 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIND: Fine-tuning Initial Noise Distribution with Policy Optimization for Diffusion Models
Jul 28, 2024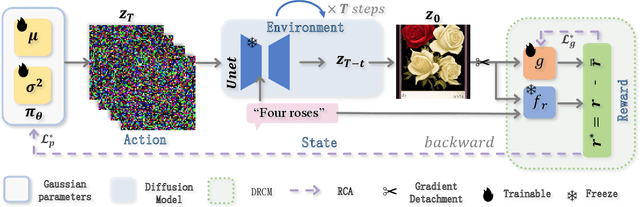
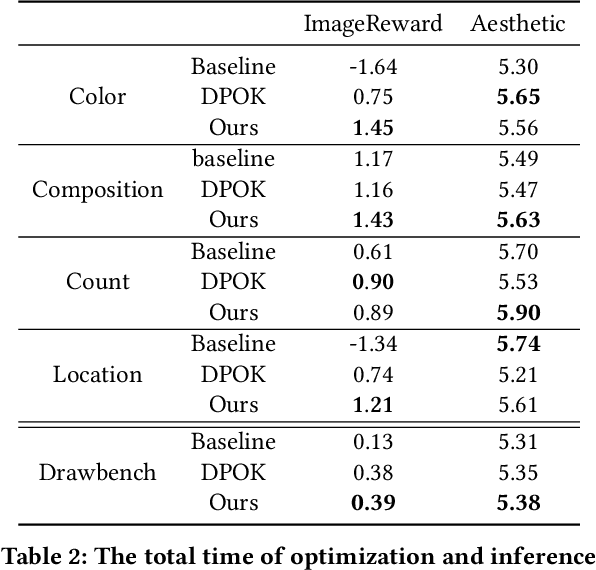
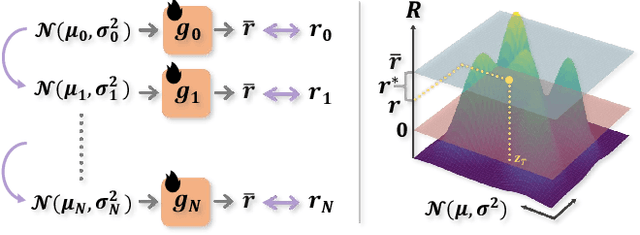
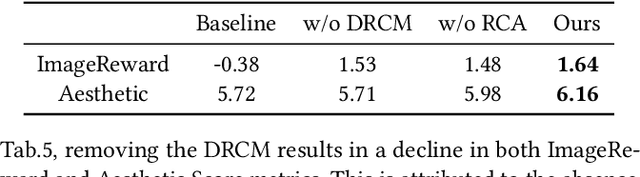
In recent years, large-scale pre-trained diffusion models have demonstrated their outstanding capabilities in image and video generation tasks. However, existing models tend to produce visual objects commonly found in the training dataset, which diverges from user input prompts. The underlying reason behind the inaccurate generated results lies in the model's difficulty in sampling from specific intervals of the initial noise distribution corresponding to the prompt. Moreover, it is challenging to directly optimize the initial distribution, given that the diffusion process involves multiple denoising steps. In this paper, we introduce a Fine-tuning Initial Noise Distribution (FIND) framework with policy optimization, which unleashes the powerful potential of pre-trained diffusion networks by directly optimizing the initial distribution to align the generated contents with user-input prompts. To this end, we first reformulate the diffusion denoising procedure as a one-step Markov decision process and employ policy optimization to directly optimize the initial distribution. In addition, a dynamic reward calibration module is proposed to ensure training stability during optimization. Furthermore, we introduce a ratio clipping algorithm to utilize historical data for network training and prevent the optimized distribution from deviating too far from the original policy to restrain excessive optimization magnitudes. Extensive experiments demonstrate the effectiveness of our method in both text-to-image and text-to-video tasks, surpassing SOTA methods in achieving consistency between prompts and the generated content. Our method achieves 10 times faster than the SOTA approach. Our homepage is available at \url{https://github.com/vpx-ecnu/FIND-website}.