 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFS-Diff: Semantic guidance and clarity-aware simultaneous multimodal image fusion and super-resolution
Sep 11, 2025As an influential information fusion and low-level vision technique, image fusion integrates complementary information from source images to yield an informative fused image. A few attempts have been made in recent years to jointly realize image fusion and super-resolution. However, in real-world applications such as military reconnaissance and long-range detection missions, the target and background structures in multimodal images are easily corrupted, with low resolution and weak semantic information, which leads to suboptimal results in current fusion techniques. In response, we propose FS-Diff, a semantic guidance and clarity-aware joint image fusion and super-resolution method. FS-Diff unifies image fusion and super-resolution as a conditional generation problem. It leverages semantic guidance from the proposed clarity sensing mechanism for adaptive low-resolution perception and cross-modal feature extraction. Specifically, we initialize the desired fused result as pure Gaussian noise and introduce the bidirectional feature Mamba to extract the global features of the multimodal images. Moreover, utilizing the source images and semantics as conditions, we implement a random iterative denoising process via a modified U-Net network. This network istrained for denoising at multiple noise levels to produce high-resolution fusion results with cross-modal features and abundant semantic information. We also construct a powerful aerial view multiscene (AVMS) benchmark covering 600 pairs of images. Extensive joint image fusion and super-resolution experiments on six public and our AVMS datasets demonstrated that FS-Diff outperforms the state-of-the-art methods at multiple magnifications and can recover richer details and semantics in the fused images. The code is available at https://github.com/XylonXu01/FS-Diff.
Detector-in-Detector: Multi-Level Analysis for Human-Parts
Feb 19, 2019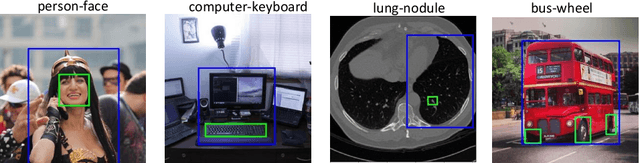
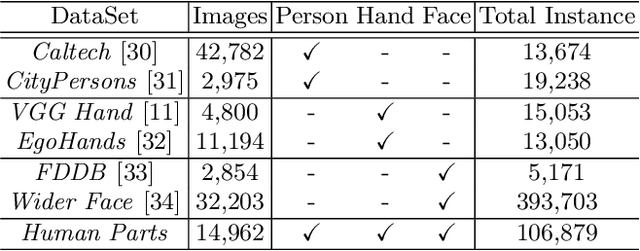
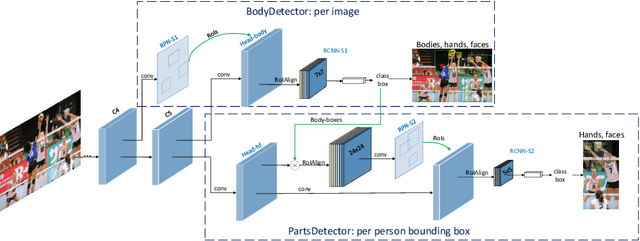

Vision-based person, hand or face detection approaches have achieved incredible success in recent years with the development of deep convolutional neural network (CNN). In this paper, we take the inherent correlation between the body and body parts into account and propose a new framework to boost up the detection performance of the multi-level objects. In particular, we adopt a region-based object detection structure with two carefully designed detectors to separately pay attention to the human body and body parts in a coarse-to-fine manner, which we call Detector-in-Detector network (DID-Net). The first detector is designed to detect human body, hand, and face. The second detector, based on the body detection results of the first detector, mainly focus on the detection of small hand and face inside each body. The framework is trained in an end-to-end way by optimizing a multi-task loss. Due to the lack of human body, face and hand detection dataset, we have collected and labeled a new large dataset named Human-Parts with 14,962 images and 106,879 annotations. Experiments show that our method can achieve excellent performance on Human-Parts.
FSSD: Feature Fusion Single Shot Multibox Detector
May 17, 2018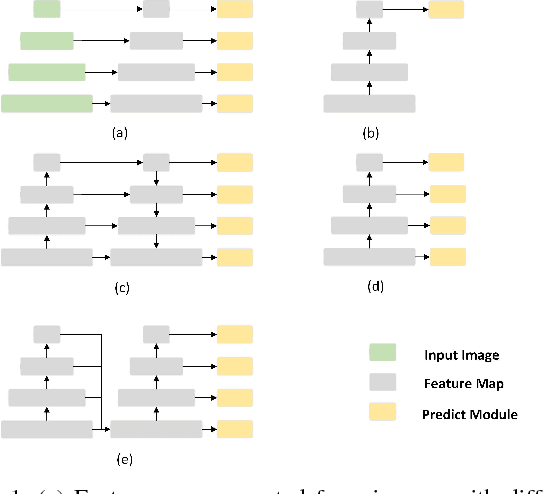

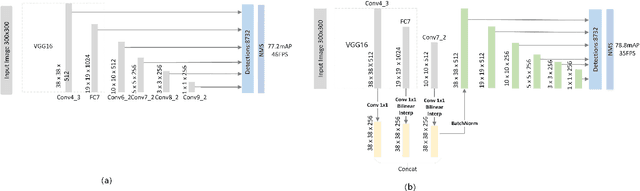
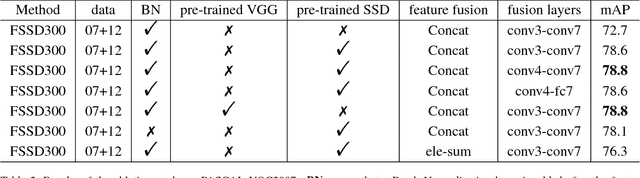
SSD (Single Shot Multibox Detector) is one of the best object detection algorithms with both high accuracy and fast speed. However, SSD's feature pyramid detection method makes it hard to fuse the features from different scales. In this paper, we proposed FSSD (Feature Fusion Single Shot Multibox Detector), an enhanced SSD with a novel and lightweight feature fusion module which can improve the performance significantly over SSD with just a little speed drop. In the feature fusion module, features from different layers with different scales are concatenated together, followed by some down-sampling blocks to generate new feature pyramid, which will be fed to multibox detectors to predict the final detection results. On the Pascal VOC 2007 test, our network can achieve 82.7 mAP (mean average precision) at the speed of 65.8 FPS (frame per second) with the input size 300$\times$300 using a single Nvidia 1080Ti GPU. In addition, our result on COCO is also better than the conventional SSD with a large margin. Our FSSD outperforms a lot of state-of-the-art object detection algorithms in both aspects of accuracy and speed. Code is available at https://github.com/lzx1413/CAFFE_SSD/tree/fssd.