 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJDPNet: A Network Based on Joint Degradation Processing for Underwater Image Enhancement
Dec 23, 2025



Given the complexity of underwater environments and the variability of water as a medium, underwater images are inevitably subject to various types of degradation. The degradations present nonlinear coupling rather than simple superposition, which renders the effective processing of such coupled degradations particularly challenging. Most existing methods focus on designing specific branches, modules, or strategies for specific degradations, with little attention paid to the potential information embedded in their coupling. Consequently, they struggle to effectively capture and process the nonlinear interactions of multiple degradations from a bottom-up perspective. To address this issue, we propose JDPNet, a joint degradation processing network, that mines and unifies the potential information inherent in coupled degradations within a unified framework. Specifically, we introduce a joint feature-mining module, along with a probabilistic bootstrap distribution strategy, to facilitate effective mining and unified adjustment of coupled degradation features. Furthermore, to balance color, clarity, and contrast, we design a novel AquaBalanceLoss to guide the network in learning from multiple coupled degradation losses. Experiments on six publicly available underwater datasets, as well as two new datasets constructed in this study, show that JDPNet exhibits state-of-the-art performance while offering a better tradeoff between performance, parameter size, and computational cost.
Towards Efficient Agents: A Co-Design of Inference Architecture and System
Dec 20, 2025The rapid development of large language model (LLM)-based agents has unlocked new possibilities for autonomous multi-turn reasoning and tool-augmented decision-making. However, their real-world deployment is hindered by severe inefficiencies that arise not from isolated model inference, but from the systemic latency accumulated across reasoning loops, context growth, and heterogeneous tool interactions. This paper presents AgentInfer, a unified framework for end-to-end agent acceleration that bridges inference optimization and architectural design. We decompose the problem into four synergistic components: AgentCollab, a hierarchical dual-model reasoning framework that balances large- and small-model usage through dynamic role assignment; AgentSched, a cache-aware hybrid scheduler that minimizes latency under heterogeneous request patterns; AgentSAM, a suffix-automaton-based speculative decoding method that reuses multi-session semantic memory to achieve low-overhead inference acceleration; and AgentCompress, a semantic compression mechanism that asynchronously distills and reorganizes agent memory without disrupting ongoing reasoning. Together, these modules form a Self-Evolution Engine capable of sustaining efficiency and cognitive stability throughout long-horizon reasoning tasks. Experiments on the BrowseComp-zh and DeepDiver benchmarks demonstrate that through the synergistic collaboration of these methods, AgentInfer reduces ineffective token consumption by over 50%, achieving an overall 1.8-2.5 times speedup with preserved accuracy. These results underscore that optimizing for agentic task completion-rather than merely per-token throughput-is the key to building scalable, efficient, and self-improving intelligent systems.
Text-Guided Channel Perturbation and Pretrained Knowledge Integration for Unified Multi-Modality Image Fusion
Nov 16, 2025Multi-modality image fusion enhances scene perception by combining complementary information. Unified models aim to share parameters across modalities for multi-modality image fusion, but large modality differences often cause gradient conflicts, limiting performance. Some methods introduce modality-specific encoders to enhance feature perception and improve fusion quality. However, this strategy reduces generalisation across different fusion tasks. To overcome this limitation, we propose a unified multi-modality image fusion framework based on channel perturbation and pre-trained knowledge integration (UP-Fusion). To suppress redundant modal information and emphasize key features, we propose the Semantic-Aware Channel Pruning Module (SCPM), which leverages the semantic perception capability of a pre-trained model to filter and enhance multi-modality feature channels. Furthermore, we proposed the Geometric Affine Modulation Module (GAM), which uses original modal features to apply affine transformations on initial fusion features to maintain the feature encoder modal discriminability. Finally, we apply a Text-Guided Channel Perturbation Module (TCPM) during decoding to reshape the channel distribution, reducing the dependence on modality-specific channels. Extensive experiments demonstrate that the proposed algorithm outperforms existing methods on both multi-modality image fusion and downstream tasks.
FlexiD-Fuse: Flexible number of inputs multi-modal medical image fusion based on diffusion model
Sep 11, 2025



Different modalities of medical images provide unique physiological and anatomical information for diseases. Multi-modal medical image fusion integrates useful information from different complementary medical images with different modalities, producing a fused image that comprehensively and objectively reflects lesion characteristics to assist doctors in clinical diagnosis. However, existing fusion methods can only handle a fixed number of modality inputs, such as accepting only two-modal or tri-modal inputs, and cannot directly process varying input quantities, which hinders their application in clinical settings. To tackle this issue, we introduce FlexiD-Fuse, a diffusion-based image fusion network designed to accommodate flexible quantities of input modalities. It can end-to-end process two-modal and tri-modal medical image fusion under the same weight. FlexiD-Fuse transforms the diffusion fusion problem, which supports only fixed-condition inputs, into a maximum likelihood estimation problem based on the diffusion process and hierarchical Bayesian modeling. By incorporating the Expectation-Maximization algorithm into the diffusion sampling iteration process, FlexiD-Fuse can generate high-quality fused images with cross-modal information from source images, independently of the number of input images. We compared the latest two and tri-modal medical image fusion methods, tested them on Harvard datasets, and evaluated them using nine popular metrics. The experimental results show that our method achieves the best performance in medical image fusion with varying inputs. Meanwhile, we conducted extensive extension experiments on infrared-visible, multi-exposure, and multi-focus image fusion tasks with arbitrary numbers, and compared them with the perspective SOTA methods. The results of the extension experiments consistently demonstrate the effectiveness and superiority of our method.
FS-Diff: Semantic guidance and clarity-aware simultaneous multimodal image fusion and super-resolution
Sep 11, 2025As an influential information fusion and low-level vision technique, image fusion integrates complementary information from source images to yield an informative fused image. A few attempts have been made in recent years to jointly realize image fusion and super-resolution. However, in real-world applications such as military reconnaissance and long-range detection missions, the target and background structures in multimodal images are easily corrupted, with low resolution and weak semantic information, which leads to suboptimal results in current fusion techniques. In response, we propose FS-Diff, a semantic guidance and clarity-aware joint image fusion and super-resolution method. FS-Diff unifies image fusion and super-resolution as a conditional generation problem. It leverages semantic guidance from the proposed clarity sensing mechanism for adaptive low-resolution perception and cross-modal feature extraction. Specifically, we initialize the desired fused result as pure Gaussian noise and introduce the bidirectional feature Mamba to extract the global features of the multimodal images. Moreover, utilizing the source images and semantics as conditions, we implement a random iterative denoising process via a modified U-Net network. This network istrained for denoising at multiple noise levels to produce high-resolution fusion results with cross-modal features and abundant semantic information. We also construct a powerful aerial view multiscene (AVMS) benchmark covering 600 pairs of images. Extensive joint image fusion and super-resolution experiments on six public and our AVMS datasets demonstrated that FS-Diff outperforms the state-of-the-art methods at multiple magnifications and can recover richer details and semantics in the fused images. The code is available at https://github.com/XylonXu01/FS-Diff.
AWM-Fuse: Multi-Modality Image Fusion for Adverse Weather via Global and Local Text Perception
Aug 23, 2025



Multi-modality image fusion (MMIF) in adverse weather aims to address the loss of visual information caused by weather-related degradations, providing clearer scene representations. Although less studies have attempted to incorporate textual information to improve semantic perception, they often lack effective categorization and thorough analysis of textual content. In response, we propose AWM-Fuse, a novel fusion method for adverse weather conditions, designed to handle multiple degradations through global and local text perception within a unified, shared weight architecture. In particular, a global feature perception module leverages BLIP-produced captions to extract overall scene features and identify primary degradation types, thus promoting generalization across various adverse weather conditions. Complementing this, the local module employs detailed scene descriptions produced by ChatGPT to concentrate on specific degradation effects through concrete textual cues, thereby capturing finer details. Furthermore, textual descriptions are used to constrain the generation of fusion images, effectively steering the network learning process toward better alignment with real semantic labels, thereby promoting the learning of more meaningful visual features. Extensive experiments demonstrate that AWM-Fuse outperforms current state-of-the-art methods in complex weather conditions and downstream tasks. Our code is available at https://github.com/Feecuin/AWM-Fuse.
MambaTrans: Multimodal Fusion Image Translation via Large Language Model Priors for Downstream Visual Tasks
Aug 11, 2025The goal of multimodal image fusion is to integrate complementary information from infrared and visible images, generating multimodal fused images for downstream tasks. Existing downstream pre-training models are typically trained on visible images. However, the significant pixel distribution differences between visible and multimodal fusion images can degrade downstream task performance, sometimes even below that of using only visible images. This paper explores adapting multimodal fused images with significant modality differences to object detection and semantic segmentation models trained on visible images. To address this, we propose MambaTrans, a novel multimodal fusion image modality translator. MambaTrans uses descriptions from a multimodal large language model and masks from semantic segmentation models as input. Its core component, the Multi-Model State Space Block, combines mask-image-text cross-attention and a 3D-Selective Scan Module, enhancing pure visual capabilities. By leveraging object detection prior knowledge, MambaTrans minimizes detection loss during training and captures long-term dependencies among text, masks, and images. This enables favorable results in pre-trained models without adjusting their parameters. Experiments on public datasets show that MambaTrans effectively improves multimodal image performance in downstream tasks.
EAQuant: Enhancing Post-Training Quantization for MoE Models via Expert-Aware Optimization
Jun 16, 2025Mixture-of-Experts (MoE) models have emerged as a cornerstone of large-scale deep learning by efficiently distributing computation and enhancing performance. However, their unique architecture-characterized by sparse expert activation and dynamic routing mechanisms-introduces inherent complexities that challenge conventional quantization techniques. Existing post-training quantization (PTQ) methods struggle to address activation outliers, router consistency and sparse expert calibration, leading to significant performance degradation. To bridge this gap, we propose EAQuant, a novel PTQ framework tailored for MoE architectures. Our method systematically tackles these challenges through three key innovations: (1) expert-aware smoothing aggregation to suppress activation outliers and stabilize quantization, (2) router logits distribution alignment to preserve expert selection consistency post-quantization, and (3) expert-level calibration data balance to optimize sparsely activated experts. Extensive experiments across W4A4 and extreme W3A4 quantization configurations demonstrate that EAQuant significantly outperforms existing methods, achieving average score improvements of 1.15 - 2.28% across three diverse MoE architectures, with particularly pronounced gains in reasoning tasks and robust performance retention under aggressive quantization. By integrating these innovations, EAQuant establishes a new state-of-the-art for high-precision, efficient MoE model compression. Our code is available at https://github.com/darren-fzq/EAQuant.
Pangu Pro MoE: Mixture of Grouped Experts for Efficient Sparsity
May 28, 2025The surgence of Mixture of Experts (MoE) in Large Language Models promises a small price of execution cost for a much larger model parameter count and learning capacity, because only a small fraction of parameters are activated for each input token. However, it is commonly observed that some experts are activated far more often than others, leading to system inefficiency when running the experts on different devices in parallel. Therefore, we introduce Mixture of Grouped Experts (MoGE), which groups the experts during selection and balances the expert workload better than MoE in nature. It constrains tokens to activate an equal number of experts within each predefined expert group. When a model execution is distributed on multiple devices, this architectural design ensures a balanced computational load across devices, significantly enhancing throughput, particularly for the inference phase. Further, we build Pangu Pro MoE on Ascend NPUs, a sparse model based on MoGE with 72 billion total parameters, 16 billion of which are activated for each token. The configuration of Pangu Pro MoE is optimized for Ascend 300I Duo and 800I A2 through extensive system simulation studies. Our experiments indicate that MoGE indeed leads to better expert load balancing and more efficient execution for both model training and inference on Ascend NPUs. The inference performance of Pangu Pro MoE achieves 1148 tokens/s per card and can be further improved to 1528 tokens/s per card by speculative acceleration, outperforming comparable 32B and 72B Dense models. Furthermore, we achieve an excellent cost-to-performance ratio for model inference on Ascend 300I Duo. Our studies show that Ascend NPUs are capable of training Pangu Pro MoE with massive parallelization to make it a leading model within the sub-100B total parameter class, outperforming prominent open-source models like GLM-Z1-32B and Qwen3-32B.
TrimR: Verifier-based Training-Free Thinking Compression for Efficient Test-Time Scaling
May 22, 2025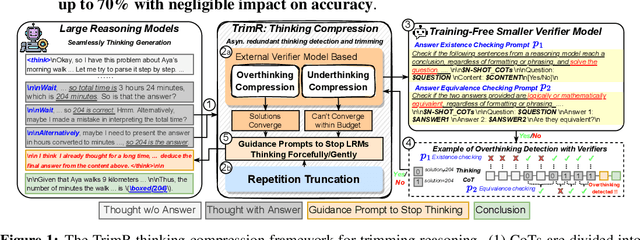
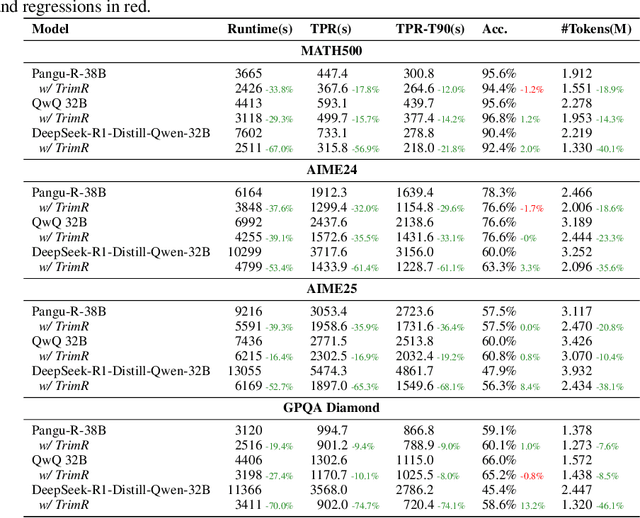
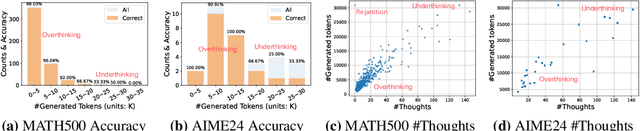
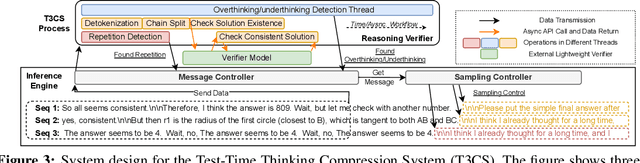
Large Reasoning Models (LRMs) demonstrate exceptional capability in tackling complex mathematical, logical, and coding tasks by leveraging extended Chain-of-Thought (CoT) reasoning. Test-time scaling methods, such as prolonging CoT with explicit token-level exploration, can push LRMs' accuracy boundaries, but they incur significant decoding overhead. A key inefficiency source is LRMs often generate redundant thinking CoTs, which demonstrate clear structured overthinking and underthinking patterns. Inspired by human cognitive reasoning processes and numerical optimization theories, we propose TrimR, a verifier-based, training-free, efficient framework for dynamic CoT compression to trim reasoning and enhance test-time scaling, explicitly tailored for production-level deployment. Our method employs a lightweight, pretrained, instruction-tuned verifier to detect and truncate redundant intermediate thoughts of LRMs without any LRM or verifier fine-tuning. We present both the core algorithm and asynchronous online system engineered for high-throughput industrial applications. Empirical evaluations on Ascend NPUs and vLLM show that our framework delivers substantial gains in inference efficiency under large-batch workloads. In particular, on the four MATH500, AIME24, AIME25, and GPQA benchmarks, the reasoning runtime of Pangu-R-38B, QwQ-32B, and DeepSeek-R1-Distill-Qwen-32B is improved by up to 70% with negligible impact on accuracy.