 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexiD-Fuse: Flexible number of inputs multi-modal medical image fusion based on diffusion model
Sep 11, 2025



Different modalities of medical images provide unique physiological and anatomical information for diseases. Multi-modal medical image fusion integrates useful information from different complementary medical images with different modalities, producing a fused image that comprehensively and objectively reflects lesion characteristics to assist doctors in clinical diagnosis. However, existing fusion methods can only handle a fixed number of modality inputs, such as accepting only two-modal or tri-modal inputs, and cannot directly process varying input quantities, which hinders their application in clinical settings. To tackle this issue, we introduce FlexiD-Fuse, a diffusion-based image fusion network designed to accommodate flexible quantities of input modalities. It can end-to-end process two-modal and tri-modal medical image fusion under the same weight. FlexiD-Fuse transforms the diffusion fusion problem, which supports only fixed-condition inputs, into a maximum likelihood estimation problem based on the diffusion process and hierarchical Bayesian modeling. By incorporating the Expectation-Maximization algorithm into the diffusion sampling iteration process, FlexiD-Fuse can generate high-quality fused images with cross-modal information from source images, independently of the number of input images. We compared the latest two and tri-modal medical image fusion methods, tested them on Harvard datasets, and evaluated them using nine popular metrics. The experimental results show that our method achieves the best performance in medical image fusion with varying inputs. Meanwhile, we conducted extensive extension experiments on infrared-visible, multi-exposure, and multi-focus image fusion tasks with arbitrary numbers, and compared them with the perspective SOTA methods. The results of the extension experiments consistently demonstrate the effectiveness and superiority of our method.
MambaTrans: Multimodal Fusion Image Translation via Large Language Model Priors for Downstream Visual Tasks
Aug 11, 2025The goal of multimodal image fusion is to integrate complementary information from infrared and visible images, generating multimodal fused images for downstream tasks. Existing downstream pre-training models are typically trained on visible images. However, the significant pixel distribution differences between visible and multimodal fusion images can degrade downstream task performance, sometimes even below that of using only visible images. This paper explores adapting multimodal fused images with significant modality differences to object detection and semantic segmentation models trained on visible images. To address this, we propose MambaTrans, a novel multimodal fusion image modality translator. MambaTrans uses descriptions from a multimodal large language model and masks from semantic segmentation models as input. Its core component, the Multi-Model State Space Block, combines mask-image-text cross-attention and a 3D-Selective Scan Module, enhancing pure visual capabilities. By leveraging object detection prior knowledge, MambaTrans minimizes detection loss during training and captures long-term dependencies among text, masks, and images. This enables favorable results in pre-trained models without adjusting their parameters. Experiments on public datasets show that MambaTrans effectively improves multimodal image performance in downstream tasks.
Simultaneous Tri-Modal Medical Image Fusion and Super-Resolution using Conditional Diffusion Model
Apr 26, 2024In clinical practice, tri-modal medical image fusion, compared to the existing dual-modal technique, can provide a more comprehensive view of the lesions, aiding physicians in evaluating the disease's shape, location, and biological activity. However, due to the limitations of imaging equipment and considerations for patient safety, the quality of medical images is usually limited, leading to sub-optimal fusion performance, and affecting the depth of image analysis by the physician. Thus, there is an urgent need for a technology that can both enhance image resolution and integrate multi-modal information. Although current image processing methods can effectively address image fusion and super-resolution individually, solving both problems synchronously remains extremely challenging. In this paper, we propose TFS-Diff, a simultaneously realize tri-modal medical image fusion and super-resolution model. Specially, TFS-Diff is based on the diffusion model generation of a random iterative denoising process. We also develop a simple objective function and the proposed fusion super-resolution loss, effectively evaluates the uncertainty in the fusion and ensures the stability of the optimization process. And the channel attention module is proposed to effectively integrate key information from different modalities for clinical diagnosis, avoiding information loss caused by multiple image processing. Extensive experiments on public Harvard datasets show that TFS-Diff significantly surpass the existing state-of-the-art methods in both quantitative and visual evaluations. The source code will be available at GitHub.
Physical Perception Network and an All-weather Multi-modality Benchmark for Adverse Weather Image Fusion
Feb 03, 2024



Multi-modality image fusion (MMIF) integrates the complementary information from different modal images to provide comprehensive and objective interpretation of a scenes. However, existing MMIF methods lack the ability to resist different weather interferences in real-life scenarios, preventing them from being useful in practical applications such as autonomous driving. To bridge this research gap, we proposed an all-weather MMIF model. Regarding deep learning architectures, their network designs are often viewed as a black box, which limits their multitasking capabilities. For deweathering module, we propose a physically-aware clear feature prediction module based on an atmospheric scattering model that can deduce variations in light transmittance from both scene illumination and depth. For fusion module, We utilize a learnable low-rank representation model to decompose images into low-rank and sparse components. This highly interpretable feature separation allows us to better observe and understand images. Furthermore, we have established a benchmark for MMIF research under extreme weather conditions. It encompasses multiple scenes under three types of weather: rain, haze, and snow, with each weather condition further subdivided into various impact levels. Extensive fusion experiments under adverse weather demonstrate that the proposed algorithm has excellent detail recovery and multi-modality feature extraction capabilities.
Decomposition-based and Interference Perception for Infrared and Visible Image Fusion in Complex Scenes
Feb 03, 2024Infrared and visible image fusion has emerged as a prominent research in computer vision. However, little attention has been paid on complex scenes fusion, causing existing techniques to produce sub-optimal results when suffers from real interferences. To fill this gap, we propose a decomposition-based and interference perception image fusion method. Specifically, we classify the pixels of visible image from the degree of scattering of light transmission, based on which we then separate the detail and energy information of the image. This refined decomposition facilitates the proposed model in identifying more interfering pixels that are in complex scenes. To strike a balance between denoising and detail preservation, we propose an adaptive denoising scheme for fusing detail components. Meanwhile, we propose a new weighted fusion rule by considering the distribution of image energy information from the perspective of multiple directions. Extensive experiments in complex scenes fusions cover adverse weathers, noise, blur, overexposure, fire, as well as downstream tasks including semantic segmentation, object detection, salient object detection and depth estimation, consistently indicate the effectiveness and superiority of the proposed method compared with the recent representative methods.
TSJNet: A Multi-modality Target and Semantic Awareness Joint-driven Image Fusion Network
Feb 02, 2024Multi-modality image fusion involves integrating complementary information from different modalities into a single image. Current methods primarily focus on enhancing image fusion with a single advanced task such as incorporating semantic or object-related information into the fusion process. This method creates challenges in achieving multiple objectives simultaneously. We introduce a target and semantic awareness joint-driven fusion network called TSJNet. TSJNet comprises fusion, detection, and segmentation subnetworks arranged in a series structure. It leverages object and semantically relevant information derived from dual high-level tasks to guide the fusion network. Additionally, We propose a local significant feature extraction module with a double parallel branch structure to fully capture the fine-grained features of cross-modal images and foster interaction among modalities, targets, and segmentation information. We conducted extensive experiments on four publicly available datasets (MSRS, M3FD, RoadScene, and LLVIP). The results demonstrate that TSJNet can generate visually pleasing fused results, achieving an average increase of 2.84% and 7.47% in object detection and segmentation mAP @0.5 and mIoU, respectively, compared to the state-of-the-art methods.
SAMF: Small-Area-Aware Multi-focus Image Fusion for Object Detection
Jan 31, 2024



Existing multi-focus image fusion (MFIF) methods often fail to preserve the uncertain transition region and detect small focus areas within large defocused regions accurately. To address this issue, this study proposes a new small-area-aware MFIF algorithm for enhancing object detection capability. First, we enhance the pixel attributes within the small focus and boundary regions, which are subsequently combined with visual saliency detection to obtain the pre-fusion results used to discriminate the distribution of focused pixels. To accurately ensure pixel focus, we consider the source image as a combination of focused, defocused, and uncertain regions and propose a three-region segmentation strategy. Finally, we design an effective pixel selection rule to generate segmentation decision maps and obtain the final fusion results. Experiments demonstrated that the proposed method can accurately detect small and smooth focus areas while improving object detection performance, outperforming existing methods in both subjective and objective evaluations. The source code is available at https://github.com/ixilai/SAMF.
Bridging the Gap between Multi-focus and Multi-modal: A Focused Integration Framework for Multi-modal Image Fusion
Nov 03, 2023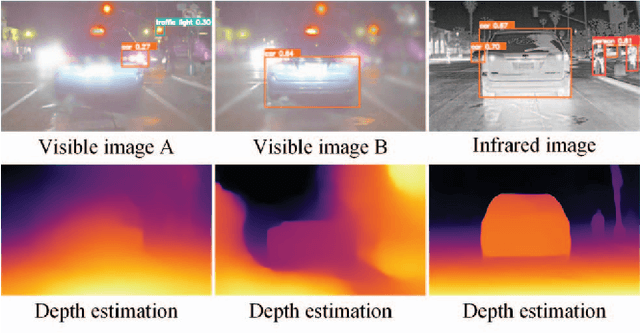
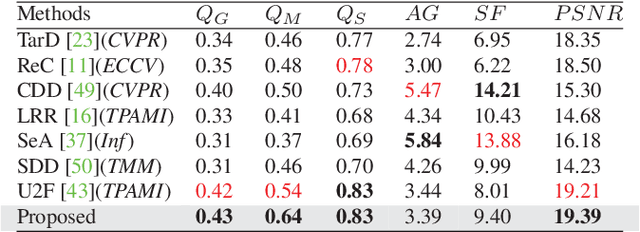
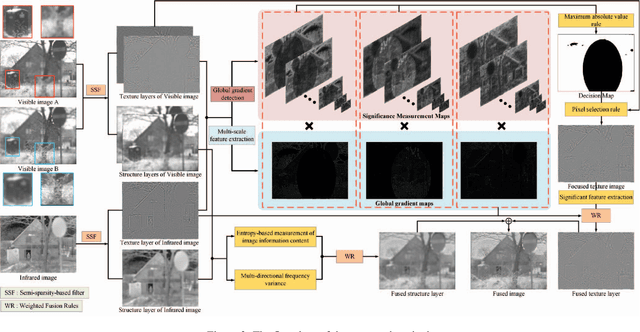
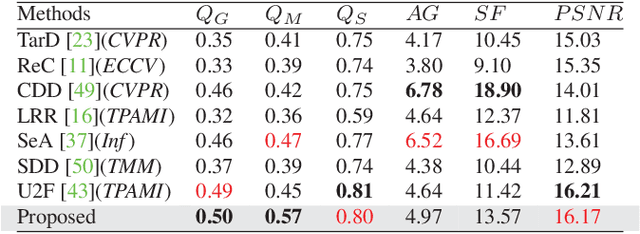
Multi-modal image fusion (MMIF) integrates valuable information from different modality images into a fused one. However, the fusion of multiple visible images with different focal regions and infrared images is a unprecedented challenge in real MMIF applications. This is because of the limited depth of the focus of visible optical lenses, which impedes the simultaneous capture of the focal information within the same scene. To address this issue, in this paper, we propose a MMIF framework for joint focused integration and modalities information extraction. Specifically, a semi-sparsity-based smoothing filter is introduced to decompose the images into structure and texture components. Subsequently, a novel multi-scale operator is proposed to fuse the texture components, capable of detecting significant information by considering the pixel focus attributes and relevant data from various modal images. Additionally, to achieve an effective capture of scene luminance and reasonable contrast maintenance, we consider the distribution of energy information in the structural components in terms of multi-directional frequency variance and information entropy. Extensive experiments on existing MMIF datasets, as well as the object detection and depth estimation tasks, consistently demonstrate that the proposed algorithm can surpass the state-of-the-art methods in visual perception and quantitative evaluation. The code is available at https://github.com/ixilai/MFIF-MMIF.