 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNASE: Learning Knowledge Graph Embedding for Link Prediction via Neural Architecture Search
Aug 18, 2020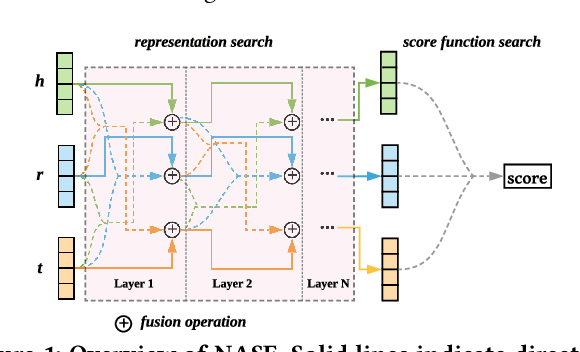
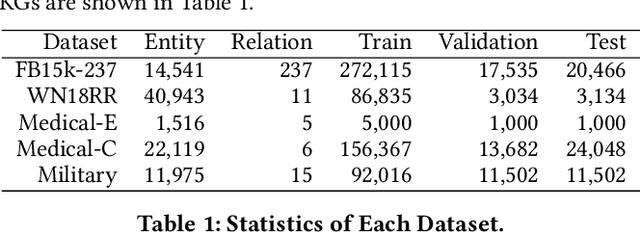
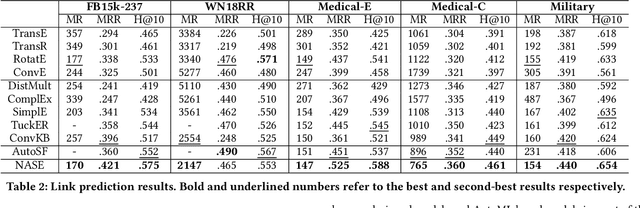

Link prediction is the task of predicting missing connections between entities in the knowledge graph (KG). While various forms of models are proposed for the link prediction task, most of them are designed based on a few known relation patterns in several well-known datasets. Due to the diversity and complexity nature of the real-world KGs, it is inherently difficult to design a model that fits all datasets well. To address this issue, previous work has tried to use Automated Machine Learning (AutoML) to search for the best model for a given dataset. However, their search space is limited only to bilinear model families. In this paper, we propose a novel Neural Architecture Search (NAS) framework for the link prediction task. First, the embeddings of the input triplet are refined by the Representation Search Module. Then, the prediction score is searched within the Score Function Search Module. This framework entails a more general search space, which enables us to take advantage of several mainstream model families, and thus it can potentially achieve better performance. We relax the search space to be continuous so that the architecture can be optimized efficiently using gradient-based search strategies. Experimental results on several benchmark datasets demonstrate the effectiveness of our method compared with several state-of-the-art approaches.
Integrating Relation Constraints with Neural Relation Extractors
Nov 26, 2019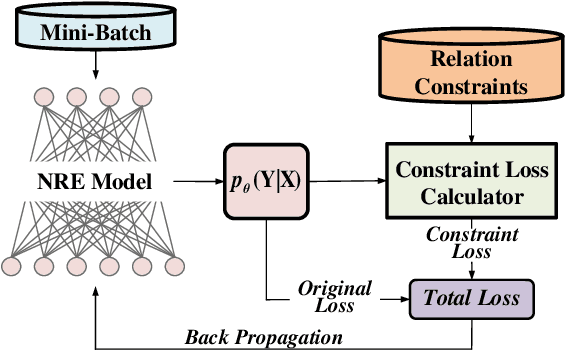

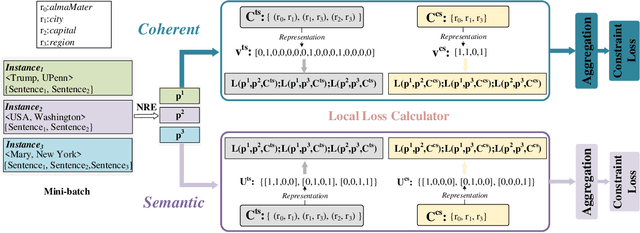
Recent years have seen rapid progress in identifying predefined relationship between entity pairs using neural networks NNs. However, such models often make predictions for each entity pair individually, thus often fail to solve the inconsistency among different predictions, which can be characterized by discrete relation constraints. These constraints are often defined over combinations of entity-relation-entity triples, since there often lack of explicitly well-defined type and cardinality requirements for the relations. In this paper, we propose a unified framework to integrate relation constraints with NNs by introducing a new loss term, ConstraintLoss. Particularly, we develop two efficient methods to capture how well the local predictions from multiple instance pairs satisfy the relation constraints. Experiments on both English and Chinese datasets show that our approach can help NNs learn from discrete relation constraints to reduce inconsistency among local predictions, and outperform popular neural relation extraction NRE models even enhanced with extra post-processing. Our source code and datasets will be released at https://github.com/PKUYeYuan/Constraint-Loss-AAAI-2020.
Encoding Implicit Relation Requirements for Relation Extraction: A Joint Inference Approach
Nov 09, 2018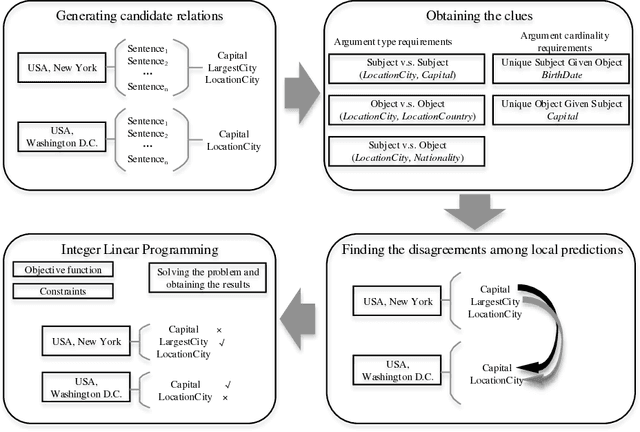
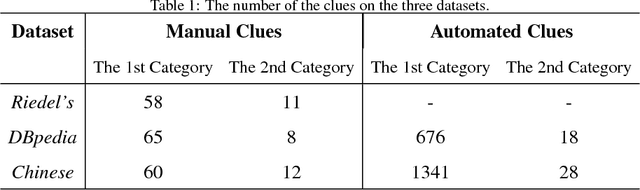
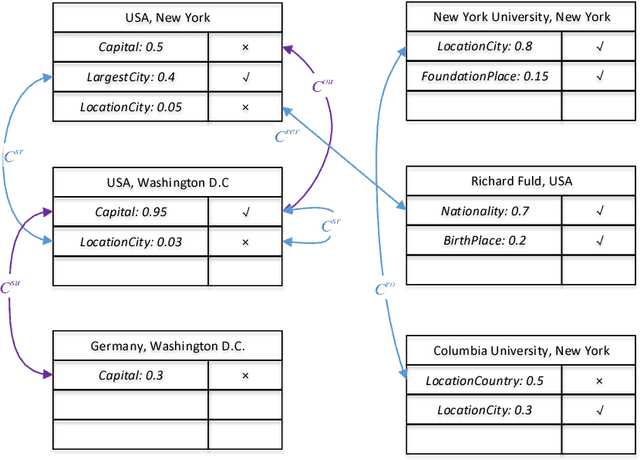

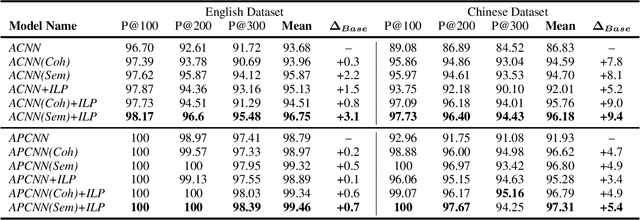
Relation extraction is the task of identifying predefined relationship between entities, and plays an essential role in information extraction, knowledge base construction, question answering and so on. Most existing relation extractors make predictions for each entity pair locally and individually, while ignoring implicit global clues available across different entity pairs and in the knowledge base, which often leads to conflicts among local predictions from different entity pairs. This paper proposes a joint inference framework that employs such global clues to resolve disagreements among local predictions. We exploit two kinds of clues to generate constraints which can capture the implicit type and cardinality requirements of a relation. Those constraints can be examined in either hard style or soft style, both of which can be effectively explored in an integer linear program formulation. Experimental results on both English and Chinese datasets show that our proposed framework can effectively utilize those two categories of global clues and resolve the disagreements among local predictions, thus improve various relation extractors when such clues are applicable to the datasets. Our experiments also indicate that the clues learnt automatically from existing knowledge bases perform comparably to or better than those refined by human.
* to appear in Artificial Intelligence
Playing 20 Question Game with Policy-Based Reinforcement Learning
Aug 26, 2018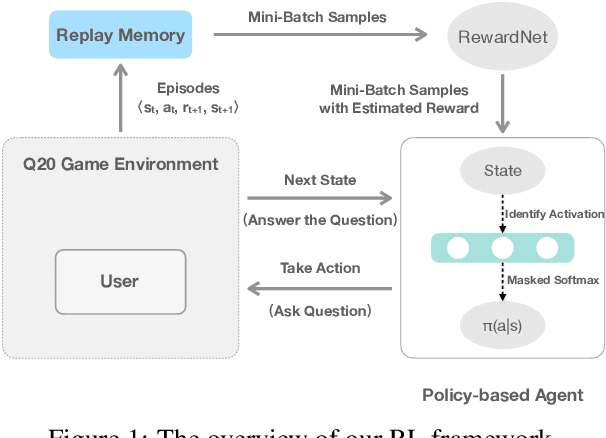

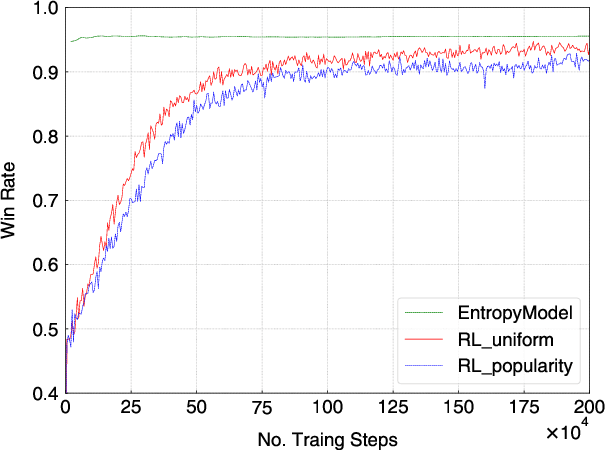
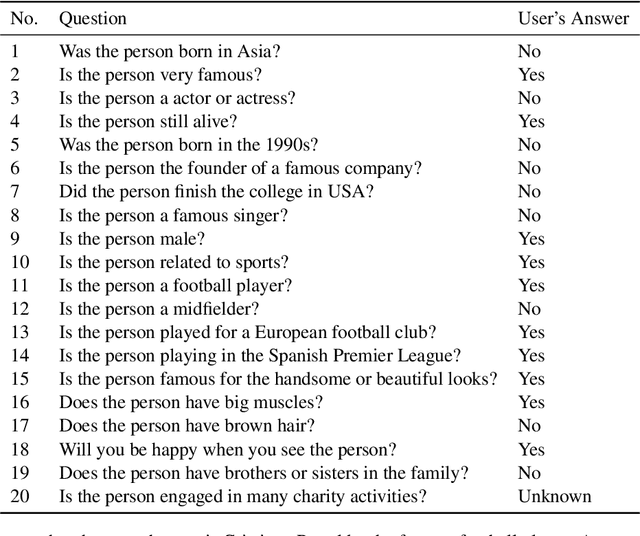
The 20 Questions (Q20) game is a well known game which encourages deductive reasoning and creativity. In the game, the answerer first thinks of an object such as a famous person or a kind of animal. Then the questioner tries to guess the object by asking 20 questions. In a Q20 game system, the user is considered as the answerer while the system itself acts as the questioner which requires a good strategy of question selection to figure out the correct object and win the game. However, the optimal policy of question selection is hard to be derived due to the complexity and volatility of the game environment. In this paper, we propose a novel policy-based Reinforcement Learning (RL) method, which enables the questioner agent to learn the optimal policy of question selection through continuous interactions with users. To facilitate training, we also propose to use a reward network to estimate the more informative reward. Compared to previous methods, our RL method is robust to noisy answers and does not rely on the Knowledge Base of objects. Experimental results show that our RL method clearly outperforms an entropy-based engineering system and has competitive performance in a noisy-free simulation environment.
Marrying up Regular Expressions with Neural Networks: A Case Study for Spoken Language Understanding
May 15, 2018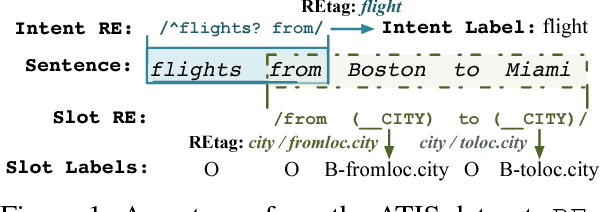
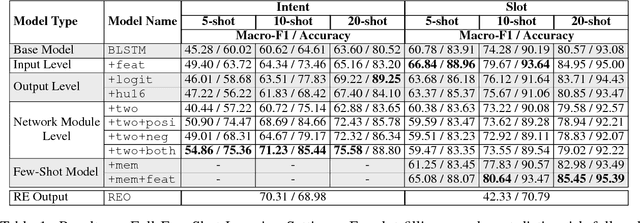
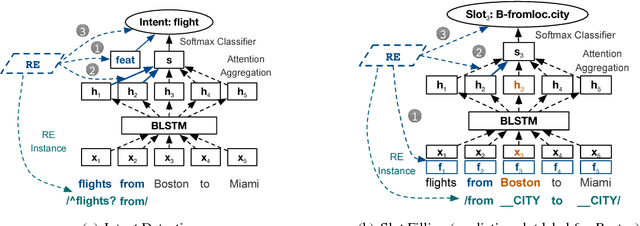
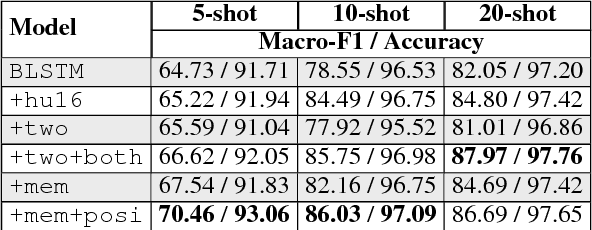
The success of many natural language processing (NLP) tasks is bound by the number and quality of annotated data, but there is often a shortage of such training data. In this paper, we ask the question: "Can we combine a neural network (NN) with regular expressions (RE) to improve supervised learning for NLP?". In answer, we develop novel methods to exploit the rich expressiveness of REs at different levels within a NN, showing that the combination significantly enhances the learning effectiveness when a small number of training examples are available. We evaluate our approach by applying it to spoken language understanding for intent detection and slot filling. Experimental results show that our approach is highly effective in exploiting the available training data, giving a clear boost to the RE-unaware NN.
Learning to Predict Charges for Criminal Cases with Legal Basis
Jul 28, 2017
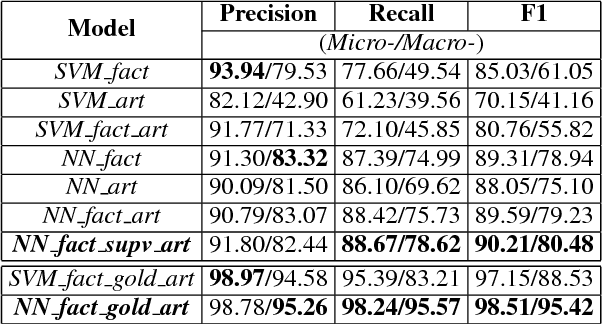
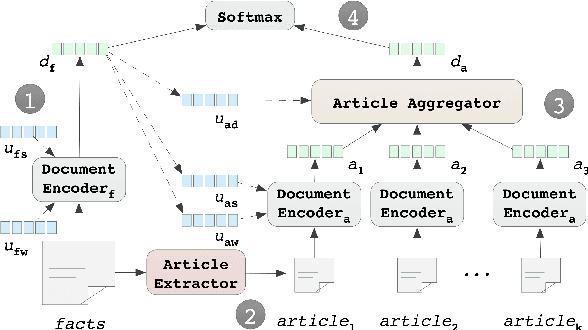
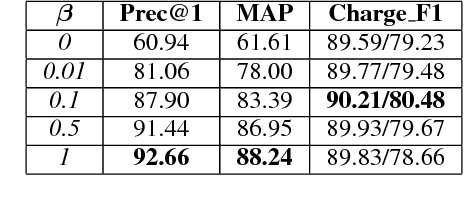
The charge prediction task is to determine appropriate charges for a given case, which is helpful for legal assistant systems where the user input is fact description. We argue that relevant law articles play an important role in this task, and therefore propose an attention-based neural network method to jointly model the charge prediction task and the relevant article extraction task in a unified framework. The experimental results show that, besides providing legal basis, the relevant articles can also clearly improve the charge prediction results, and our full model can effectively predict appropriate charges for cases with different expression styles.
Learning with Noise: Enhance Distantly Supervised Relation Extraction with Dynamic Transition Matrix
May 11, 2017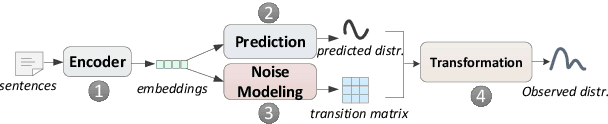
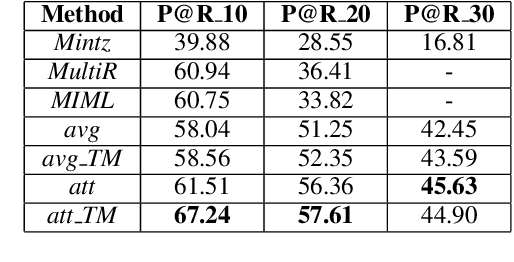
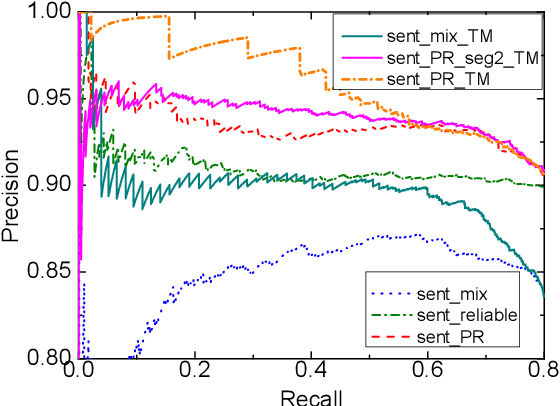
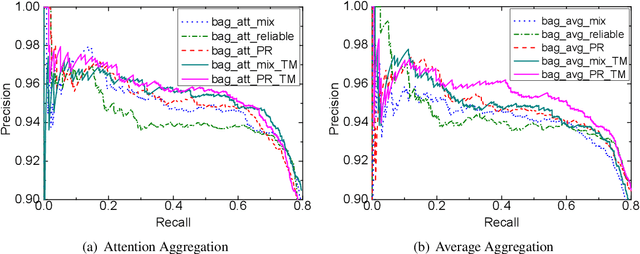
Distant supervision significantly reduces human efforts in building training data for many classification tasks. While promising, this technique often introduces noise to the generated training data, which can severely affect the model performance. In this paper, we take a deep look at the application of distant supervision in relation extraction. We show that the dynamic transition matrix can effectively characterize the noise in the training data built by distant supervision. The transition matrix can be effectively trained using a novel curriculum learning based method without any direct supervision about the noise. We thoroughly evaluate our approach under a wide range of extraction scenarios. Experimental results show that our approach consistently improves the extraction results and outperforms the state-of-the-art in various evaluation scenarios.