 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMambaSeg: Harnessing Mamba for Accurate and Efficient Image-Event Semantic Segmentation
Dec 30, 2025Semantic segmentation is a fundamental task in computer vision with wide-ranging applications, including autonomous driving and robotics. While RGB-based methods have achieved strong performance with CNNs and Transformers, their effectiveness degrades under fast motion, low-light, or high dynamic range conditions due to limitations of frame cameras. Event cameras offer complementary advantages such as high temporal resolution and low latency, yet lack color and texture, making them insufficient on their own. To address this, recent research has explored multimodal fusion of RGB and event data; however, many existing approaches are computationally expensive and focus primarily on spatial fusion, neglecting the temporal dynamics inherent in event streams. In this work, we propose MambaSeg, a novel dual-branch semantic segmentation framework that employs parallel Mamba encoders to efficiently model RGB images and event streams. To reduce cross-modal ambiguity, we introduce the Dual-Dimensional Interaction Module (DDIM), comprising a Cross-Spatial Interaction Module (CSIM) and a Cross-Temporal Interaction Module (CTIM), which jointly perform fine-grained fusion along both spatial and temporal dimensions. This design improves cross-modal alignment, reduces ambiguity, and leverages the complementary properties of each modality. Extensive experiments on the DDD17 and DSEC datasets demonstrate that MambaSeg achieves state-of-the-art segmentation performance while significantly reducing computational cost, showcasing its promise for efficient, scalable, and robust multimodal perception.
TimePro: Efficient Multivariate Long-term Time Series Forecasting with Variable- and Time-Aware Hyper-state
May 27, 2025In long-term time series forecasting, different variables often influence the target variable over distinct time intervals, a challenge known as the multi-delay issue. Traditional models typically process all variables or time points uniformly, which limits their ability to capture complex variable relationships and obtain non-trivial time representations. To address this issue, we propose TimePro, an innovative Mamba-based model that constructs variate- and time-aware hyper-states. Unlike conventional approaches that merely transfer plain states across variable or time dimensions, TimePro preserves the fine-grained temporal features of each variate token and adaptively selects the focused time points to tune the plain state. The reconstructed hyper-state can perceive both variable relationships and salient temporal information, which helps the model make accurate forecasting. In experiments, TimePro performs competitively on eight real-world long-term forecasting benchmarks with satisfactory linear complexity. Code is available at https://github.com/xwmaxwma/TimePro.
GenVidBench: A Challenging Benchmark for Detecting AI-Generated Video
Jan 20, 2025



The rapid advancement of video generation models has made it increasingly challenging to distinguish AI-generated videos from real ones. This issue underscores the urgent need for effective AI-generated video detectors to prevent the dissemination of false information through such videos. However, the development of high-performance generative video detectors is currently impeded by the lack of large-scale, high-quality datasets specifically designed for generative video detection. To this end, we introduce GenVidBench, a challenging AI-generated video detection dataset with several key advantages: 1) Cross Source and Cross Generator: The cross-generation source mitigates the interference of video content on the detection. The cross-generator ensures diversity in video attributes between the training and test sets, preventing them from being overly similar. 2) State-of-the-Art Video Generators: The dataset includes videos from 8 state-of-the-art AI video generators, ensuring that it covers the latest advancements in the field of video generation. 3) Rich Semantics: The videos in GenVidBench are analyzed from multiple dimensions and classified into various semantic categories based on their content. This classification ensures that the dataset is not only large but also diverse, aiding in the development of more generalized and effective detection models. We conduct a comprehensive evaluation of different advanced video generators and present a challenging setting. Additionally, we present rich experimental results including advanced video classification models as baselines. With the GenVidBench, researchers can efficiently develop and evaluate AI-generated video detection models. Datasets and code are available at https://genvidbench.github.io.
TinyViM: Frequency Decoupling for Tiny Hybrid Vision Mamba
Nov 26, 2024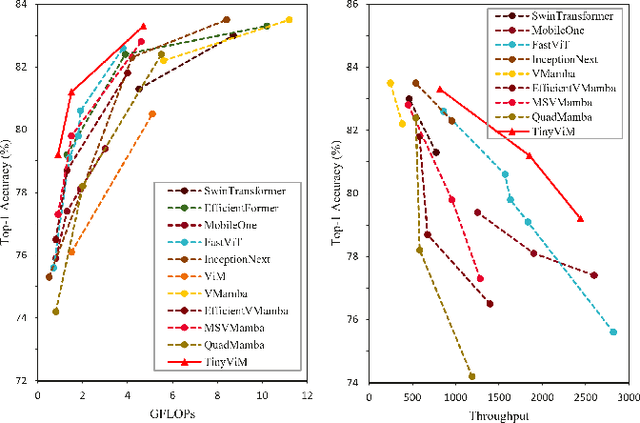
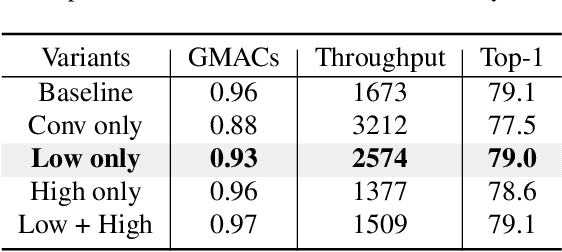
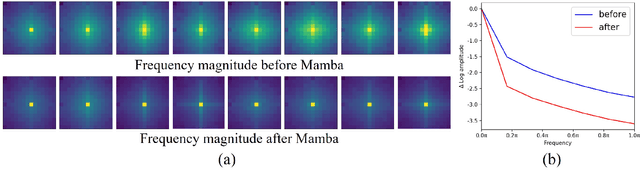
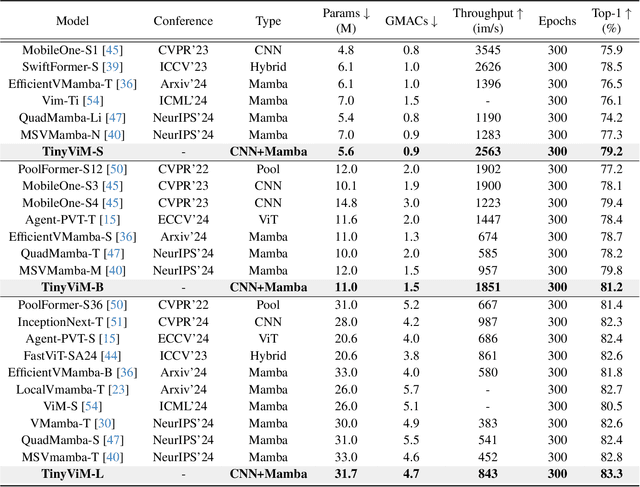
Mamba has shown great potential for computer vision due to its linear complexity in modeling the global context with respect to the input length. However, existing lightweight Mamba-based backbones cannot demonstrate performance that matches Convolution or Transformer-based methods. We observe that simply modifying the scanning path in the image domain is not conducive to fully exploiting the potential of vision Mamba. In this paper, we first perform comprehensive spectral and quantitative analyses, and verify that the Mamba block mainly models low-frequency information under Convolution-Mamba hybrid architecture. Based on the analyses, we introduce a novel Laplace mixer to decouple the features in terms of frequency and input only the low-frequency components into the Mamba block. In addition, considering the redundancy of the features and the different requirements for high-frequency details and low-frequency global information at different stages, we introduce a frequency ramp inception, i.e., gradually reduce the input dimensions of the high-frequency branches, so as to efficiently trade-off the high-frequency and low-frequency components at different layers. By integrating mobile-friendly convolution and efficient Laplace mixer, we build a series of tiny hybrid vision Mamba called TinyViM. The proposed TinyViM achieves impressive performance on several downstream tasks including image classification, semantic segmentation, object detection and instance segmentation. In particular, TinyViM outperforms Convolution, Transformer and Mamba-based models with similar scales, and the throughput is about 2-3 times higher than that of other Mamba-based models. Code is available at https://github.com/xwmaxwma/TinyViM.
Semantic and Spatial Adaptive Pixel-level Classifier for Semantic Segmentation
May 10, 2024



Vanilla pixel-level classifiers for semantic segmentation are based on a certain paradigm, involving the inner product of fixed prototypes obtained from the training set and pixel features in the test image. This approach, however, encounters significant limitations, i.e., feature deviation in the semantic domain and information loss in the spatial domain. The former struggles with large intra-class variance among pixel features from different images, while the latter fails to utilize the structured information of semantic objects effectively. This leads to blurred mask boundaries as well as a deficiency of fine-grained recognition capability. In this paper, we propose a novel Semantic and Spatial Adaptive (SSA) classifier to address the above challenges. Specifically, we employ the coarse masks obtained from the fixed prototypes as a guide to adjust the fixed prototype towards the center of the semantic and spatial domains in the test image. The adapted prototypes in semantic and spatial domains are then simultaneously considered to accomplish classification decisions. In addition, we propose an online multi-domain distillation learning strategy to improve the adaption process. Experimental results on three publicly available benchmarks show that the proposed SSA significantly improves the segmentation performance of the baseline models with only a minimal increase in computational cost. Code is available at https://github.com/xwmaxwma/SSA.
Context-Guided Spatial Feature Reconstruction for Efficient Semantic Segmentation
May 10, 2024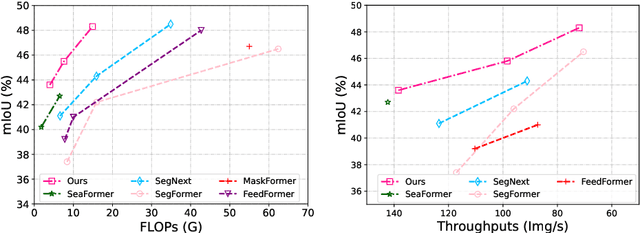
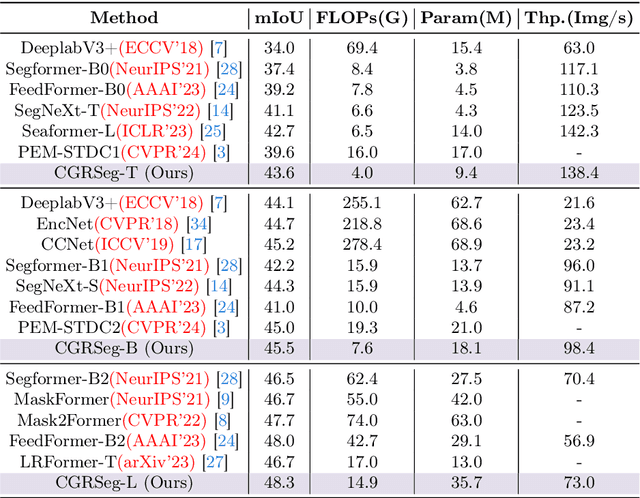


Semantic segmentation is an important task for many applications but it is still quite challenging to achieve advanced performance with limited computational costs. In this paper, we present CGRSeg, an efficient yet competitive segmentation framework based on context-guided spatial feature reconstruction. A Rectangular Self-Calibration Module is carefully designed for spatial feature reconstruction and pyramid context extraction. It captures the global context in both horizontal and vertical directions and gets the axial global context to explicitly model rectangular key areas. A shape self-calibration function is designed to make the key areas more close to the foreground object. Besides, a lightweight Dynamic Prototype Guided head is proposed to improve the classification of foreground objects by explicit class embedding. Our CGRSeg is extensively evaluated on ADE20K, COCO-Stuff, and Pascal Context benchmarks, and achieves state-of-the-art semantic performance. Specifically, it achieves $43.6\%$ mIoU on ADE20K with only $4.0$ GFLOPs, which is $0.9\%$ and $2.5\%$ mIoU better than SeaFormer and SegNeXt but with about $38.0\%$ fewer GFLOPs. Code is available at https://github.com/nizhenliang/CGRSeg.
Dual Relation Knowledge Distillation for Object Detection
Feb 11, 2023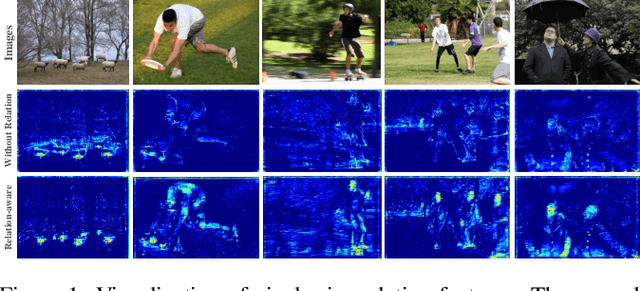
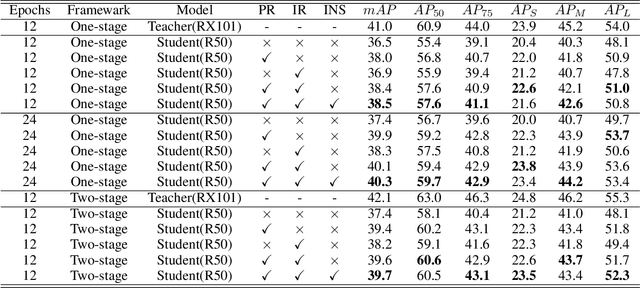

Knowledge distillation is an effective method for model compression. However, it is still a challenging topic to apply knowledge distillation to detection tasks. There are two key points resulting poor distillation performance for detection tasks. One is the serious imbalance between foreground and background features, another one is that small object lacks enough feature representation. To solve the above issues, we propose a new distillation method named dual relation knowledge distillation (DRKD), including pixel-wise relation distillation and instance-wise relation distillation.The pixel-wise relation distillation embeds pixel-wise features in the graph space and applies graph convolution to capture the global pixel relation. By distilling the global pixel relation, the student detector can learn the relation between foreground and background features, avoid the difficulty of distilling feature directly for feature imbalance issue.Besides, we find that instance-wise relation supplements valuable knowledge beyond independent features for small objects. Thus, the instance-wise relation distillation is designed, which calculates the similarity of different instances to obtain a relation matrix. More importantly, a relation filter module is designed to highlight valuable instance relations.The proposed dual relation knowledge distillation is general and can be easily applied for both one-stage and two-stage detectors. Our method achieves state-of-the-art performance, which improves Faster R-CNN based on ResNet50 from 38.4\% to 41.6\% mAP and improves RetinaNet based on ResNet50 from 37.4% to 40.3% mAP on COCO 2017.