 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Lossless Ultimate Vision Token Compression for VLMs
Dec 09, 2025Visual language models encounter challenges in computational efficiency and latency, primarily due to the substantial redundancy in the token representations of high-resolution images and videos. Current attention/similarity-based compression algorithms suffer from either position bias or class imbalance, leading to significant accuracy degradation. They also fail to generalize to shallow LLM layers, which exhibit weaker cross-modal interactions. To address this, we extend token compression to the visual encoder through an effective iterative merging scheme that is orthogonal in spatial axes to accelerate the computation across the entire VLM. Furthermoer, we integrate a spectrum pruning unit into LLM through an attention/similarity-free low-pass filter, which gradually prunes redundant visual tokens and is fully compatible to modern FlashAttention. On this basis, we propose Lossless Ultimate Vision tokens Compression (LUVC) framework. LUVC systematically compresses visual tokens until complete elimination at the final layer of LLM, so that the high-dimensional visual features are gradually fused into the multimodal queries. The experiments show that LUVC achieves a 2 speedup inference in language model with negligible accuracy degradation, and the training-free characteristic enables immediate deployment across multiple VLMs.
Positional Preservation Embedding for Multimodal Large Language Models
Oct 27, 2025Multimodal large language models (MLLMs) have achieved strong performance on vision-language tasks, yet often suffer from inefficiencies due to redundant visual tokens. Existing token merging methods reduce sequence length but frequently disrupt spatial layouts and temporal continuity by disregarding positional relationships. In this work, we propose a novel encoding operator dubbed as \textbf{P}ositional \textbf{P}reservation \textbf{E}mbedding (\textbf{PPE}), which has the main hallmark of preservation of spatiotemporal structure during visual token compression. PPE explicitly introduces the disentangled encoding of 3D positions in the token dimension, enabling each compressed token to encapsulate different positions from multiple original tokens. Furthermore, we show that PPE can effectively support cascade clustering -- a progressive token compression strategy that leads to better performance retention. PPE is a parameter-free and generic operator that can be seamlessly integrated into existing token merging methods without any adjustments. Applied to state-of-the-art token merging framework, PPE achieves consistent improvements of $2\%\sim5\%$ across multiple vision-language benchmarks, including MMBench (general vision understanding), TextVQA (layout understanding) and VideoMME (temporal understanding). These results demonstrate that preserving positional cues is critical for efficient and effective MLLM reasoning.
GenVidBench: A Challenging Benchmark for Detecting AI-Generated Video
Jan 20, 2025



The rapid advancement of video generation models has made it increasingly challenging to distinguish AI-generated videos from real ones. This issue underscores the urgent need for effective AI-generated video detectors to prevent the dissemination of false information through such videos. However, the development of high-performance generative video detectors is currently impeded by the lack of large-scale, high-quality datasets specifically designed for generative video detection. To this end, we introduce GenVidBench, a challenging AI-generated video detection dataset with several key advantages: 1) Cross Source and Cross Generator: The cross-generation source mitigates the interference of video content on the detection. The cross-generator ensures diversity in video attributes between the training and test sets, preventing them from being overly similar. 2) State-of-the-Art Video Generators: The dataset includes videos from 8 state-of-the-art AI video generators, ensuring that it covers the latest advancements in the field of video generation. 3) Rich Semantics: The videos in GenVidBench are analyzed from multiple dimensions and classified into various semantic categories based on their content. This classification ensures that the dataset is not only large but also diverse, aiding in the development of more generalized and effective detection models. We conduct a comprehensive evaluation of different advanced video generators and present a challenging setting. Additionally, we present rich experimental results including advanced video classification models as baselines. With the GenVidBench, researchers can efficiently develop and evaluate AI-generated video detection models. Datasets and code are available at https://genvidbench.github.io.
GenDet: Towards Good Generalizations for AI-Generated Image Detection
Dec 12, 2023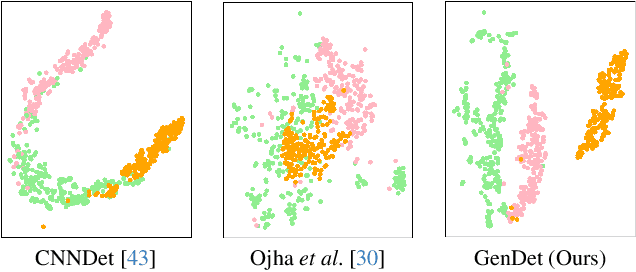

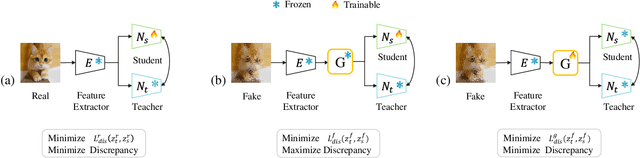

The misuse of AI imagery can have harmful societal effects, prompting the creation of detectors to combat issues like the spread of fake news. Existing methods can effectively detect images generated by seen generators, but it is challenging to detect those generated by unseen generators. They do not concentrate on amplifying the output discrepancy when detectors process real versus fake images. This results in a close output distribution of real and fake samples, increasing classification difficulty in detecting unseen generators. This paper addresses the unseen-generator detection problem by considering this task from the perspective of anomaly detection and proposes an adversarial teacher-student discrepancy-aware framework. Our method encourages smaller output discrepancies between the student and the teacher models for real images while aiming for larger discrepancies for fake images. We employ adversarial learning to train a feature augmenter, which promotes smaller discrepancies between teacher and student networks when the inputs are fake images. Our method has achieved state-of-the-art on public benchmarks, and the visualization results show that a large output discrepancy is maintained when faced with various types of generators.
Distributional Estimation of Data Uncertainty for Surveillance Face Anti-spoofing
Sep 18, 2023



Face recognition systems have become increasingly vulnerable to security threats in recent years, prompting the use of Face Anti-spoofing (FAS) to protect against various types of attacks, such as phone unlocking, face payment, and self-service security inspection. While FAS has demonstrated its effectiveness in traditional settings, securing it in long-distance surveillance scenarios presents a significant challenge. These scenarios often feature low-quality face images, necessitating the modeling of data uncertainty to improve stability under extreme conditions. To address this issue, this work proposes Distributional Estimation (DisE), a method that converts traditional FAS point estimation to distributional estimation by modeling data uncertainty during training, including feature (mean) and uncertainty (variance). By adjusting the learning strength of clean and noisy samples for stability and accuracy, the learned uncertainty enhances DisE's performance. The method is evaluated on SuHiFiMask [1], a large-scale and challenging FAS dataset in surveillance scenarios. Results demonstrate that DisE achieves comparable performance on both ACER and AUC metrics.
Uncertainty-Estimation with Normalized Logits for Out-of-Distribution Detection
Feb 15, 2023Out-of-distribution (OOD) detection is critical for preventing deep learning models from making incorrect predictions to ensure the safety of artificial intelligence systems. Especially in safety-critical applications such as medical diagnosis and autonomous driving, the cost of incorrect decisions is usually unbearable. However, neural networks often suffer from the overconfidence issue, making high confidence for OOD data which are never seen during training process and may be irrelevant to training data, namely in-distribution (ID) data. Determining the reliability of the prediction is still a difficult and challenging task. In this work, we propose Uncertainty-Estimation with Normalized Logits (UE-NL), a robust learning method for OOD detection, which has three main benefits. (1) Neural networks with UE-NL treat every ID sample equally by predicting the uncertainty score of input data and the uncertainty is added into softmax function to adjust the learning strength of easy and hard samples during training phase, making the model learn robustly and accurately. (2) UE-NL enforces a constant vector norm on the logits to decouple the effect of the increasing output norm from optimization process, which causes the overconfidence issue to some extent. (3) UE-NL provides a new metric, the magnitude of uncertainty score, to detect OOD data. Experiments demonstrate that UE-NL achieves top performance on common OOD benchmarks and is more robust to noisy ID data that may be misjudged as OOD data by other methods.
Improving Training and Inference of Face Recognition Models via Random Temperature Scaling
Dec 02, 2022Data uncertainty is commonly observed in the images for face recognition (FR). However, deep learning algorithms often make predictions with high confidence even for uncertain or irrelevant inputs. Intuitively, FR algorithms can benefit from both the estimation of uncertainty and the detection of out-of-distribution (OOD) samples. Taking a probabilistic view of the current classification model, the temperature scalar is exactly the scale of uncertainty noise implicitly added in the softmax function. Meanwhile, the uncertainty of images in a dataset should follow a prior distribution. Based on the observation, a unified framework for uncertainty modeling and FR, Random Temperature Scaling (RTS), is proposed to learn a reliable FR algorithm. The benefits of RTS are two-fold. (1) In the training phase, it can adjust the learning strength of clean and noisy samples for stability and accuracy. (2) In the test phase, it can provide a score of confidence to detect uncertain, low-quality and even OOD samples, without training on extra labels. Extensive experiments on FR benchmarks demonstrate that the magnitude of variance in RTS, which serves as an OOD detection metric, is closely related to the uncertainty of the input image. RTS can achieve top performance on both the FR and OOD detection tasks. Moreover, the model trained with RTS can perform robustly on datasets with noise. The proposed module is light-weight and only adds negligible computation cost to the model.