 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTinyViM: Frequency Decoupling for Tiny Hybrid Vision Mamba
Paper and Code
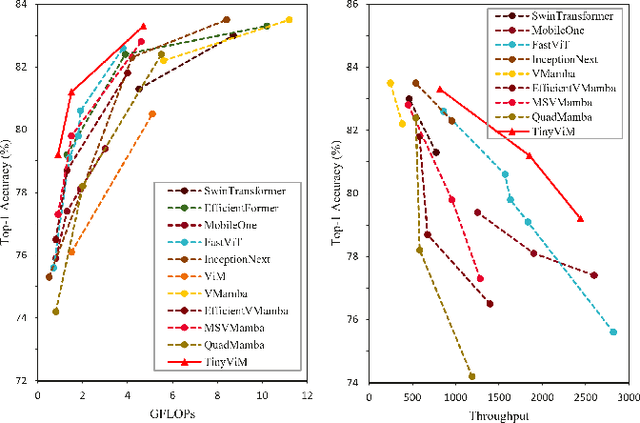
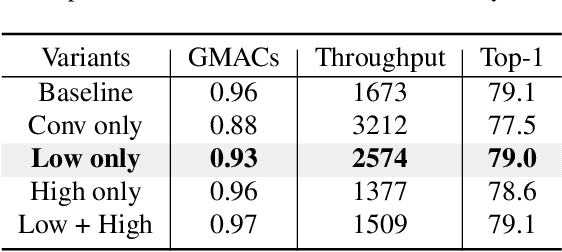
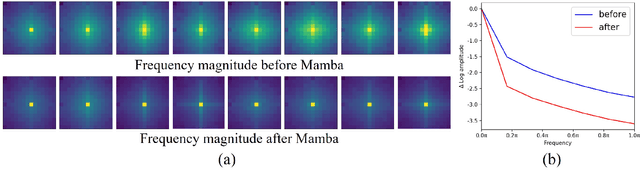
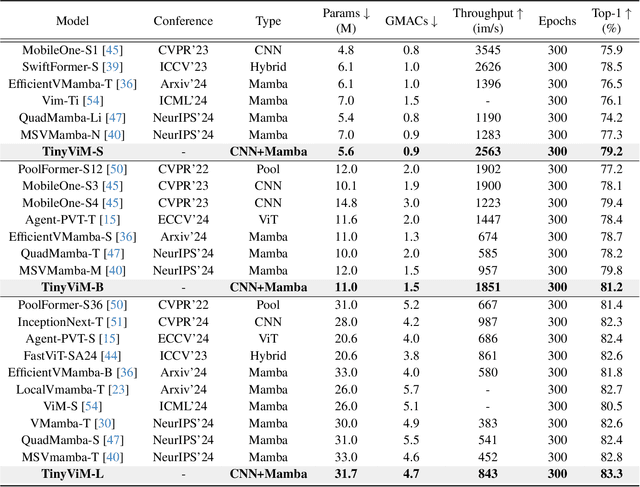
Mamba has shown great potential for computer vision due to its linear complexity in modeling the global context with respect to the input length. However, existing lightweight Mamba-based backbones cannot demonstrate performance that matches Convolution or Transformer-based methods. We observe that simply modifying the scanning path in the image domain is not conducive to fully exploiting the potential of vision Mamba. In this paper, we first perform comprehensive spectral and quantitative analyses, and verify that the Mamba block mainly models low-frequency information under Convolution-Mamba hybrid architecture. Based on the analyses, we introduce a novel Laplace mixer to decouple the features in terms of frequency and input only the low-frequency components into the Mamba block. In addition, considering the redundancy of the features and the different requirements for high-frequency details and low-frequency global information at different stages, we introduce a frequency ramp inception, i.e., gradually reduce the input dimensions of the high-frequency branches, so as to efficiently trade-off the high-frequency and low-frequency components at different layers. By integrating mobile-friendly convolution and efficient Laplace mixer, we build a series of tiny hybrid vision Mamba called TinyViM. The proposed TinyViM achieves impressive performance on several downstream tasks including image classification, semantic segmentation, object detection and instance segmentation. In particular, TinyViM outperforms Convolution, Transformer and Mamba-based models with similar scales, and the throughput is about 2-3 times higher than that of other Mamba-based models. Code is available at https://github.com/xwmaxwma/TinyViM.