 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeleWorld: Towards Dynamic Multimodal Synthesis with a 4D World Model
Dec 31, 2025World models aim to endow AI systems with the ability to represent, generate, and interact with dynamic environments in a coherent and temporally consistent manner. While recent video generation models have demonstrated impressive visual quality, they remain limited in real-time interaction, long-horizon consistency, and persistent memory of dynamic scenes, hindering their evolution into practical world models. In this report, we present TeleWorld, a real-time multimodal 4D world modeling framework that unifies video generation, dynamic scene reconstruction, and long-term world memory within a closed-loop system. TeleWorld introduces a novel generation-reconstruction-guidance paradigm, where generated video streams are continuously reconstructed into a dynamic 4D spatio-temporal representation, which in turn guides subsequent generation to maintain spatial, temporal, and physical consistency. To support long-horizon generation with low latency, we employ an autoregressive diffusion-based video model enhanced with Macro-from-Micro Planning (MMPL)--a hierarchical planning method that reduces error accumulation from frame-level to segment-level-alongside efficient Distribution Matching Distillation (DMD), enabling real-time synthesis under practical computational budgets. Our approach achieves seamless integration of dynamic object modeling and static scene representation within a unified 4D framework, advancing world models toward practical, interactive, and computationally accessible systems. Extensive experiments demonstrate that TeleWorld achieves strong performance in both static and dynamic world understanding, long-term consistency, and real-time generation efficiency, positioning it as a practical step toward interactive, memory-enabled world models for multimodal generation and embodied intelligence.
State-Aware Tracker for Real-Time Video Object Segmentation
Mar 01, 2020

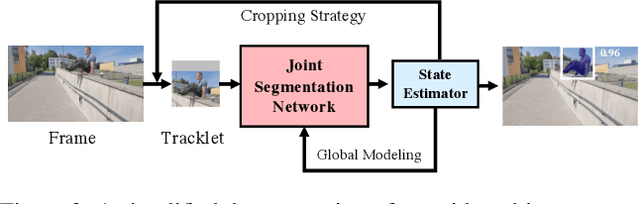

In this work, we address the task of semi-supervised video object segmentation(VOS) and explore how to make efficient use of video property to tackle the challenge of semi-supervision. We propose a novel pipeline called State-Aware Tracker(SAT), which can produce accurate segmentation results with real-time speed. For higher efficiency, SAT takes advantage of the inter-frame consistency and deals with each target object as a tracklet. For more stable and robust performance over video sequences, SAT gets awareness for each state and makes self-adaptation via two feedback loops. One loop assists SAT in generating more stable tracklets. The other loop helps to construct a more robust and holistic target representation. SAT achieves a promising result of 72.3% J&F mean with 39 FPS on DAVIS2017-Val dataset, which shows a decent trade-off between efficiency and accuracy. Code will be released at github.com/MegviiDetection/video_analyst.
SiamFC++: Towards Robust and Accurate Visual Tracking with Target Estimation Guidelines
Jan 02, 2020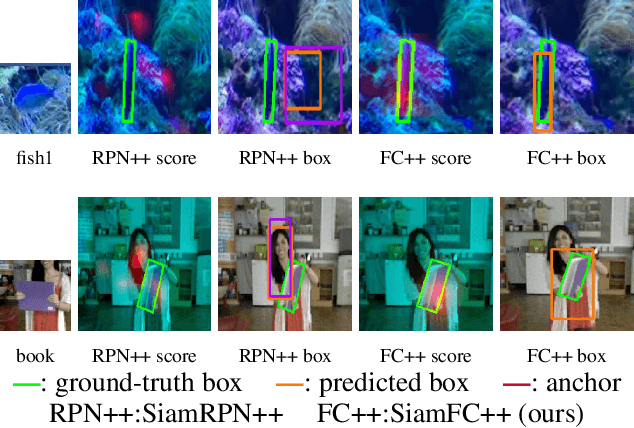

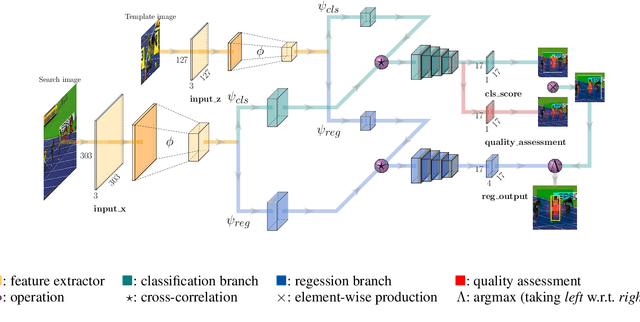
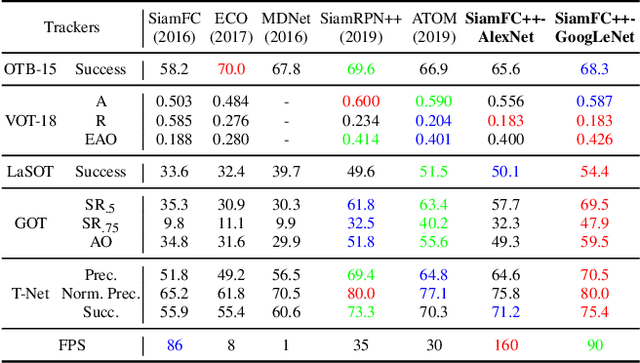
Visual tracking problem demands to efficiently perform robust classification and accurate target state estimation over a given target at the same time. Former methods have proposed various ways of target state estimation, yet few of them took the particularity of the visual tracking problem itself into consideration. After a careful analysis, we propose a set of practical guidelines of target state estimation for high-performance generic object tracker design. Following these guidelines, we design our Fully Convolutional Siamese tracker++ (SiamFC++) by introducing both classification and target state estimation branch(G1), classification score without ambiguity(G2), tracking without prior knowledge(G3), and estimation quality score(G4). Extensive analysis and ablation studies demonstrate the effectiveness of our proposed guidelines. Without bells and whistles, our SiamFC++ tracker achieves state-of-the-art performance on five challenging benchmarks(OTB2015, VOT2018, LaSOT, GOT-10k, TrackingNet), which proves both the tracking and generalization ability of the tracker. Particularly, on the large-scale TrackingNet dataset, SiamFC++ achieves a previously unseen AUC score of 75.4 while running at over 90 FPS, which is far above the real-time requirement. Code and models are available at: https://github.com/MegviiDetection/video_analyst .
WIDER Face and Pedestrian Challenge 2018: Methods and Results
Feb 19, 2019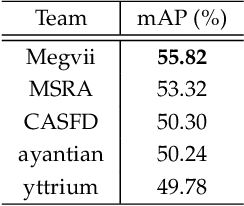

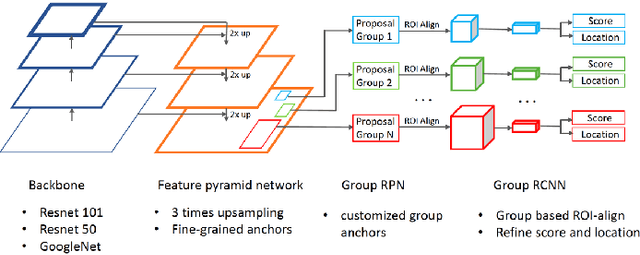
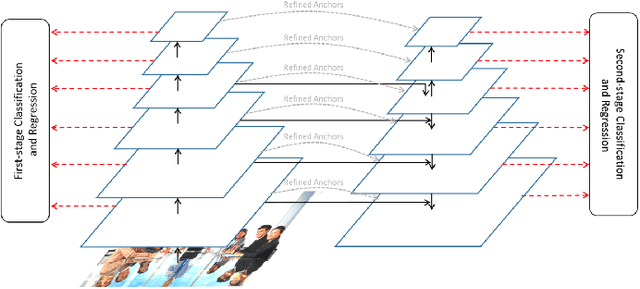
This paper presents a review of the 2018 WIDER Challenge on Face and Pedestrian. The challenge focuses on the problem of precise localization of human faces and bodies, and accurate association of identities. It comprises of three tracks: (i) WIDER Face which aims at soliciting new approaches to advance the state-of-the-art in face detection, (ii) WIDER Pedestrian which aims to find effective and efficient approaches to address the problem of pedestrian detection in unconstrained environments, and (iii) WIDER Person Search which presents an exciting challenge of searching persons across 192 movies. In total, 73 teams made valid submissions to the challenge tracks. We summarize the winning solutions for all three tracks. and present discussions on open problems and potential research directions in these topics.
FSSD: Feature Fusion Single Shot Multibox Detector
May 17, 2018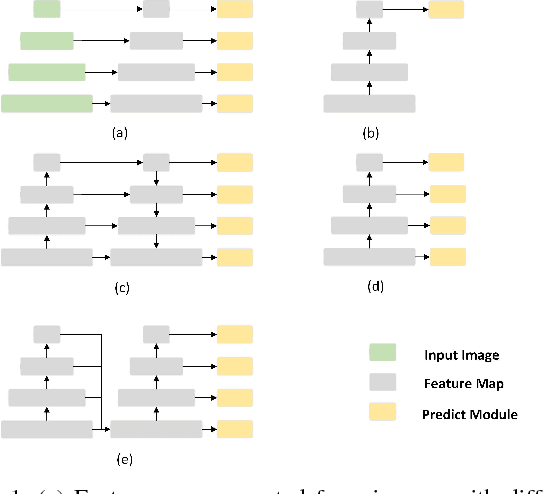

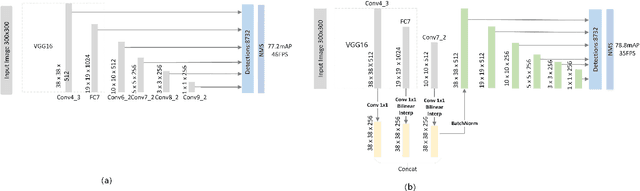
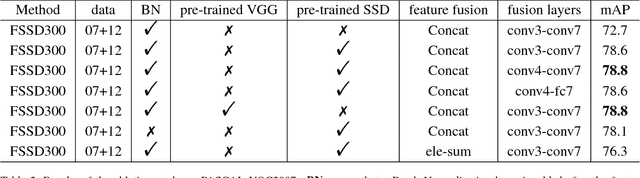
SSD (Single Shot Multibox Detector) is one of the best object detection algorithms with both high accuracy and fast speed. However, SSD's feature pyramid detection method makes it hard to fuse the features from different scales. In this paper, we proposed FSSD (Feature Fusion Single Shot Multibox Detector), an enhanced SSD with a novel and lightweight feature fusion module which can improve the performance significantly over SSD with just a little speed drop. In the feature fusion module, features from different layers with different scales are concatenated together, followed by some down-sampling blocks to generate new feature pyramid, which will be fed to multibox detectors to predict the final detection results. On the Pascal VOC 2007 test, our network can achieve 82.7 mAP (mean average precision) at the speed of 65.8 FPS (frame per second) with the input size 300$\times$300 using a single Nvidia 1080Ti GPU. In addition, our result on COCO is also better than the conventional SSD with a large margin. Our FSSD outperforms a lot of state-of-the-art object detection algorithms in both aspects of accuracy and speed. Code is available at https://github.com/lzx1413/CAFFE_SSD/tree/fssd.