 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReactDance: Progressive-Granular Representation for Long-Term Coherent Reactive Dance Generation
May 08, 2025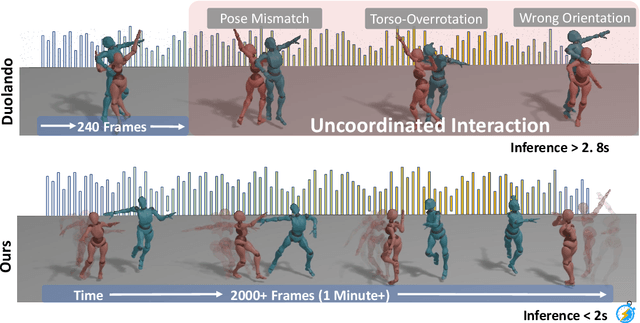
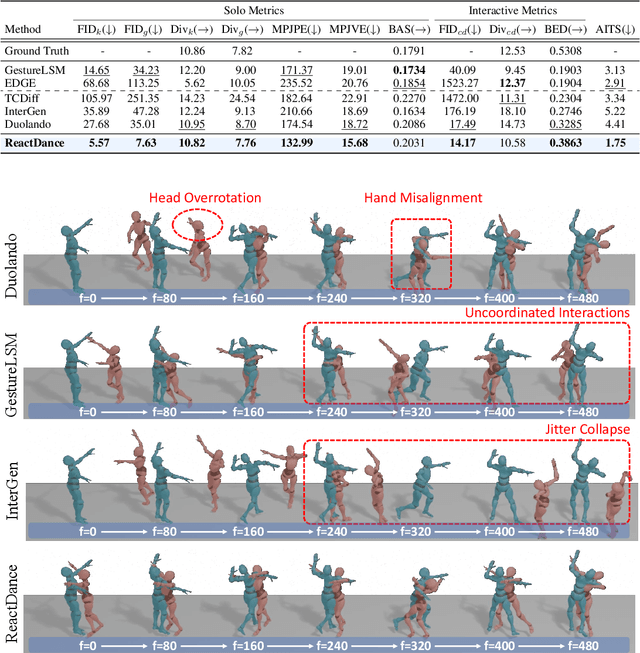
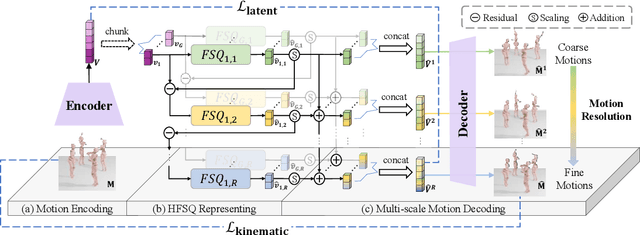
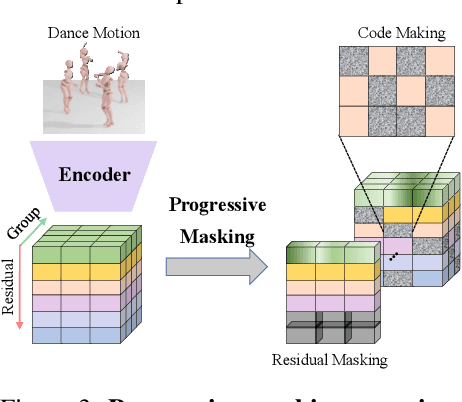
Reactive dance generation (RDG) produces follower movements conditioned on guiding dancer and music while ensuring spatial coordination and temporal coherence. However, existing methods overemphasize global constraints and optimization, overlooking local information, such as fine-grained spatial interactions and localized temporal context. Therefore, we present ReactDance, a novel diffusion-based framework for high-fidelity RDG with long-term coherence and multi-scale controllability. Unlike existing methods that struggle with interaction fidelity, synchronization, and temporal consistency in duet synthesis, our approach introduces two key innovations: 1)Group Residual Finite Scalar Quantization (GRFSQ), a multi-scale disentangled motion representation that captures interaction semantics from coarse body rhythms to fine-grained joint dynamics, and 2)Blockwise Local Context (BLC), a sampling strategy eliminating error accumulation in long sequence generation via local block causal masking and periodic positional encoding. Built on the decoupled multi-scale GRFSQ representation, we implement a diffusion model withLayer-Decoupled Classifier-free Guidance (LDCFG), allowing granular control over motion semantics across scales. Extensive experiments on standard benchmarks demonstrate that ReactDance surpasses existing methods, achieving state-of-the-art performance.
Dynamic-LLaVA: Efficient Multimodal Large Language Models via Dynamic Vision-language Context Sparsification
Dec 03, 2024



Multimodal Large Language Models (MLLMs) have achieved remarkable success in vision understanding, reasoning, and interaction. However, the inference computation and memory increase progressively with the generation of output tokens during decoding, directly affecting the efficacy of MLLMs. Existing methods attempt to reduce the vision context redundancy to achieve efficient MLLMs. Unfortunately, the efficiency benefits of the vision context reduction in the prefill stage gradually diminish during the decoding stage. To address this problem, we proposed a dynamic vision-language context sparsification framework Dynamic-LLaVA, which dynamically reduces the redundancy of vision context in the prefill stage and decreases the memory and computation overhead of the generated language context during decoding. Dynamic-LLaVA designs a tailored sparsification inference scheme for different inference modes, i.e., prefill, decoding with and without KV cache, to achieve efficient inference of MLLMs. In practice, Dynamic-LLaVA can reduce computation consumption by $\sim$75\% in the prefill stage. Meanwhile, throughout the entire generation process of MLLMs, Dynamic-LLaVA reduces the $\sim$50\% computation consumption under decoding without KV cache, while saving $\sim$50\% GPU memory overhead when decoding with KV cache, due to the vision-language context sparsification. Extensive experiments also demonstrate that Dynamic-LLaVA achieves efficient inference for MLLMs with negligible understanding and generation ability degradation or even performance gains compared to the full-context inference baselines. Code is available at https://github.com/Osilly/dynamic_llava .