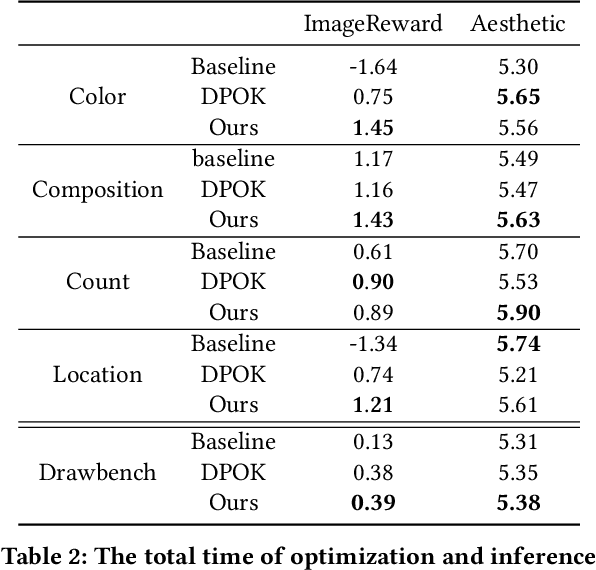
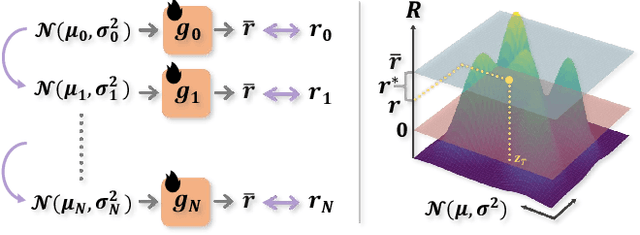
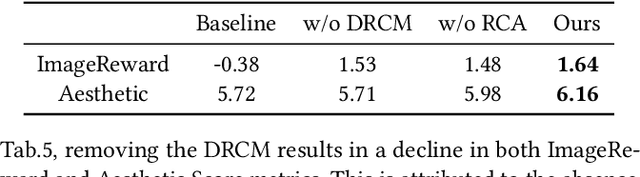
In recent years, large-scale pre-trained diffusion models have demonstrated their outstanding capabilities in image and video generation tasks. However, existing models tend to produce visual objects commonly found in the training dataset, which diverges from user input prompts. The underlying reason behind the inaccurate generated results lies in the model's difficulty in sampling from specific intervals of the initial noise distribution corresponding to the prompt. Moreover, it is challenging to directly optimize the initial distribution, given that the diffusion process involves multiple denoising steps. In this paper, we introduce a Fine-tuning Initial Noise Distribution (FIND) framework with policy optimization, which unleashes the powerful potential of pre-trained diffusion networks by directly optimizing the initial distribution to align the generated contents with user-input prompts. To this end, we first reformulate the diffusion denoising procedure as a one-step Markov decision process and employ policy optimization to directly optimize the initial distribution. In addition, a dynamic reward calibration module is proposed to ensure training stability during optimization. Furthermore, we introduce a ratio clipping algorithm to utilize historical data for network training and prevent the optimized distribution from deviating too far from the original policy to restrain excessive optimization magnitudes. Extensive experiments demonstrate the effectiveness of our method in both text-to-image and text-to-video tasks, surpassing SOTA methods in achieving consistency between prompts and the generated content. Our method achieves 10 times faster than the SOTA approach. Our homepage is available at \url{https://github.com/vpx-ecnu/FIND-website}.
A General and Efficient Training for Transformer via Token Expansion
Mar 31, 2024



The remarkable performance of Vision Transformers (ViTs) typically requires an extremely large training cost. Existing methods have attempted to accelerate the training of ViTs, yet typically disregard method universality with accuracy dropping. Meanwhile, they break the training consistency of the original transformers, including the consistency of hyper-parameters, architecture, and strategy, which prevents them from being widely applied to different Transformer networks. In this paper, we propose a novel token growth scheme Token Expansion (termed ToE) to achieve consistent training acceleration for ViTs. We introduce an "initialization-expansion-merging" pipeline to maintain the integrity of the intermediate feature distribution of original transformers, preventing the loss of crucial learnable information in the training process. ToE can not only be seamlessly integrated into the training and fine-tuning process of transformers (e.g., DeiT and LV-ViT), but also effective for efficient training frameworks (e.g., EfficientTrain), without twisting the original training hyper-parameters, architecture, and introducing additional training strategies. Extensive experiments demonstrate that ToE achieves about 1.3x faster for the training of ViTs in a lossless manner, or even with performance gains over the full-token training baselines. Code is available at https://github.com/Osilly/TokenExpansion .
Motion-Zero: Zero-Shot Moving Object Control Framework for Diffusion-Based Video Generation
Jan 22, 2024Recent large-scale pre-trained diffusion models have demonstrated a powerful generative ability to produce high-quality videos from detailed text descriptions. However, exerting control over the motion of objects in videos generated by any video diffusion model is a challenging problem. In this paper, we propose a novel zero-shot moving object trajectory control framework, Motion-Zero, to enable a bounding-box-trajectories-controlled text-to-video diffusion model. To this end, an initial noise prior module is designed to provide a position-based prior to improve the stability of the appearance of the moving object and the accuracy of position. In addition, based on the attention map of the U-net, spatial constraints are directly applied to the denoising process of diffusion models, which further ensures the positional and spatial consistency of moving objects during the inference. Furthermore, temporal consistency is guaranteed with a proposed shift temporal attention mechanism. Our method can be flexibly applied to various state-of-the-art video diffusion models without any training process. Extensive experiments demonstrate our proposed method can control the motion trajectories of objects and generate high-quality videos.
SPD-DDPM: Denoising Diffusion Probabilistic Models in the Symmetric Positive Definite Space
Dec 13, 2023Symmetric positive definite~(SPD) matrices have shown important value and applications in statistics and machine learning, such as FMRI analysis and traffic prediction. Previous works on SPD matrices mostly focus on discriminative models, where predictions are made directly on $E(X|y)$, where $y$ is a vector and $X$ is an SPD matrix. However, these methods are challenging to handle for large-scale data, as they need to access and process the whole data. In this paper, inspired by denoising diffusion probabilistic model~(DDPM), we propose a novel generative model, termed SPD-DDPM, by introducing Gaussian distribution in the SPD space to estimate $E(X|y)$. Moreover, our model is able to estimate $p(X)$ unconditionally and flexibly without giving $y$. On the one hand, the model conditionally learns $p(X|y)$ and utilizes the mean of samples to obtain $E(X|y)$ as a prediction. On the other hand, the model unconditionally learns the probability distribution of the data $p(X)$ and generates samples that conform to this distribution. Furthermore, we propose a new SPD net which is much deeper than the previous networks and allows for the inclusion of conditional factors. Experiment results on toy data and real taxi data demonstrate that our models effectively fit the data distribution both unconditionally and unconditionally and provide accurate predictions.
DCS-RISR: Dynamic Channel Splitting for Efficient Real-world Image Super-Resolution
Jan 02, 2023



Real-world image super-resolution (RISR) has received increased focus for improving the quality of SR images under unknown complex degradation. Existing methods rely on the heavy SR models to enhance low-resolution (LR) images of different degradation levels, which significantly restricts their practical deployments on resource-limited devices. In this paper, we propose a novel Dynamic Channel Splitting scheme for efficient Real-world Image Super-Resolution, termed DCS-RISR. Specifically, we first introduce the light degradation prediction network to regress the degradation vector to simulate the real-world degradations, upon which the channel splitting vector is generated as the input for an efficient SR model. Then, a learnable octave convolution block is proposed to adaptively decide the channel splitting scale for low- and high-frequency features at each block, reducing computation overhead and memory cost by offering the large scale to low-frequency features and the small scale to the high ones. To further improve the RISR performance, Non-local regularization is employed to supplement the knowledge of patches from LR and HR subspace with free-computation inference. Extensive experiments demonstrate the effectiveness of DCS-RISR on different benchmark datasets. Our DCS-RISR not only achieves the best trade-off between computation/parameter and PSNR/SSIM metric, and also effectively handles real-world images with different degradation levels.
Dynamic Region Division for Adaptive Learning Pedestrian Counting
Aug 12, 2019

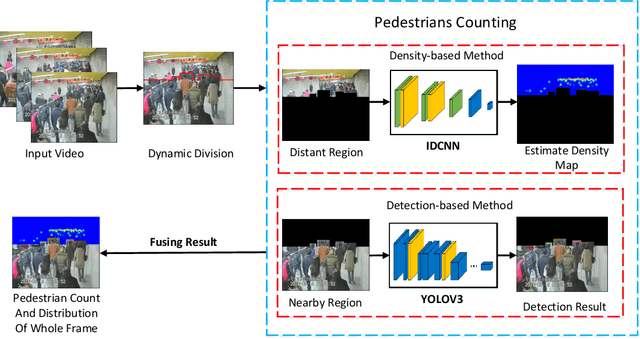

Accurate pedestrian counting algorithm is critical to eliminate insecurity in the congested public scenes. However, counting pedestrians in crowded scenes often suffer from severe perspective distortion. In this paper, basing on the straight-line double region pedestrian counting method, we propose a dynamic region division algorithm to keep the completeness of counting objects. Utilizing the object bounding boxes obtained by YoloV3 and expectation division line of the scene, the boundary for nearby region and distant one is generated under the premise of retaining whole head. Ulteriorly, appropriate learning models are applied to count pedestrians in each obtained region. In the distant region, a novel inception dilated convolutional neural network is proposed to solve the problem of choosing dilation rate. In the nearby region, YoloV3 is used for detecting the pedestrian in multi-scale. Accordingly, the total number of pedestrians in each frame is obtained by fusing the result in nearby and distant regions. A typical subway pedestrian video dataset is chosen to conduct experiment in this paper. The result demonstrate that proposed algorithm is superior to existing machine learning based methods in general performance.