 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowd Video Captioning
Paper and Code
Nov 13, 2019
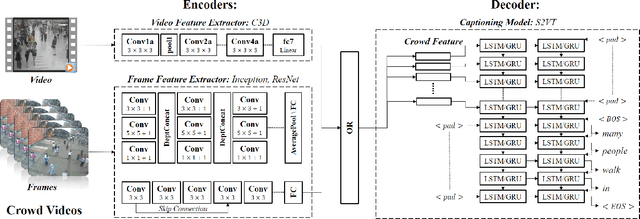

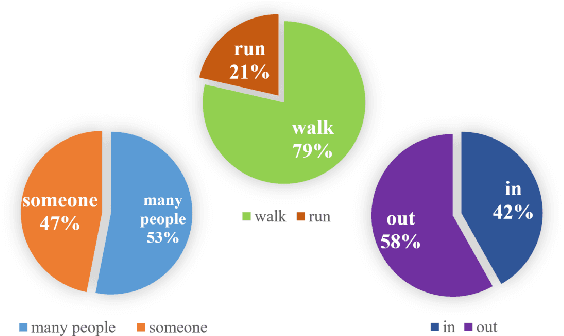
Describing a video automatically with natural language is a challenging task in the area of computer vision. In most cases, the on-site situation of great events is reported in news, but the situation of the off-site spectators in the entrance and exit is neglected which also arouses people's interest. Since the deployment of reporters in the entrance and exit costs lots of manpower, how to automatically describe the behavior of a crowd of off-site spectators is significant and remains a problem. To tackle this problem, we propose a new task called crowd video captioning (CVC) which aims to describe the crowd of spectators. We also provide baseline methods for this task and evaluate them on the dataset WorldExpo'10. Our experimental results show that captioning models have a fairly deep understanding of the crowd in video and perform satisfactorily in the CVC task.