 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHVDetFusion: A Simple and Robust Camera-Radar Fusion Framework
Jul 21, 2023



In the field of autonomous driving, 3D object detection is a very important perception module. Although the current SOTA algorithm combines Camera and Lidar sensors, limited by the high price of Lidar, the current mainstream landing schemes are pure Camera sensors or Camera+Radar sensors. In this study, we propose a new detection algorithm called HVDetFusion, which is a multi-modal detection algorithm that not only supports pure camera data as input for detection, but also can perform fusion input of radar data and camera data. The camera stream does not depend on the input of Radar data, thus addressing the downside of previous methods. In the pure camera stream, we modify the framework of Bevdet4D for better perception and more efficient inference, and this stream has the whole 3D detection output. Further, to incorporate the benefits of Radar signals, we use the prior information of different object positions to filter the false positive information of the original radar data, according to the positioning information and radial velocity information recorded by the radar sensors to supplement and fuse the BEV features generated by the original camera data, and the effect is further improved in the process of fusion training. Finally, HVDetFusion achieves the new state-of-the-art 67.4\% NDS on the challenging nuScenes test set among all camera-radar 3D object detectors. The code is available at https://github.com/HVXLab/HVDetFusion
Data-driven Smart Ponzi Scheme Detection
Aug 20, 2021A smart Ponzi scheme is a new form of economic crime that uses Ethereum smart contract account and cryptocurrency to implement Ponzi scheme. The smart Ponzi scheme has harmed the interests of many investors, but researches on smart Ponzi scheme detection is still very limited. The existing smart Ponzi scheme detection methods have the problems of requiring many human resources in feature engineering and poor model portability. To solve these problems, we propose a data-driven smart Ponzi scheme detection system in this paper. The system uses dynamic graph embedding technology to automatically learn the representation of an account based on multi-source and multi-modal data related to account transactions. Compared with traditional methods, the proposed system requires very limited human-computer interaction. To the best of our knowledge, this is the first work to implement smart Ponzi scheme detection through dynamic graph embedding. Experimental results show that this method is significantly better than the existing smart Ponzi scheme detection methods.
Relabel the Noise: Joint Extraction of Entities and Relations via Cooperative Multiagents
Apr 21, 2020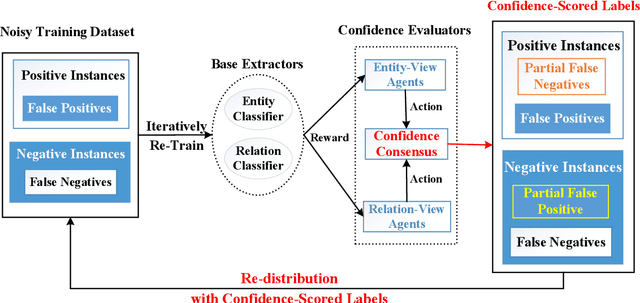
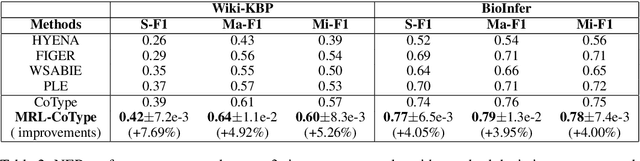
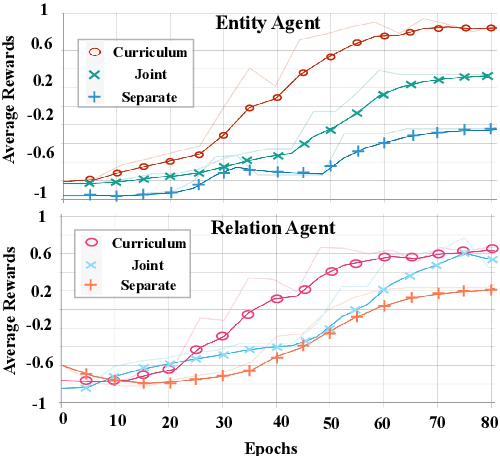
Distant supervision based methods for entity and relation extraction have received increasing popularity due to the fact that these methods require light human annotation efforts. In this paper, we consider the problem of \textit{shifted label distribution}, which is caused by the inconsistency between the noisy-labeled training set subject to external knowledge graph and the human-annotated test set, and exacerbated by the pipelined entity-then-relation extraction manner with noise propagation. We propose a joint extraction approach to address this problem by re-labeling noisy instances with a group of cooperative multiagents. To handle noisy instances in a fine-grained manner, each agent in the cooperative group evaluates the instance by calculating a continuous confidence score from its own perspective; To leverage the correlations between these two extraction tasks, a confidence consensus module is designed to gather the wisdom of all agents and re-distribute the noisy training set with confidence-scored labels. Further, the confidences are used to adjust the training losses of extractors. Experimental results on two real-world datasets verify the benefits of re-labeling noisy instance, and show that the proposed model significantly outperforms the state-of-the-art entity and relation extraction methods.
Exploring and Distilling Cross-Modal Information for Image Captioning
Mar 15, 2020
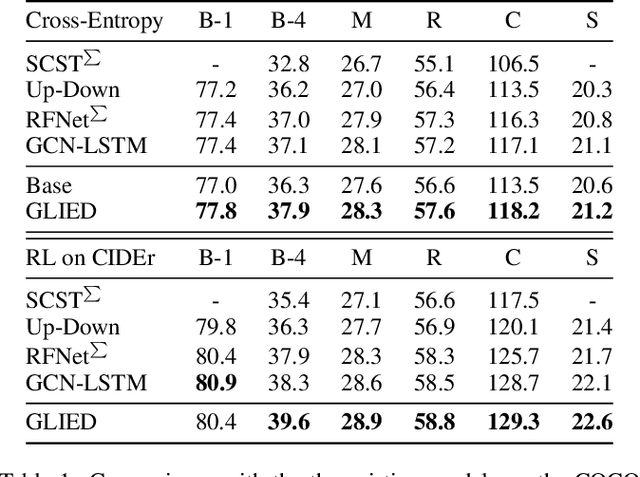
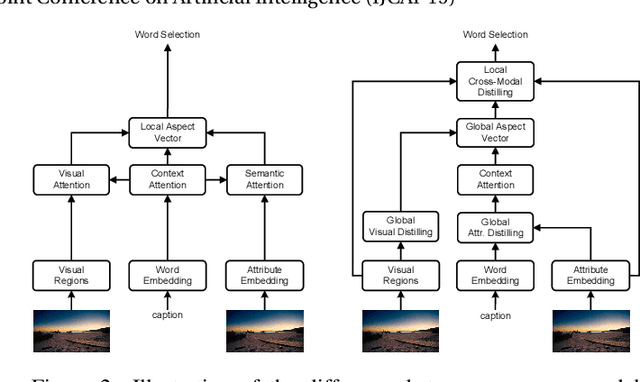
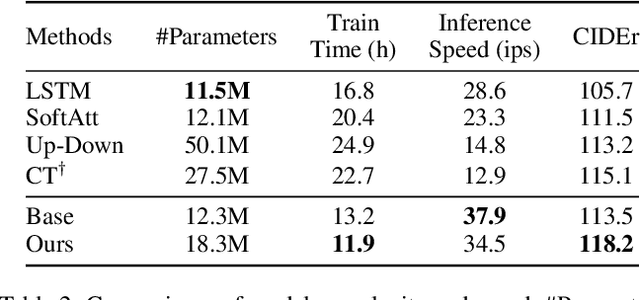
Recently, attention-based encoder-decoder models have been used extensively in image captioning. Yet there is still great difficulty for the current methods to achieve deep image understanding. In this work, we argue that such understanding requires visual attention to correlated image regions and semantic attention to coherent attributes of interest. Based on the Transformer, to perform effective attention, we explore image captioning from a cross-modal perspective and propose the Global-and-Local Information Exploring-and-Distilling approach that explores and distills the source information in vision and language. It globally provides the aspect vector, a spatial and relational representation of images based on caption contexts, through the extraction of salient region groupings and attribute collocations, and locally extracts the fine-grained regions and attributes in reference to the aspect vector for word selection. Our Transformer-based model achieves a CIDEr score of 129.3 in offline COCO evaluation on the COCO testing set with remarkable efficiency in terms of accuracy, speed, and parameter budget.
Aligning Visual Regions and Textual Concepts: Learning Fine-Grained Image Representations for Image Captioning
May 26, 2019
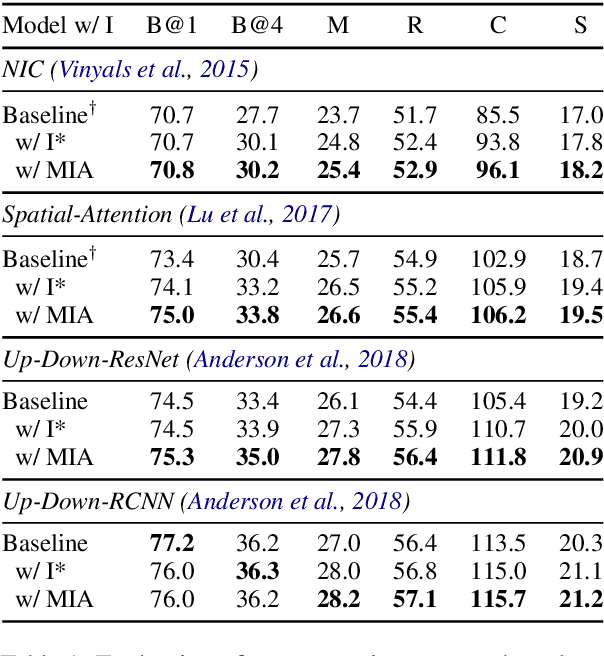
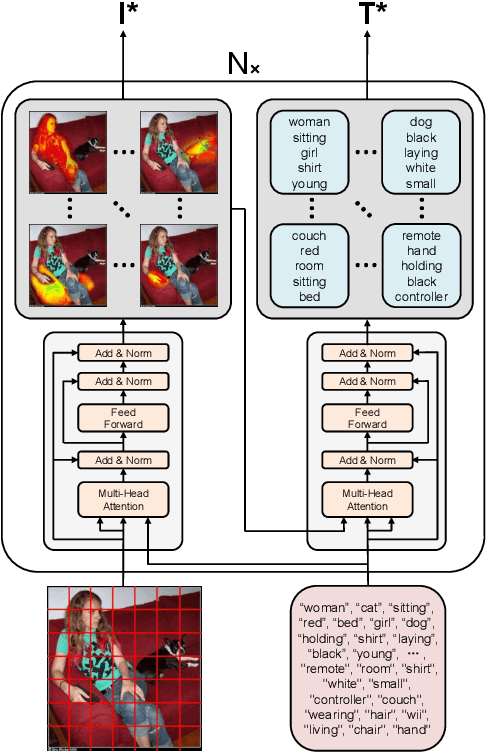
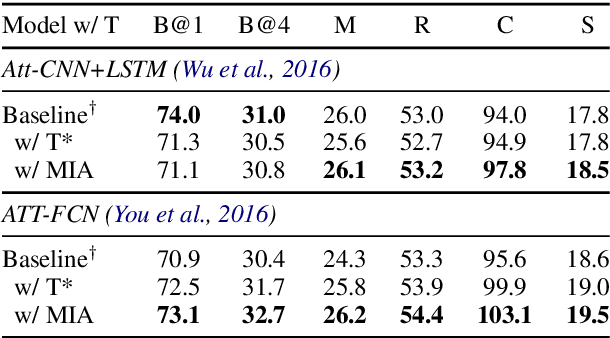
In image-grounded text generation, fine-grained representations of the image are considered to be of paramount importance. Most of the current systems incorporate visual features and textual concepts as a sketch of an image. However, plainly inferred representations are usually undesirable in that they are composed of separate components, the relations of which are elusive. In this work, we aim at representing an image with a set of integrated visual regions and corresponding textual concepts. To this end, we build the Mutual Iterative Attention (MIA) module, which integrates correlated visual features and textual concepts, respectively, by aligning the two modalities. We evaluate the proposed approach on the COCO dataset for image captioning. Extensive experiments show that the refined image representations boost the baseline models by up to 12% in terms of CIDEr, demonstrating that our method is effective and generalizes well to a wide range of models.
GCN-GAN: A Non-linear Temporal Link Prediction Model for Weighted Dynamic Networks
Jan 26, 2019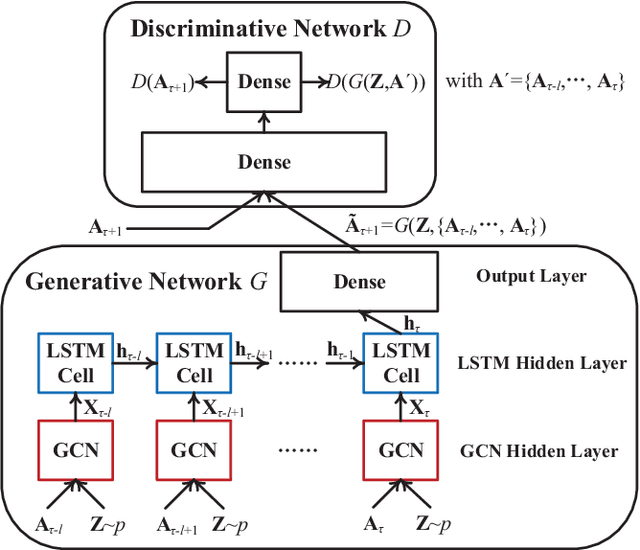
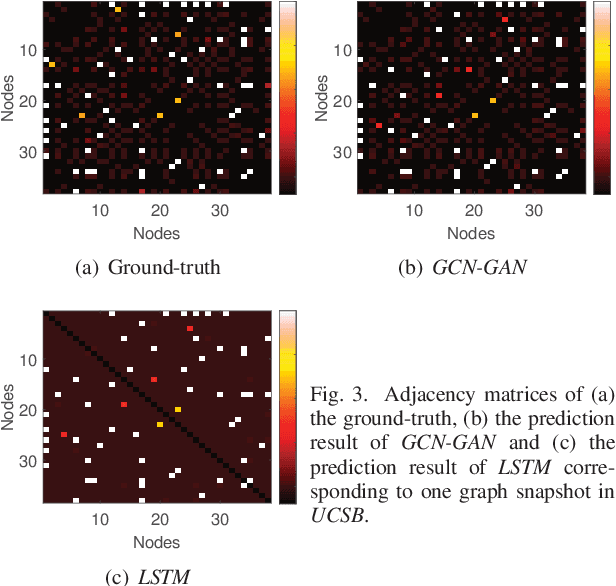

In this paper, we generally formulate the dynamics prediction problem of various network systems (e.g., the prediction of mobility, traffic and topology) as the temporal link prediction task. Different from conventional techniques of temporal link prediction that ignore the potential non-linear characteristics and the informative link weights in the dynamic network, we introduce a novel non-linear model GCN-GAN to tackle the challenging temporal link prediction task of weighted dynamic networks. The proposed model leverages the benefits of the graph convolutional network (GCN), long short-term memory (LSTM) as well as the generative adversarial network (GAN). Thus, the dynamics, topology structure and evolutionary patterns of weighted dynamic networks can be fully exploited to improve the temporal link prediction performance. Concretely, we first utilize GCN to explore the local topological characteristics of each single snapshot and then employ LSTM to characterize the evolving features of the dynamic networks. Moreover, GAN is used to enhance the ability of the model to generate the next weighted network snapshot, which can effectively tackle the sparsity and the wide-value-range problem of edge weights in real-life dynamic networks. To verify the model's effectiveness, we conduct extensive experiments on four datasets of different network systems and application scenarios. The experimental results demonstrate that our model achieves impressive results compared to the state-of-the-art competitors.
Multi-Task Learning with Multi-View Attention for Answer Selection and Knowledge Base Question Answering
Dec 06, 2018
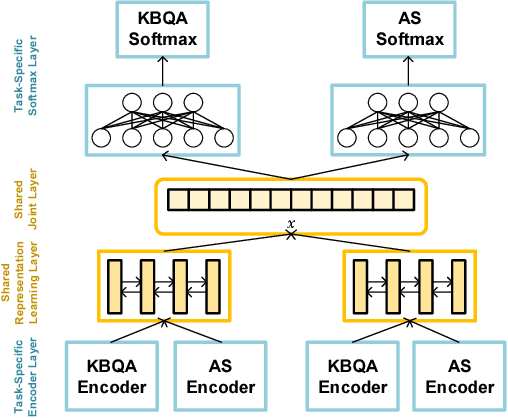
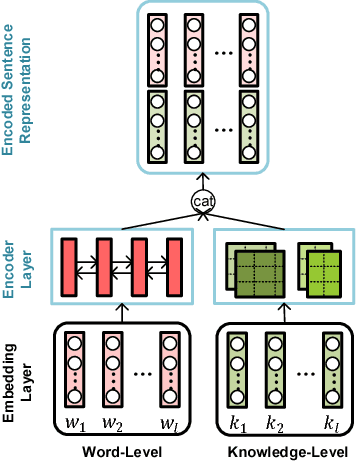

Answer selection and knowledge base question answering (KBQA) are two important tasks of question answering (QA) systems. Existing methods solve these two tasks separately, which requires large number of repetitive work and neglects the rich correlation information between tasks. In this paper, we tackle answer selection and KBQA tasks simultaneously via multi-task learning (MTL), motivated by the following motivations. First, both answer selection and KBQA can be regarded as a ranking problem, with one at text-level while the other at knowledge-level. Second, these two tasks can benefit each other: answer selection can incorporate the external knowledge from knowledge base (KB), while KBQA can be improved by learning contextual information from answer selection. To fulfill the goal of jointly learning these two tasks, we propose a novel multi-task learning scheme that utilizes multi-view attention learned from various perspectives to enable these tasks to interact with each other as well as learn more comprehensive sentence representations. The experiments conducted on several real-world datasets demonstrate the effectiveness of the proposed method, and the performance of answer selection and KBQA is improved. Also, the multi-view attention scheme is proved to be effective in assembling attentive information from different representational perspectives.
A Knowledge Graph Based Solution for Entity Discovery and Linking in Open-Domain Questions
Dec 05, 2018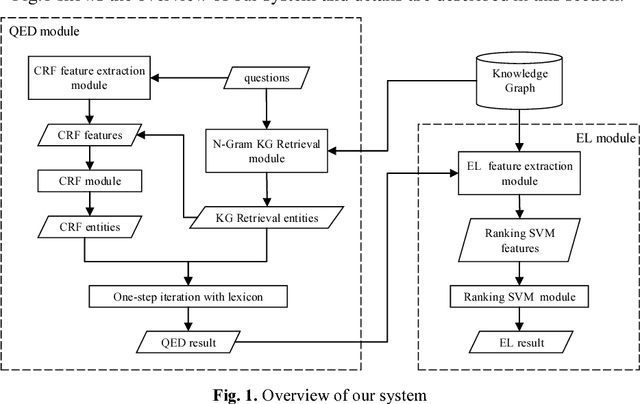

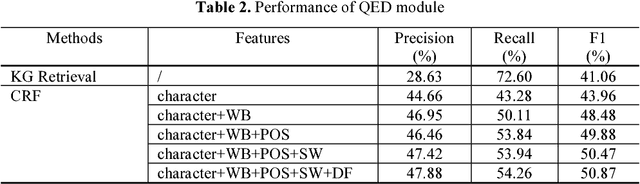
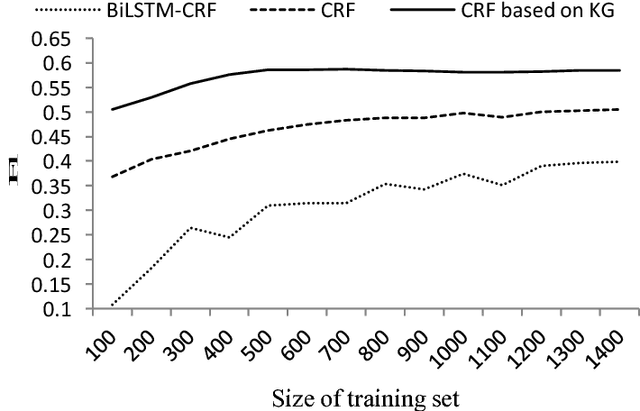
Named entity discovery and linking is the fundamental and core component of question answering. In Question Entity Discovery and Linking (QEDL) problem, traditional methods are challenged because multiple entities in one short question are difficult to be discovered entirely and the incomplete information in short text makes entity linking hard to implement. To overcome these difficulties, we proposed a knowledge graph based solution for QEDL and developed a system consists of Question Entity Discovery (QED) module and Entity Linking (EL) module. The method of QED module is a tradeoff and ensemble of two methods. One is the method based on knowledge graph retrieval, which could extract more entities in questions and guarantee the recall rate, the other is the method based on Conditional Random Field (CRF), which improves the precision rate. The EL module is treated as a ranking problem and Learning to Rank (LTR) method with features such as semantic similarity, text similarity and entity popularity is utilized to extract and make full use of the information in short texts. On the official dataset of a shared QEDL evaluation task, our approach could obtain 64.44% F1 score of QED and 64.86% accuracy of EL, which ranks the 2nd place and indicates its practical use for QEDL problem.
Improving Medical Short Text Classification with Semantic Expansion Using Word-Cluster Embedding
Dec 05, 2018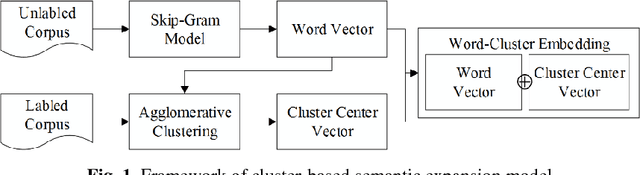
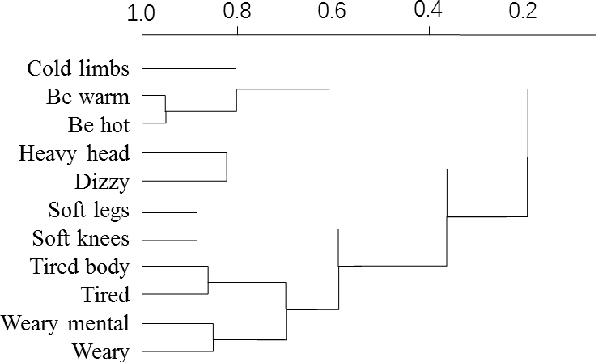
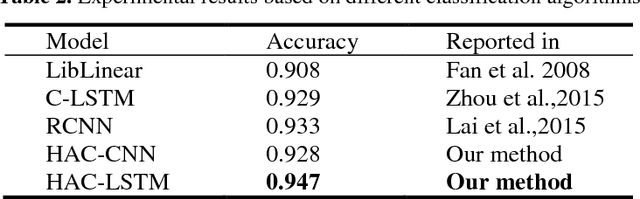
Automatic text classification (TC) research can be used for real-world problems such as the classification of in-patient discharge summaries and medical text reports, which is beneficial to make medical documents more understandable to doctors. However, in electronic medical records (EMR), the texts containing sentences are shorter than that in general domain, which leads to the lack of semantic features and the ambiguity of semantic. To tackle this challenge, we propose to add word-cluster embedding to deep neural network for improving short text classification. Concretely, we first use hierarchical agglomerative clustering to cluster the word vectors in the semantic space. Then we calculate the cluster center vector which represents the implicit topic information of words in the cluster. Finally, we expand word vector with cluster center vector, and implement classifiers using CNN and LSTM respectively. To evaluate the performance of our proposed method, we conduct experiments on public data sets TREC and the medical short sentences data sets which is constructed and released by us. The experimental results demonstrate that our proposed method outperforms state-of-the-art baselines in short sentence classification on both medical domain and general domain.
MedSim: A Novel Semantic Similarity Measure in Bio-medical Knowledge Graphs
Dec 05, 2018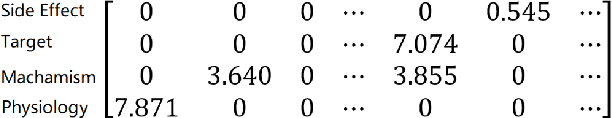
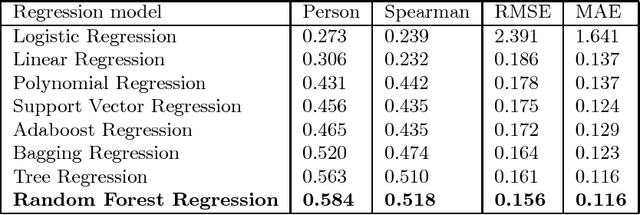
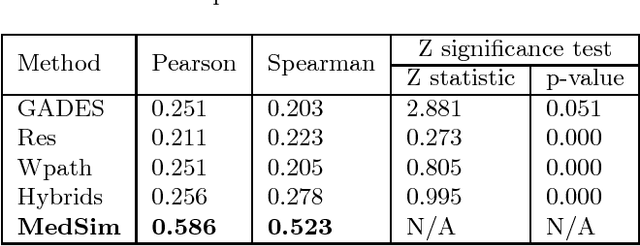

We present MedSim, a novel semantic SIMilarity method based on public well-established bio-MEDical knowledge graphs (KGs) and large-scale corpus, to study the therapeutic substitution of antibiotics. Besides hierarchy and corpus of KGs, MedSim further interprets medicine characteristics by constructing multi-dimensional medicine-specific feature vectors. Dataset of 528 antibiotic pairs scored by doctors is applied for evaluation and MedSim has produced statistically significant improvement over other semantic similarity methods. Furthermore, some promising applications of MedSim in drug substitution and drug abuse prevention are presented in case study.