 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Generation of Streamable Talking Portrait Video with Reference-Guided Deep Compression VAEs
Jun 01, 2026Video diffusion models have significantly advanced portrait video generation, yet their high computational demands limit their use in interactive applications. This work presents a framework for streamable talking portrait video generation conditioned on speech audio and reference images. Designed meticulously for streaming scenarios, it features a causal video VAE for deep latent compression and an autoregressive latent denoising model. Our causal VAE integrates a variable number of reference images as guidance, allowing the network to focus on dynamic information rather than static appearance, thereby enhancing compression efficacy and reconstruction quality. Additionally, we extend the residual auto-encoding paradigm to improve spatial-temporal causality handling in our VAE. The generator is based on a Rectified Flow Transformer architecture and produces video latents in a blockwise auto-regressive manner. Our method enables the real-time generation of high-quality talking portrait videos, achieving speeds significantly faster than baseline models. Furthermore, comprehensive experiments demonstrate that it is on par with or even outperforms these large models in realism, vividness, and video quality.
MotionScape: A Large-Scale Real-World Highly Dynamic UAV Video Dataset for World Models
Apr 09, 2026Recent advances in world models have demonstrated strong capabilities in simulating physical reality, making them an increasingly important foundation for embodied intelligence. For UAV agents in particular, accurate prediction of complex 3D dynamics is essential for autonomous navigation and robust decision-making in unconstrained environments. However, under the highly dynamic camera trajectories typical of UAV views, existing world models often struggle to maintain spatiotemporal physical consistency. A key reason lies in the distribution bias of current training data: most existing datasets exhibit restricted 2.5D motion patterns, such as ground-constrained autonomous driving scenes or relatively smooth human-centric egocentric videos, and therefore lack realistic high-dynamic 6-DoF UAV motion priors. To address this gap, we present MotionScape, a large-scale real-world UAV-view video dataset with highly dynamic motion for world modeling. MotionScape contains over 30 hours of 4K UAV-view videos, totaling more than 4.5M frames. This novel dataset features semantically and geometrically aligned training samples, where diverse real-world UAV videos are tightly coupled with accurate 6-DoF camera trajectories and fine-grained natural language descriptions. To build the dataset, we develop an automated multi-stage processing pipeline that integrates CLIP-based relevance filtering, temporal segmentation, robust visual SLAM for trajectory recovery, and large-language-model-driven semantic annotation. Extensive experiments show that incorporating such semantically and geometrically aligned annotations effectively improves the ability of existing world models to simulate complex 3D dynamics and handle large viewpoint shifts, thereby benefiting decision-making and planning for UAV agents in complex environments. The dataset is publicly available at https://github.com/Thelegendzz/MotionScape
AutoMoT: A Unified Vision-Language-Action Model with Asynchronous Mixture-of-Transformers for End-to-End Autonomous Driving
Mar 16, 2026Integrating vision-language models (VLMs) into end-to-end (E2E) autonomous driving (AD) systems has shown promise in improving scene understanding. However, existing integration strategies suffer from several limitations: they either struggle to resolve distribution misalignment between reasoning and action spaces, underexploit the general reasoning capabilities of pretrained VLMs, or incur substantial inference latency during action policy generation, which degrades driving performance. To address these challenges, we propose \OURS in this work, an end-to-end AD framework that unifies reasoning and action generation within a single vision-language-action (VLA) model. Our approach leverages a mixture-of-transformer (MoT) architecture with joint attention sharing, which preserves the general reasoning capabilities of pre-trained VLMs while enabling efficient fast-slow inference through asynchronous execution at different task frequencies. Extensive experiments on multiple benchmarks, under both open- and closed-loop settings, demonstrate that \OURS achieves competitive performance compared to state-of-the-art methods. We further investigate the functional boundary of pre-trained VLMs in AD, examining when AD-tailored fine-tuning is necessary. Our results show that pre-trained VLMs can achieve competitive multi-task scene understanding performance through semantic prompting alone, while fine-tuning remains essential for action-level tasks such as decision-making and trajectory planning. We refer to \href{https://automot-website.github.io/}{Project Page} for the demonstration videos and qualitative results.
RAPTOR: Real-Time High-Resolution UAV Video Prediction with Efficient Video Attention
Dec 25, 2025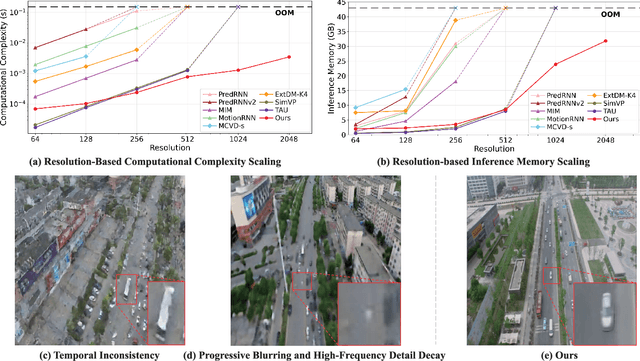



Video prediction is plagued by a fundamental trilemma: achieving high-resolution and perceptual quality typically comes at the cost of real-time speed, hindering its use in latency-critical applications. This challenge is most acute for autonomous UAVs in dense urban environments, where foreseeing events from high-resolution imagery is non-negotiable for safety. Existing methods, reliant on iterative generation (diffusion, autoregressive models) or quadratic-complexity attention, fail to meet these stringent demands on edge hardware. To break this long-standing trade-off, we introduce RAPTOR, a video prediction architecture that achieves real-time, high-resolution performance. RAPTOR's single-pass design avoids the error accumulation and latency of iterative approaches. Its core innovation is Efficient Video Attention (EVA), a novel translator module that factorizes spatiotemporal modeling. Instead of processing flattened spacetime tokens with $O((ST)^2)$ or $O(ST)$ complexity, EVA alternates operations along the spatial (S) and temporal (T) axes. This factorization reduces the time complexity to $O(S + T)$ and memory complexity to $O(max(S, T))$, enabling global context modeling at $512^2$ resolution and beyond, operating directly on dense feature maps with a patch-free design. Complementing this architecture is a 3-stage training curriculum that progressively refines predictions from coarse structure to sharp, temporally coherent details. Experiments show RAPTOR is the first predictor to exceed 30 FPS on a Jetson AGX Orin for $512^2$ video, setting a new state-of-the-art on UAVid, KTH, and a custom high-resolution dataset in PSNR, SSIM, and LPIPS. Critically, RAPTOR boosts the mission success rate in a real-world UAV navigation task by 18/%, paving the way for safer and more anticipatory embodied agents.
Towards Economical Inference: Enabling DeepSeek's Multi-Head Latent Attention in Any Transformer-based LLMs
Feb 20, 2025Multi-head Latent Attention (MLA) is an innovative architecture proposed by DeepSeek, designed to ensure efficient and economical inference by significantly compressing the Key-Value (KV) cache into a latent vector. Compared to MLA, standard LLMs employing Multi-Head Attention (MHA) and its variants such as Grouped-Query Attention (GQA) exhibit significant cost disadvantages. Enabling well-trained LLMs (e.g., Llama) to rapidly adapt to MLA without pre-training from scratch is both meaningful and challenging. This paper proposes the first data-efficient fine-tuning method for transitioning from MHA to MLA (MHA2MLA), which includes two key components: for partial-RoPE, we remove RoPE from dimensions of queries and keys that contribute less to the attention scores, for low-rank approximation, we introduce joint SVD approximations based on the pre-trained parameters of keys and values. These carefully designed strategies enable MHA2MLA to recover performance using only a small fraction (0.3% to 0.6%) of the data, significantly reducing inference costs while seamlessly integrating with compression techniques such as KV cache quantization. For example, the KV cache size of Llama2-7B is reduced by 92.19%, with only a 0.5% drop in LongBench performance.
UNetMamba: An Efficient UNet-Like Mamba for Semantic Segmentation of High-Resolution Remote Sensing Images
Aug 26, 2024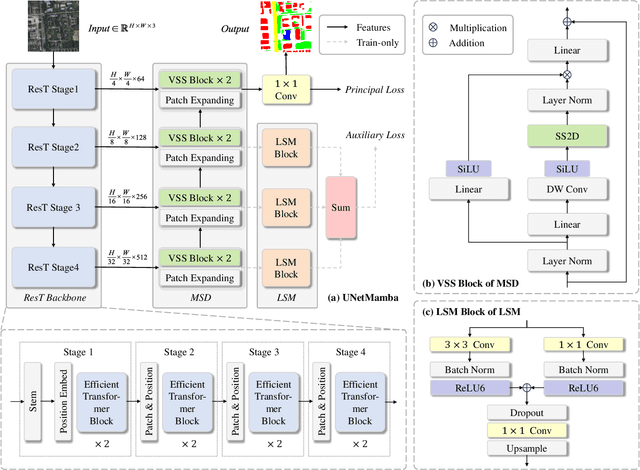
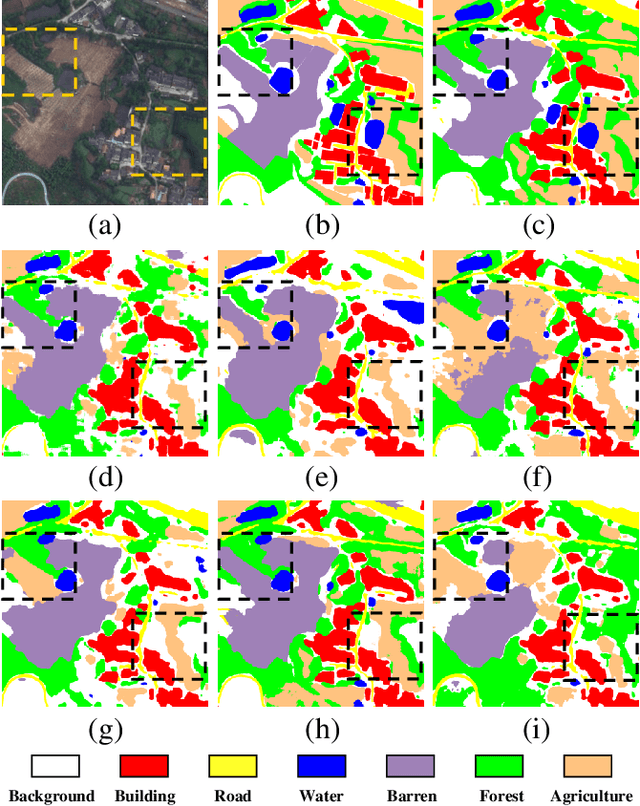


Semantic segmentation of high-resolution remote sensing images is vital in downstream applications such as land-cover mapping, urban planning and disaster assessment.Existing Transformer-based methods suffer from the constraint between accuracy and efficiency, while the recently proposed Mamba is renowned for being efficient. Therefore, to overcome the dilemma, we propose UNetMamba, a UNet-like semantic segmentation model based on Mamba. It incorporates a mamba segmentation decoder (MSD) that can efficiently decode the complex information within high-resolution images, and a local supervision module (LSM), which is train-only but can significantly enhance the perception of local contents. Extensive experiments demonstrate that UNetMamba outperforms the state-of-the-art methods with mIoU increased by 0.87% on LoveDA and 0.36% on ISPRS Vaihingen, while achieving high efficiency through the lightweight design, less memory footprint and reduced computational cost. The source code is available at https://github.com/EnzeZhu2001/UNetMamba.
UNetMamba: Efficient UNet-Like Mamba for Semantic Segmentation of High-Resolution Remote Sensing Images
Aug 21, 2024The semantic segmentation of high-resolution remote sensing images plays a crucial role in downstream applications such as urban planning and disaster assessment. However, existing Transformer-based methods suffer from the constraint between accuracy and efficiency. To overcome this dilemma, we propose UNetMamba, a novel Mamba-based semantic segmentation model. It incorporates a Mamba Segmentation Decoder (MSD) that can efficiently decode the complex information within high-resolution images, and a Local Supervision Module (LSM), which is train-only but can significantly enhance the perception of local contents. Extensive experiments demonstrate that UNet-Mamba outperforms the state-of-the-art methods with the mIoU increased by 0.87% on LoveDA and 0.36% on ISPRS Vaihingen, while achieving high efficiency through light weight, low memory footprint and low computational cost. The source code will soon be publicly available at https://github.com/EnzeZhu2001/UNetMamba.
Secrets of RLHF in Large Language Models Part II: Reward Modeling
Jan 12, 2024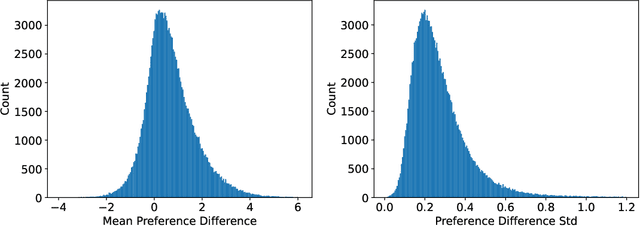

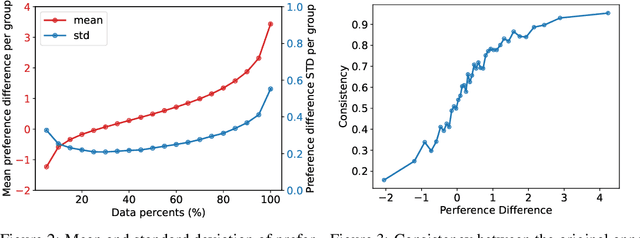
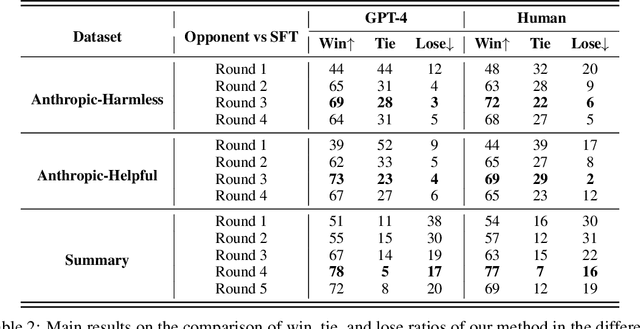
Reinforcement Learning from Human Feedback (RLHF) has become a crucial technology for aligning language models with human values and intentions, enabling models to produce more helpful and harmless responses. Reward models are trained as proxies for human preferences to drive reinforcement learning optimization. While reward models are often considered central to achieving high performance, they face the following challenges in practical applications: (1) Incorrect and ambiguous preference pairs in the dataset may hinder the reward model from accurately capturing human intent. (2) Reward models trained on data from a specific distribution often struggle to generalize to examples outside that distribution and are not suitable for iterative RLHF training. In this report, we attempt to address these two issues. (1) From a data perspective, we propose a method to measure the strength of preferences within the data, based on a voting mechanism of multiple reward models. Experimental results confirm that data with varying preference strengths have different impacts on reward model performance. We introduce a series of novel methods to mitigate the influence of incorrect and ambiguous preferences in the dataset and fully leverage high-quality preference data. (2) From an algorithmic standpoint, we introduce contrastive learning to enhance the ability of reward models to distinguish between chosen and rejected responses, thereby improving model generalization. Furthermore, we employ meta-learning to enable the reward model to maintain the ability to differentiate subtle differences in out-of-distribution samples, and this approach can be utilized for iterative RLHF optimization.
HeightFormer: A Multilevel Interaction and Image-adaptive Classification-regression Network for Monocular Height Estimation with Aerial Images
Oct 12, 2023



Height estimation has long been a pivotal topic within measurement and remote sensing disciplines, proving critical for endeavours such as 3D urban modelling, MR and autonomous driving. Traditional methods utilise stereo matching or multisensor fusion, both well-established techniques that typically necessitate multiple images from varying perspectives and adjunct sensors like SAR, leading to substantial deployment costs. Single image height estimation has emerged as an attractive alternative, boasting a larger data source variety and simpler deployment. However, current methods suffer from limitations such as fixed receptive fields, a lack of global information interaction, leading to noticeable instance-level height deviations. The inherent complexity of height prediction can result in a blurry estimation of object edge depth when using mainstream regression methods based on fixed height division. This paper presents a comprehensive solution for monocular height estimation in remote sensing, termed HeightFormer, combining multilevel interactions and image-adaptive classification-regression. It features the Multilevel Interaction Backbone (MIB) and Image-adaptive Classification-regression Height Generator (ICG). MIB supplements the fixed sample grid in CNN of the conventional backbone network with tokens of different interaction ranges. It is complemented by a pixel-, patch-, and feature map-level hierarchical interaction mechanism, designed to relay spatial geometry information across different scales and introducing a global receptive field to enhance the quality of instance-level height estimation. The ICG dynamically generates height partition for each image and reframes the traditional regression task, using a refinement from coarse to fine classification-regression that significantly mitigates the innate ill-posedness issue and drastically improves edge sharpness.
HVDetFusion: A Simple and Robust Camera-Radar Fusion Framework
Jul 21, 2023



In the field of autonomous driving, 3D object detection is a very important perception module. Although the current SOTA algorithm combines Camera and Lidar sensors, limited by the high price of Lidar, the current mainstream landing schemes are pure Camera sensors or Camera+Radar sensors. In this study, we propose a new detection algorithm called HVDetFusion, which is a multi-modal detection algorithm that not only supports pure camera data as input for detection, but also can perform fusion input of radar data and camera data. The camera stream does not depend on the input of Radar data, thus addressing the downside of previous methods. In the pure camera stream, we modify the framework of Bevdet4D for better perception and more efficient inference, and this stream has the whole 3D detection output. Further, to incorporate the benefits of Radar signals, we use the prior information of different object positions to filter the false positive information of the original radar data, according to the positioning information and radial velocity information recorded by the radar sensors to supplement and fuse the BEV features generated by the original camera data, and the effect is further improved in the process of fusion training. Finally, HVDetFusion achieves the new state-of-the-art 67.4\% NDS on the challenging nuScenes test set among all camera-radar 3D object detectors. The code is available at https://github.com/HVXLab/HVDetFusion