 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCTracks: An Open Dataset for Machine Learning-Based Drift Chamber Track Reconstruction
Feb 16, 2026We introduce a Monte Carlo (MC) dataset of single- and two-track drift chamber events to advance Machine Learning (ML)-based track reconstruction. To enable standardized and comparable evaluation, we define track reconstruction specific metrics and report results for traditional track reconstruction algorithms and a Graph Neural Networks (GNNs) method, facilitating rigorous, reproducible validation for future research.
Fast Latent Factor Analysis via a Fuzzy PID-Incorporated Stochastic Gradient Descent Algorithm
Mar 07, 2023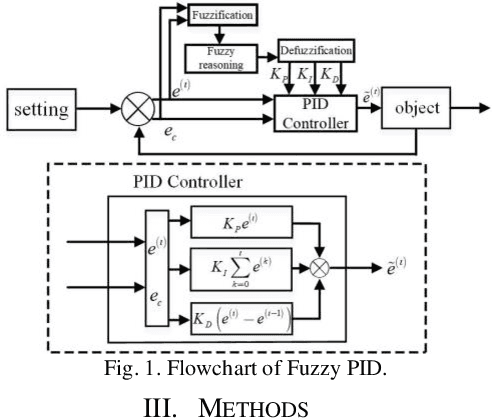

A high-dimensional and incomplete (HDI) matrix can describe the complex interactions among numerous nodes in various big data-related applications. A stochastic gradient descent (SGD)-based latent factor analysis (LFA) model is remarkably effective in extracting valuable information from an HDI matrix. However, such a model commonly encounters the problem of slow convergence because a standard SGD algorithm learns a latent factor relying on the stochastic gradient of current instance error only without considering past update information. To address this critical issue, this paper innovatively proposes a Fuzzy PID-incorporated SGD (FPS) algorithm with two-fold ideas: 1) rebuilding the instance learning error by considering the past update information in an efficient way following the principle of PID, and 2) implementing hyper-parameters and gain parameters adaptation following the fuzzy rules. With it, an FPS-incorporated LFA model is further achieved for fast processing an HDI matrix. Empirical studies on six HDI datasets demonstrate that the proposed FPS-incorporated LFA model significantly outperforms the state-of-the-art LFA models in terms of computational efficiency for predicting the missing data of an HDI matrix with competitive accuracy.
Graph Regularized Nonnegative Latent Factor Analysis Model for Temporal Link Prediction in Cryptocurrency Transaction Networks
Aug 03, 2022

With the development of blockchain technology, the cryptocurrency based on blockchain technology is becoming more and more popular. This gave birth to a huge cryptocurrency transaction network has received widespread attention. Link prediction learning structure of network is helpful to understand the mechanism of network, so it is also widely studied in cryptocurrency network. However, the dynamics of cryptocurrency transaction networks have been neglected in the past researches. We use graph regularized method to link past transaction records with future transactions. Based on this, we propose a single latent factor-dependent, non-negative, multiplicative and graph regularized-incorporated update (SLF-NMGRU) algorithm and further propose graph regularized nonnegative latent factor analysis (GrNLFA) model. Finally, experiments on a real cryptocurrency transaction network show that the proposed method improves both the accuracy and the computational efficiency
Does Recommend-Revise Produce Reliable Annotations? An Analysis on Missing Instances in DocRED
Apr 17, 2022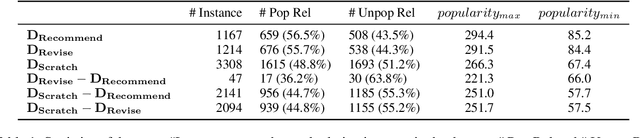
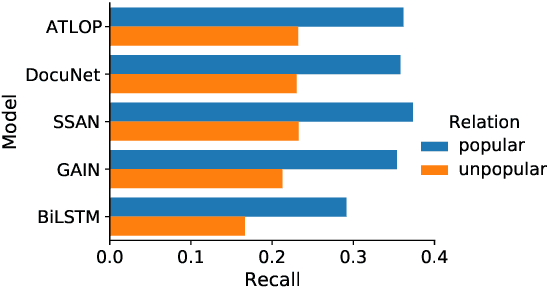
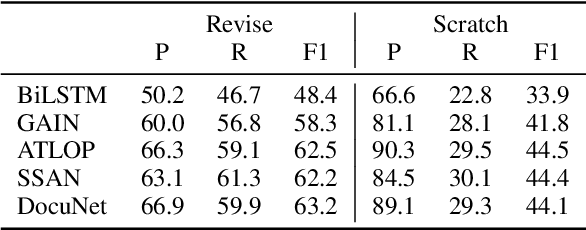
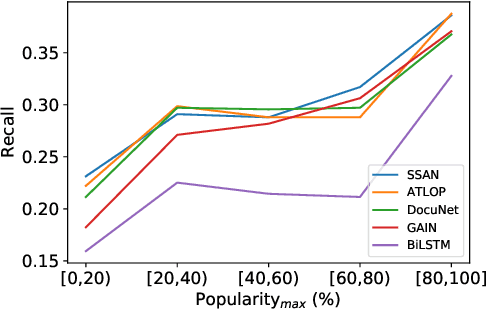
DocRED is a widely used dataset for document-level relation extraction. In the large-scale annotation, a \textit{recommend-revise} scheme is adopted to reduce the workload. Within this scheme, annotators are provided with candidate relation instances from distant supervision, and they then manually supplement and remove relational facts based on the recommendations. However, when comparing DocRED with a subset relabeled from scratch, we find that this scheme results in a considerable amount of false negative samples and an obvious bias towards popular entities and relations. Furthermore, we observe that the models trained on DocRED have low recall on our relabeled dataset and inherit the same bias in the training data. Through the analysis of annotators' behaviors, we figure out the underlying reason for the problems above: the scheme actually discourages annotators from supplementing adequate instances in the revision phase. We appeal to future research to take into consideration the issues with the recommend-revise scheme when designing new models and annotation schemes. The relabeled dataset is released at \url{https://github.com/AndrewZhe/Revisit-DocRED}, to serve as a more reliable test set of document RE models.
Three Sentences Are All You Need: Local Path Enhanced Document Relation Extraction
Jun 03, 2021
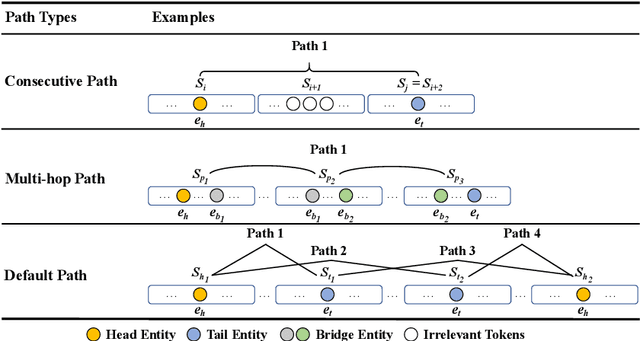
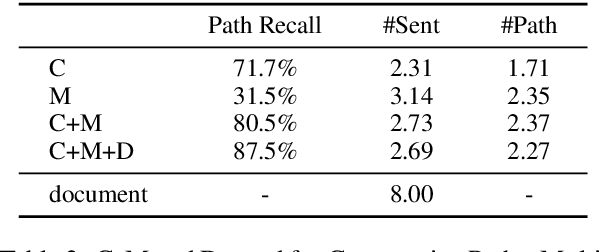
Document-level Relation Extraction (RE) is a more challenging task than sentence RE as it often requires reasoning over multiple sentences. Yet, human annotators usually use a small number of sentences to identify the relationship between a given entity pair. In this paper, we present an embarrassingly simple but effective method to heuristically select evidence sentences for document-level RE, which can be easily combined with BiLSTM to achieve good performance on benchmark datasets, even better than fancy graph neural network based methods. We have released our code at https://github.com/AndrewZhe/Three-Sentences-Are-All-You-Need.
SiamFC++: Towards Robust and Accurate Visual Tracking with Target Estimation Guidelines
Jan 02, 2020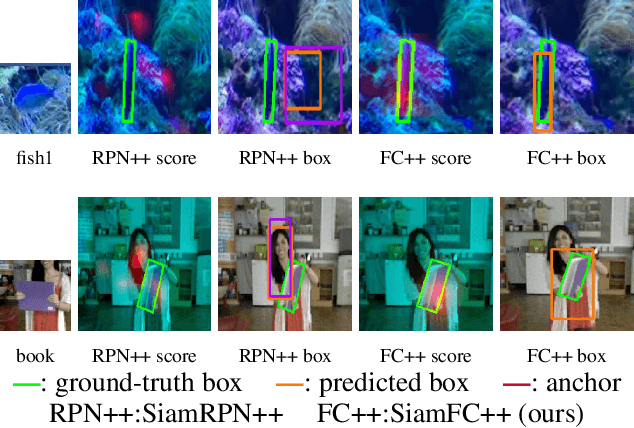

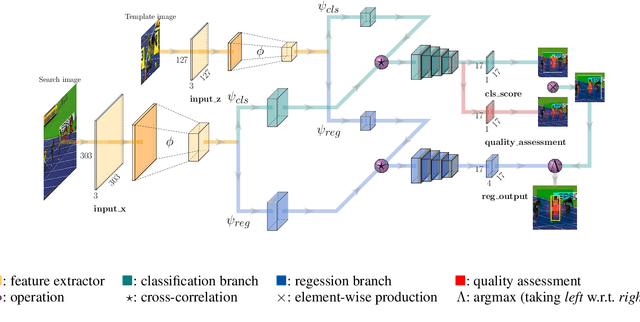
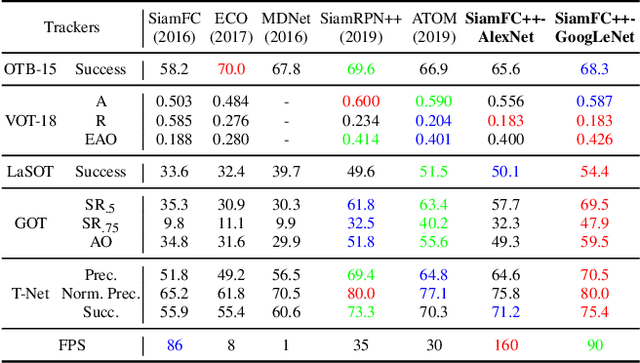
Visual tracking problem demands to efficiently perform robust classification and accurate target state estimation over a given target at the same time. Former methods have proposed various ways of target state estimation, yet few of them took the particularity of the visual tracking problem itself into consideration. After a careful analysis, we propose a set of practical guidelines of target state estimation for high-performance generic object tracker design. Following these guidelines, we design our Fully Convolutional Siamese tracker++ (SiamFC++) by introducing both classification and target state estimation branch(G1), classification score without ambiguity(G2), tracking without prior knowledge(G3), and estimation quality score(G4). Extensive analysis and ablation studies demonstrate the effectiveness of our proposed guidelines. Without bells and whistles, our SiamFC++ tracker achieves state-of-the-art performance on five challenging benchmarks(OTB2015, VOT2018, LaSOT, GOT-10k, TrackingNet), which proves both the tracking and generalization ability of the tracker. Particularly, on the large-scale TrackingNet dataset, SiamFC++ achieves a previously unseen AUC score of 75.4 while running at over 90 FPS, which is far above the real-time requirement. Code and models are available at: https://github.com/MegviiDetection/video_analyst .
Integrating Relation Constraints with Neural Relation Extractors
Nov 26, 2019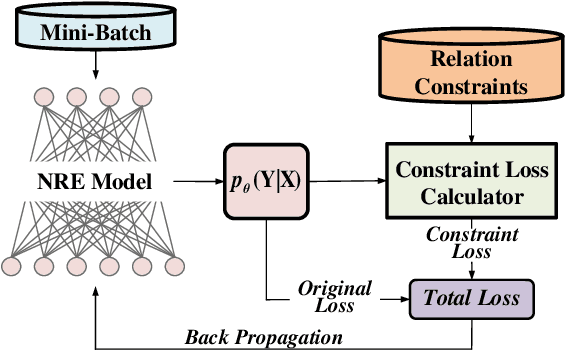

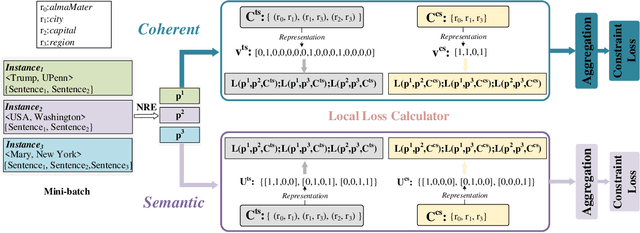
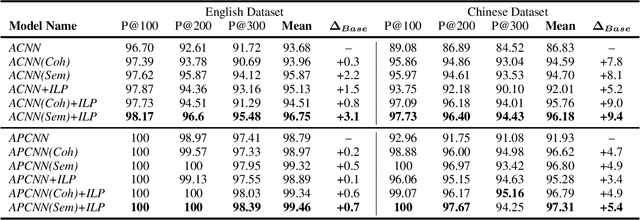
Recent years have seen rapid progress in identifying predefined relationship between entity pairs using neural networks NNs. However, such models often make predictions for each entity pair individually, thus often fail to solve the inconsistency among different predictions, which can be characterized by discrete relation constraints. These constraints are often defined over combinations of entity-relation-entity triples, since there often lack of explicitly well-defined type and cardinality requirements for the relations. In this paper, we propose a unified framework to integrate relation constraints with NNs by introducing a new loss term, ConstraintLoss. Particularly, we develop two efficient methods to capture how well the local predictions from multiple instance pairs satisfy the relation constraints. Experiments on both English and Chinese datasets show that our approach can help NNs learn from discrete relation constraints to reduce inconsistency among local predictions, and outperform popular neural relation extraction NRE models even enhanced with extra post-processing. Our source code and datasets will be released at https://github.com/PKUYeYuan/Constraint-Loss-AAAI-2020.
Analysis of Bag-of-n-grams Representation's Properties Based on Textual Reconstruction
Sep 18, 2018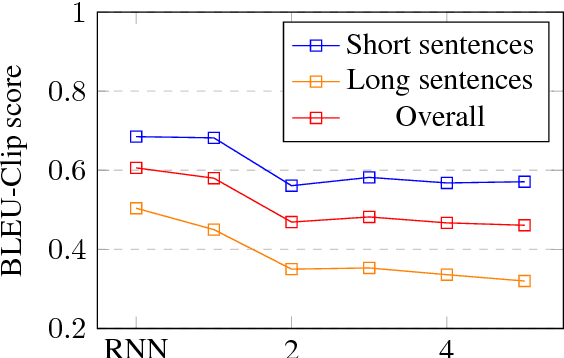
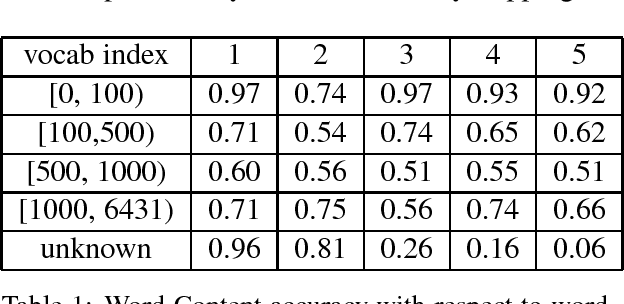
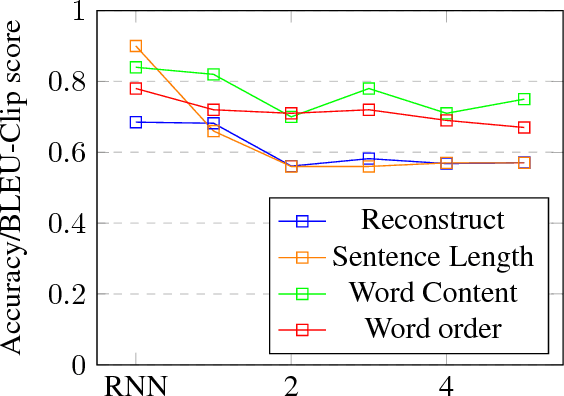
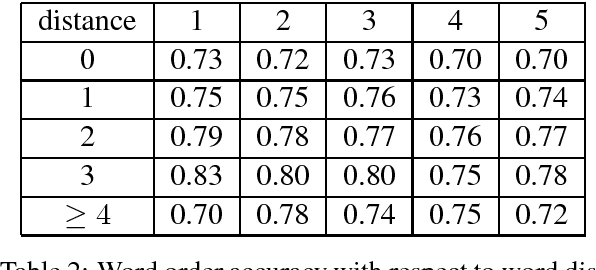
Despite its simplicity, bag-of-n-grams sen- tence representation has been found to excel in some NLP tasks. However, it has not re- ceived much attention in recent years and fur- ther analysis on its properties is necessary. We propose a framework to investigate the amount and type of information captured in a general- purposed bag-of-n-grams sentence represen- tation. We first use sentence reconstruction as a tool to obtain bag-of-n-grams representa- tion that contains general information of the sentence. We then run prediction tasks (sen- tence length, word content, phrase content and word order) using the obtained representation to look into the specific type of information captured in the representation. Our analysis demonstrates that bag-of-n-grams representa- tion does contain sentence structure level in- formation. However, incorporating n-grams with higher order n empirically helps little with encoding more information in general, except for phrase content information.