 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Relation Knowledge Distillation for Object Detection
Feb 11, 2023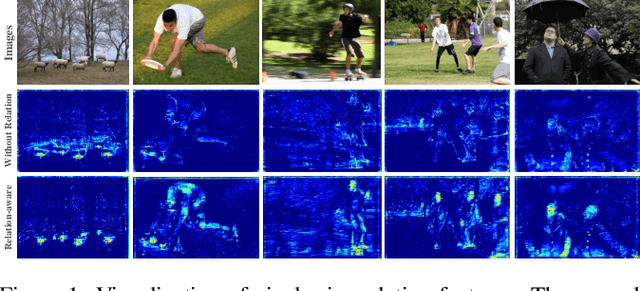
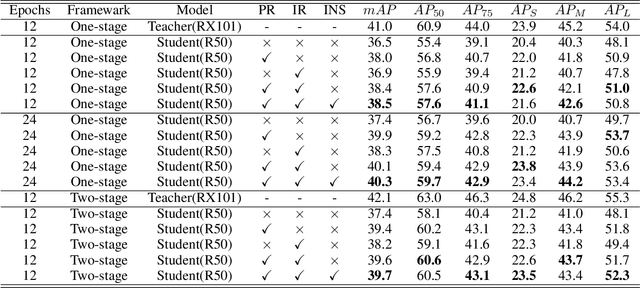

Knowledge distillation is an effective method for model compression. However, it is still a challenging topic to apply knowledge distillation to detection tasks. There are two key points resulting poor distillation performance for detection tasks. One is the serious imbalance between foreground and background features, another one is that small object lacks enough feature representation. To solve the above issues, we propose a new distillation method named dual relation knowledge distillation (DRKD), including pixel-wise relation distillation and instance-wise relation distillation.The pixel-wise relation distillation embeds pixel-wise features in the graph space and applies graph convolution to capture the global pixel relation. By distilling the global pixel relation, the student detector can learn the relation between foreground and background features, avoid the difficulty of distilling feature directly for feature imbalance issue.Besides, we find that instance-wise relation supplements valuable knowledge beyond independent features for small objects. Thus, the instance-wise relation distillation is designed, which calculates the similarity of different instances to obtain a relation matrix. More importantly, a relation filter module is designed to highlight valuable instance relations.The proposed dual relation knowledge distillation is general and can be easily applied for both one-stage and two-stage detectors. Our method achieves state-of-the-art performance, which improves Faster R-CNN based on ResNet50 from 38.4\% to 41.6\% mAP and improves RetinaNet based on ResNet50 from 37.4% to 40.3% mAP on COCO 2017.
Knowledge Distillation for Detection Transformer with Consistent Distillation Points Sampling
Nov 16, 2022

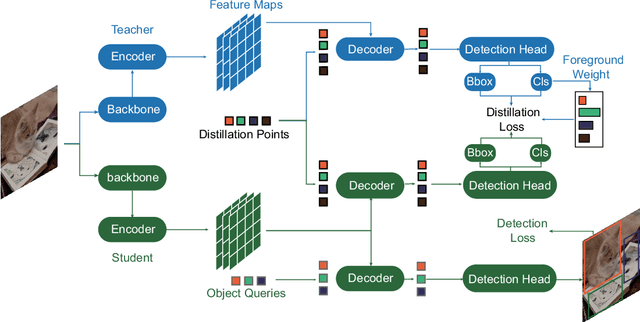

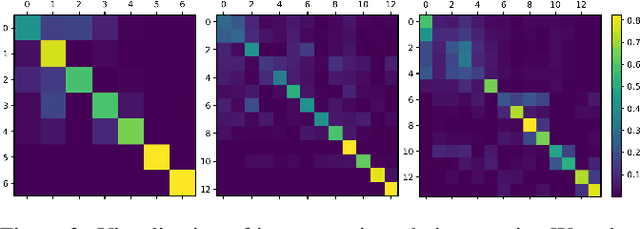
DETR is a novel end-to-end transformer architecture object detector, which significantly outperforms classic detectors when scaling up the model size. In this paper, we focus on the compression of DETR with knowledge distillation. While knowledge distillation has been well-studied in classic detectors, there is a lack of researches on how to make it work effectively on DETR. We first provide experimental and theoretical analysis to point out that the main challenge in DETR distillation is the lack of consistent distillation points. Distillation points refer to the corresponding inputs of the predictions for student to mimic, and reliable distillation requires sufficient distillation points which are consistent between teacher and student. Based on this observation, we propose a general knowledge distillation paradigm for DETR(KD-DETR) with consistent distillation points sampling. Specifically, we decouple detection and distillation tasks by introducing a set of specialized object queries to construct distillation points. In this paradigm, we further propose a general-to-specific distillation points sampling strategy to explore the extensibility of KD-DETR. Extensive experiments on different DETR architectures with various scales of backbones and transformer layers validate the effectiveness and generalization of KD-DETR. KD-DETR boosts the performance of DAB-DETR with ResNet-18 and ResNet-50 backbone to 41.4$\%$, 45.7$\%$ mAP, respectively, which are 5.2$\%$, 3.5$\%$ higher than the baseline, and ResNet-50 even surpasses the teacher model by $2.2\%$.