 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatQA 2: Bridging the Gap to Proprietary LLMs in Long Context and RAG Capabilities
Jul 19, 2024



In this work, we introduce ChatQA 2, a Llama3-based model designed to bridge the gap between open-access LLMs and leading proprietary models (e.g., GPT-4-Turbo) in long-context understanding and retrieval-augmented generation (RAG) capabilities. These two capabilities are essential for LLMs to process large volumes of information that cannot fit into a single prompt and are complementary to each other, depending on the downstream tasks and computational budgets. We present a detailed continued training recipe to extend the context window of Llama3-70B-base from 8K to 128K tokens, along with a three-stage instruction tuning process to enhance the model's instruction-following, RAG performance, and long-context understanding capabilities. Our results demonstrate that the Llama3-ChatQA-2-70B model achieves accuracy comparable to GPT-4-Turbo-2024-0409 on many long-context understanding tasks and surpasses it on the RAG benchmark. Interestingly, we find that the state-of-the-art long-context retriever can alleviate the top-k context fragmentation issue in RAG, further improving RAG-based results for long-context understanding tasks. We also provide extensive comparisons between RAG and long-context solutions using state-of-the-art long-context LLMs.
SteerLM: Attribute Conditioned SFT as an (User-Steerable) Alternative to RLHF
Oct 09, 2023



Model alignment with human preferences is an essential step in making Large Language Models (LLMs) helpful and consistent with human values. It typically consists of supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF) stages. However, RLHF faces inherent limitations stemming from a complex training setup and its tendency to align the model with implicit values that end users cannot control at run-time. Moreover, reward models in RLHF stage commonly rely on single-dimensional feedback as opposed to explicit, multifaceted signals that indicate attributes such as helpfulness, humor, and toxicity. To address these limitations, we propose SteerLM, a supervised fine-tuning method that empowers end-users to control responses during inference. SteerLM conditions responses to conform to an explicitly defined multi-dimensional set of attributes, thereby empowering a steerable AI capable of generating helpful and high-quality responses while maintaining customizability. Experiments show that SteerLM trained on open source datasets generates responses that are preferred by human and automatic evaluators to many state-of-the-art baselines trained with RLHF while being much easier to train. Try SteerLM at https://huggingface.co/nvidia/SteerLM-llama2-13B
Retrieval meets Long Context Large Language Models
Oct 04, 2023



Extending the context window of large language models (LLMs) is getting popular recently, while the solution of augmenting LLMs with retrieval has existed for years. The natural questions are: i) Retrieval-augmentation versus long context window, which one is better for downstream tasks? ii) Can both methods be combined to get the best of both worlds? In this work, we answer these questions by studying both solutions using two state-of-the-art pretrained LLMs, i.e., a proprietary 43B GPT and LLaMA2-70B. Perhaps surprisingly, we find that LLM with 4K context window using simple retrieval-augmentation at generation can achieve comparable performance to finetuned LLM with 16K context window via positional interpolation on long context tasks, while taking much less computation. More importantly, we demonstrate that retrieval can significantly improve the performance of LLMs regardless of their extended context window sizes. Our best model, retrieval-augmented LLaMA2-70B with 32K context window, outperforms GPT-3.5-turbo-16k and Davinci003 in terms of average score on seven long context tasks including question answering and query-based summarization. It also outperforms its non-retrieval LLaMA2-70B-32k baseline by a margin, while being much faster at generation. Our study provides general insights on the choice of retrieval-augmentation versus long context extension of LLM for practitioners.
Duplex Diffusion Models Improve Speech-to-Speech Translation
May 22, 2023



Speech-to-speech translation is a typical sequence-to-sequence learning task that naturally has two directions. How to effectively leverage bidirectional supervision signals to produce high-fidelity audio for both directions? Existing approaches either train two separate models or a multitask-learned model with low efficiency and inferior performance. In this paper, we propose a duplex diffusion model that applies diffusion probabilistic models to both sides of a reversible duplex Conformer, so that either end can simultaneously input and output a distinct language's speech. Our model enables reversible speech translation by simply flipping the input and output ends. Experiments show that our model achieves the first success of reversible speech translation with significant improvements of ASR-BLEU scores compared with a list of state-of-the-art baselines.
Enhancing Unsupervised Speech Recognition with Diffusion GANs
Mar 23, 2023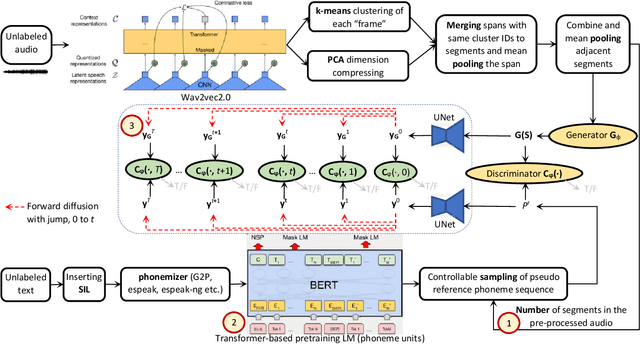
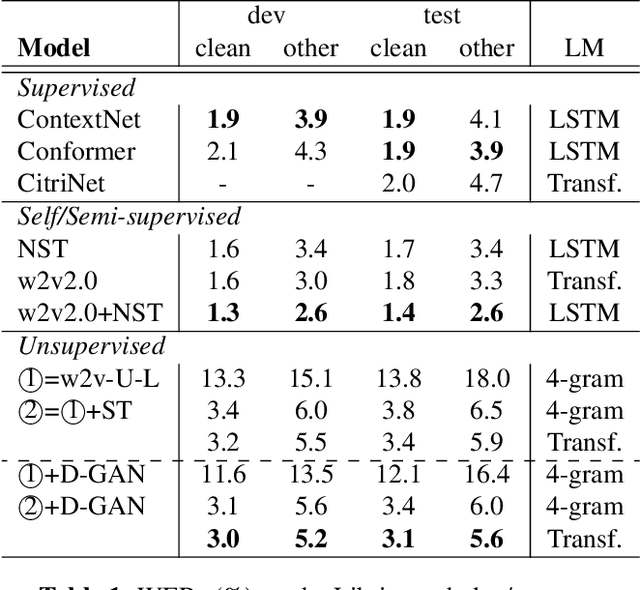
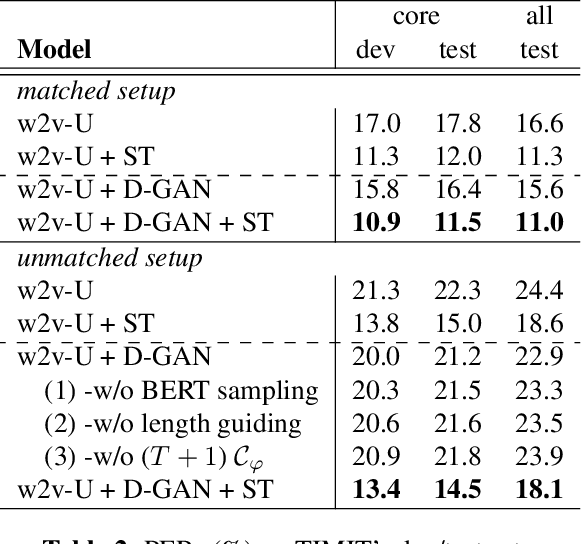
We enhance the vanilla adversarial training method for unsupervised Automatic Speech Recognition (ASR) by a diffusion-GAN. Our model (1) injects instance noises of various intensities to the generator's output and unlabeled reference text which are sampled from pretrained phoneme language models with a length constraint, (2) asks diffusion timestep-dependent discriminators to separate them, and (3) back-propagates the gradients to update the generator. Word/phoneme error rate comparisons with wav2vec-U under Librispeech (3.1% for test-clean and 5.6% for test-other), TIMIT and MLS datasets, show that our enhancement strategies work effectively.
Creative Painting with Latent Diffusion Models
Sep 30, 2022
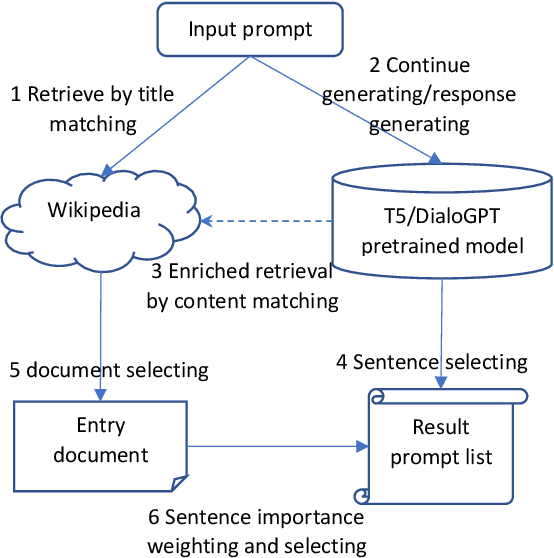
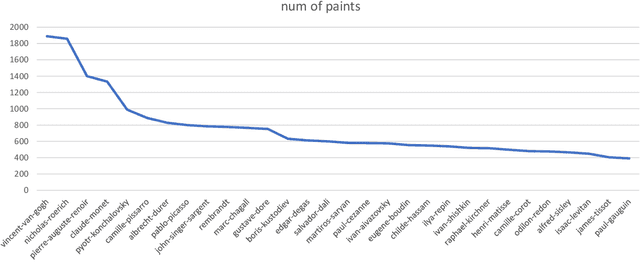
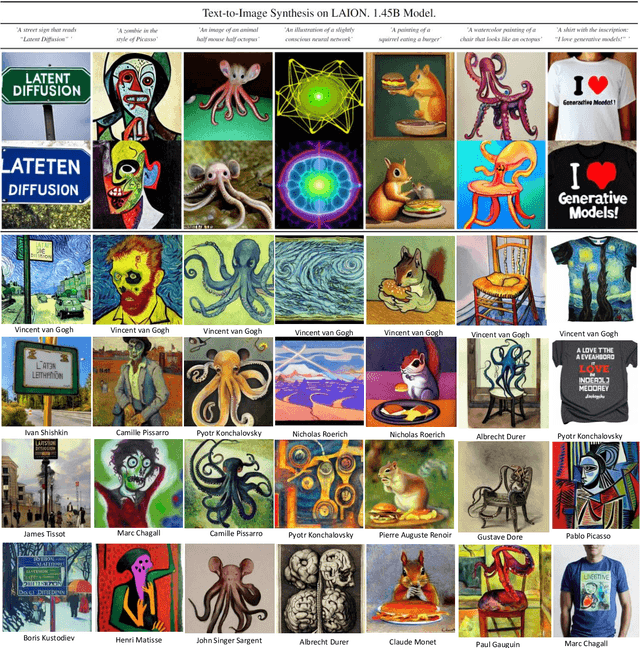
Artistic painting has achieved significant progress during recent years. Using an autoencoder to connect the original images with compressed latent spaces and a cross attention enhanced U-Net as the backbone of diffusion, latent diffusion models (LDMs) have achieved stable and high fertility image generation. In this paper, we focus on enhancing the creative painting ability of current LDMs in two directions, textual condition extension and model retraining with Wikiart dataset. Through textual condition extension, users' input prompts are expanded with rich contextual knowledge for deeper understanding and explaining the prompts. Wikiart dataset contains 80K famous artworks drawn during recent 400 years by more than 1,000 famous artists in rich styles and genres. Through the retraining, we are able to ask these artists to draw novel and creative painting on modern topics. Direct comparisons with the original model show that the creativity and artistry are enriched.
Event-Driven Learning of Systematic Behaviours in Stock Markets
Oct 23, 2020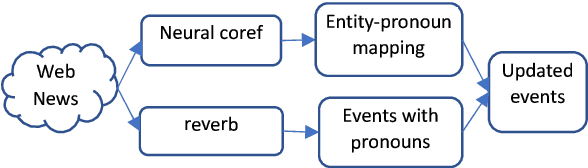
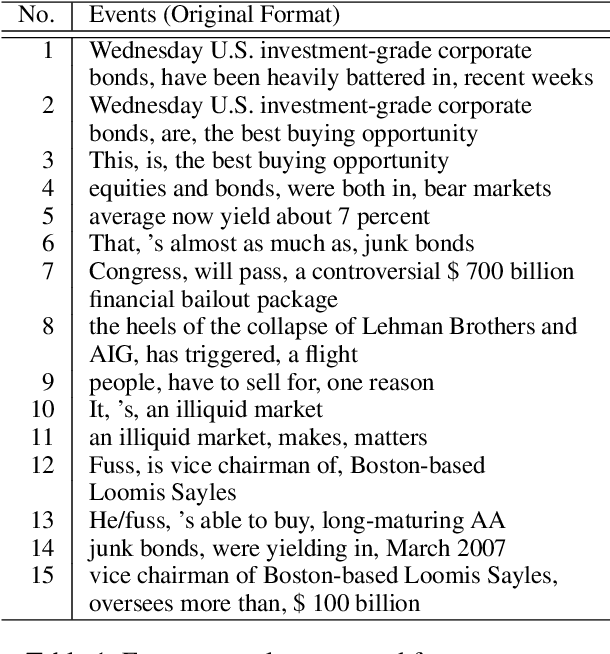
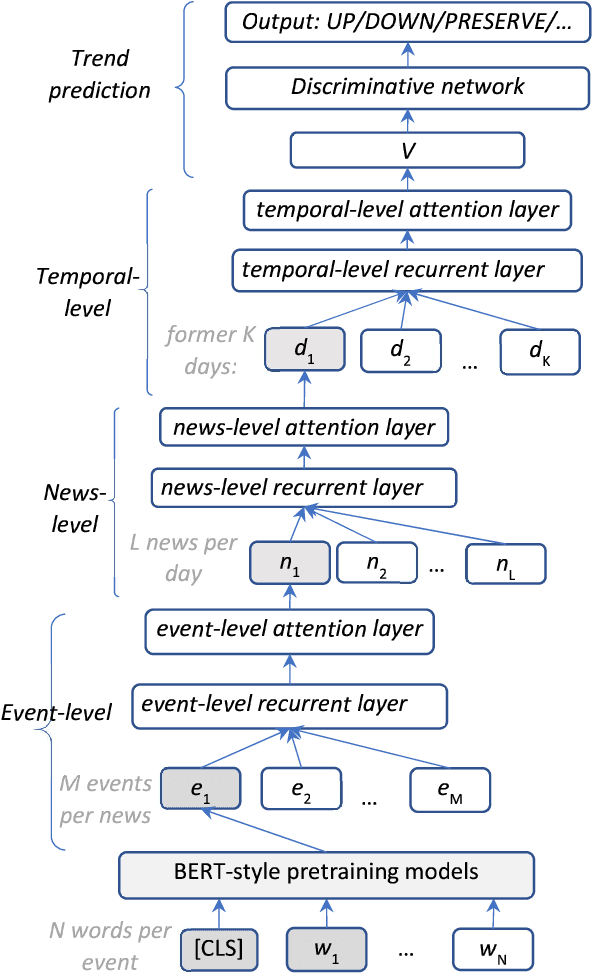
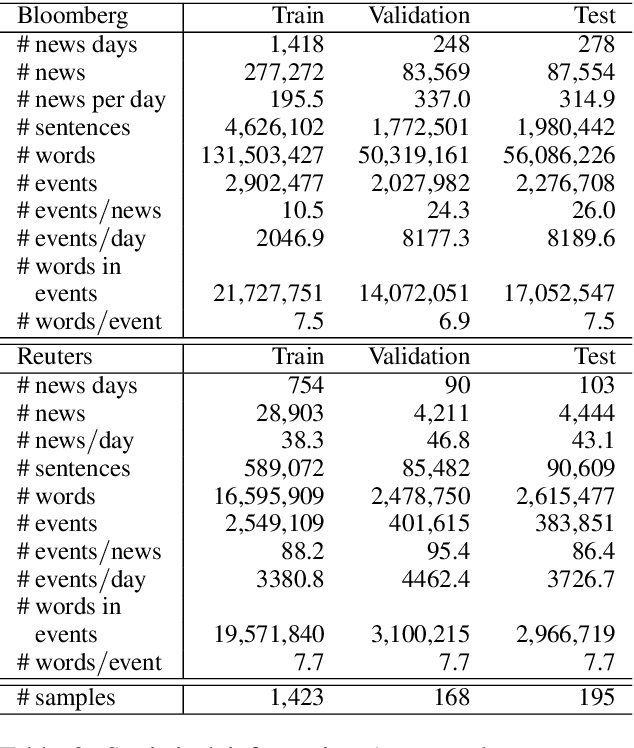
It is reported that financial news, especially financial events expressed in news, provide information to investors' long/short decisions and influence the movements of stock markets. Motivated by this, we leverage financial event streams to train a classification neural network that detects latent event-stock linkages and stock markets' systematic behaviours in the U.S. stock market. Our proposed pipeline includes (1) a combined event extraction method that utilizes Open Information Extraction and neural co-reference resolution, (2) a BERT/ALBERT enhanced representation of events, and (3) an extended hierarchical attention network that includes attentions on event, news and temporal levels. Our pipeline achieves significantly better accuracies and higher simulated annualized returns than state-of-the-art models when being applied to predicting Standard\&Poor 500, Dow Jones, Nasdaq indices and 10 individual stocks.
Playing 20 Question Game with Policy-Based Reinforcement Learning
Aug 26, 2018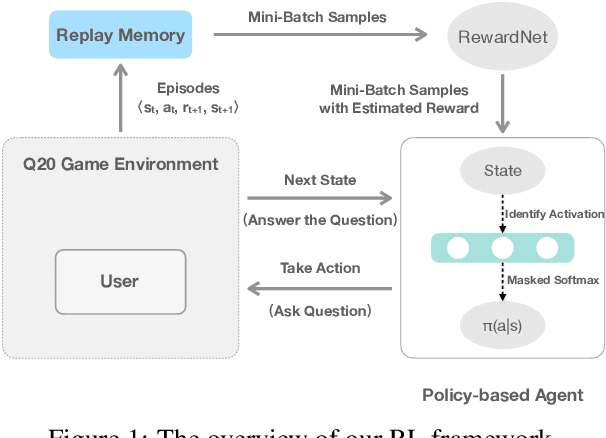

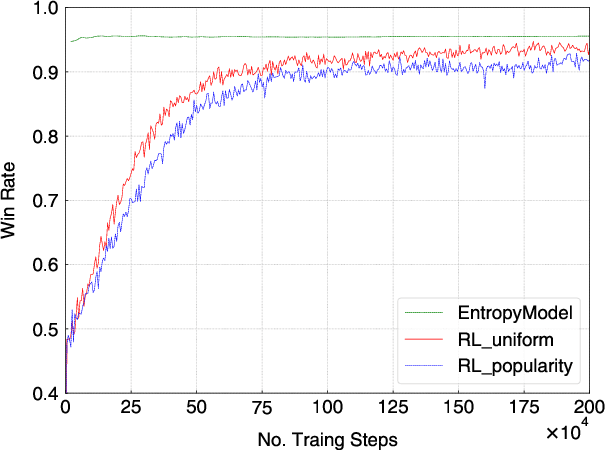
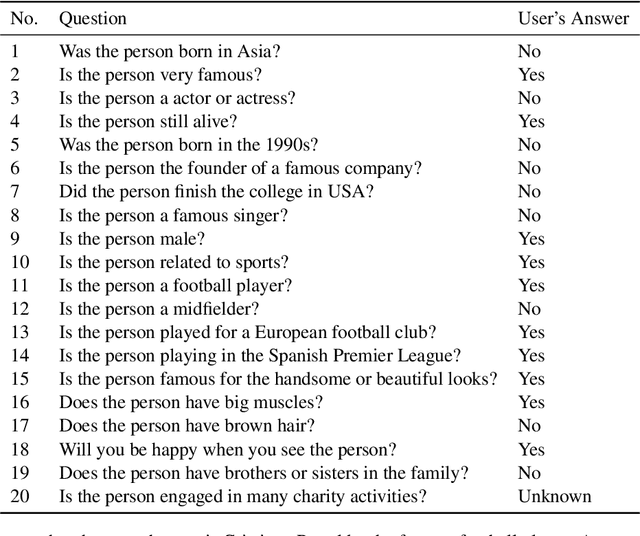
The 20 Questions (Q20) game is a well known game which encourages deductive reasoning and creativity. In the game, the answerer first thinks of an object such as a famous person or a kind of animal. Then the questioner tries to guess the object by asking 20 questions. In a Q20 game system, the user is considered as the answerer while the system itself acts as the questioner which requires a good strategy of question selection to figure out the correct object and win the game. However, the optimal policy of question selection is hard to be derived due to the complexity and volatility of the game environment. In this paper, we propose a novel policy-based Reinforcement Learning (RL) method, which enables the questioner agent to learn the optimal policy of question selection through continuous interactions with users. To facilitate training, we also propose to use a reward network to estimate the more informative reward. Compared to previous methods, our RL method is robust to noisy answers and does not rely on the Knowledge Base of objects. Experimental results show that our RL method clearly outperforms an entropy-based engineering system and has competitive performance in a noisy-free simulation environment.