 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenVidBench: A Challenging Benchmark for Detecting AI-Generated Video
Jan 20, 2025



The rapid advancement of video generation models has made it increasingly challenging to distinguish AI-generated videos from real ones. This issue underscores the urgent need for effective AI-generated video detectors to prevent the dissemination of false information through such videos. However, the development of high-performance generative video detectors is currently impeded by the lack of large-scale, high-quality datasets specifically designed for generative video detection. To this end, we introduce GenVidBench, a challenging AI-generated video detection dataset with several key advantages: 1) Cross Source and Cross Generator: The cross-generation source mitigates the interference of video content on the detection. The cross-generator ensures diversity in video attributes between the training and test sets, preventing them from being overly similar. 2) State-of-the-Art Video Generators: The dataset includes videos from 8 state-of-the-art AI video generators, ensuring that it covers the latest advancements in the field of video generation. 3) Rich Semantics: The videos in GenVidBench are analyzed from multiple dimensions and classified into various semantic categories based on their content. This classification ensures that the dataset is not only large but also diverse, aiding in the development of more generalized and effective detection models. We conduct a comprehensive evaluation of different advanced video generators and present a challenging setting. Additionally, we present rich experimental results including advanced video classification models as baselines. With the GenVidBench, researchers can efficiently develop and evaluate AI-generated video detection models. Datasets and code are available at https://genvidbench.github.io.
Multiple instance active learning for object detection
Apr 06, 2021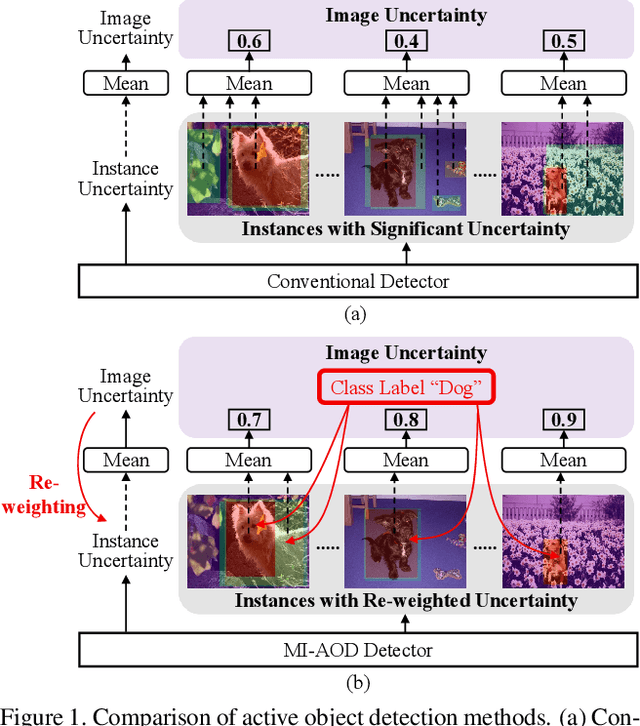
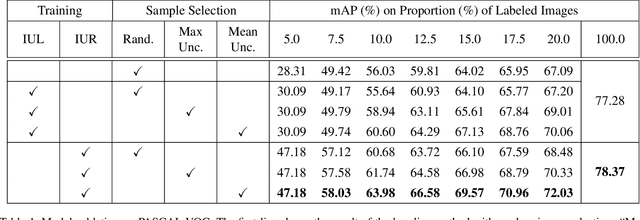
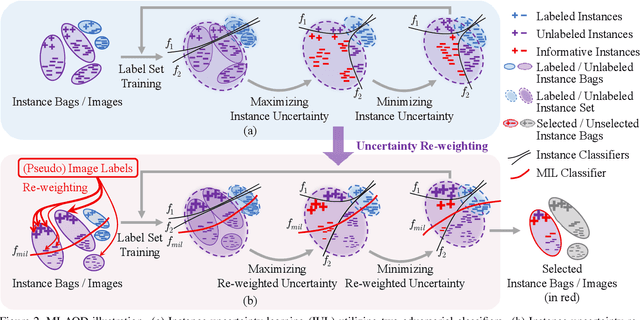
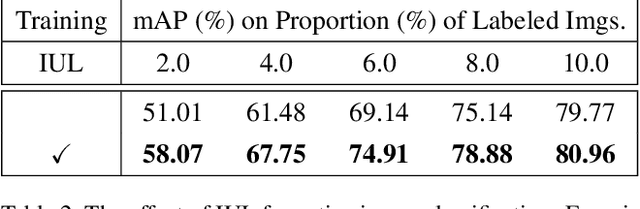
Despite the substantial progress of active learning for image recognition, there still lacks an instance-level active learning method specified for object detection. In this paper, we propose Multiple Instance Active Object Detection (MI-AOD), to select the most informative images for detector training by observing instance-level uncertainty. MI-AOD defines an instance uncertainty learning module, which leverages the discrepancy of two adversarial instance classifiers trained on the labeled set to predict instance uncertainty of the unlabeled set. MI-AOD treats unlabeled images as instance bags and feature anchors in images as instances, and estimates the image uncertainty by re-weighting instances in a multiple instance learning (MIL) fashion. Iterative instance uncertainty learning and re-weighting facilitate suppressing noisy instances, toward bridging the gap between instance uncertainty and image-level uncertainty. Experiments validate that MI-AOD sets a solid baseline for instance-level active learning. On commonly used object detection datasets, MI-AOD outperforms state-of-the-art methods with significant margins, particularly when the labeled sets are small. Code is available at https://github.com/yuantn/MI-AOD.